

python爬虫抓取的数据转换成 PDF

本文给大家分享的是使用python爬虫实现把《廖雪峰的 Python 教程》转换成PDF的方法和代码,有需要的小伙伴可以参考下
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天就琢磨着写一个爬虫,将廖雪峰的 Python 教程 爬下来做成 PDF 电子书方便大家离线阅读。
开始写爬虫前,我们先来分析一下该网站1的页面结构,网页的左侧是教程的目录大纲,每个 URL 对应到右边的一篇文章,右侧上方是文章的标题,中间是文章的正文部分,正文内容是我们关心的重点,我们要爬的数据就是所有网页的正文部分,下方是用户的评论区,评论区对我们没什么用,所以可以忽略它。
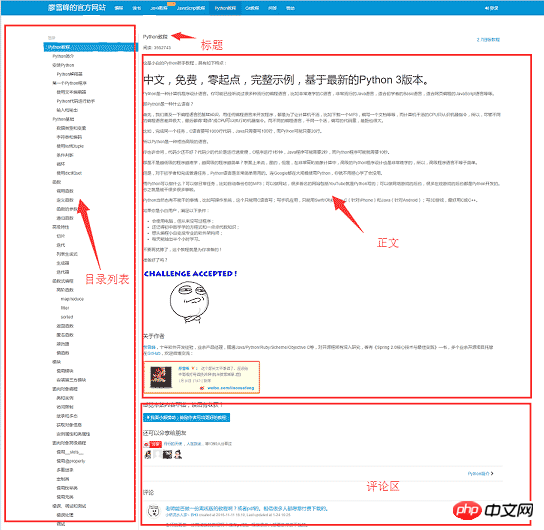
工具准备
弄清楚了网站的基本结构后就可以开始准备爬虫所依赖的工具包了。requests、beautifulsoup 是爬虫两大神器,reuqests 用于网络请求,beautifusoup 用于操作 html 数据。有了这两把梭子,干起活来利索,scrapy 这样的爬虫框架我们就不用了,小程序派上它有点杀鸡用牛刀的意思。此外,既然是把 html 文件转为 pdf,那么也要有相应的库支持, wkhtmltopdf 就是一个非常好的工具,它可以用适用于多平台的 html 到 pdf 的转换,pdfkit 是 wkhtmltopdf 的Python封装包。首先安装好下面的依赖包,
接着安装 wkhtmltopdf
pip install requests pip install beautifulsoup pip install pdfkit
安装 wkhtmltopdf
Windows平台直接在 wkhtmltopdf 官网2下载稳定版的进行安装,安装完成之后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”。Ubuntu 和 CentOS 可以直接用命令行进行安装
$ sudo apt-get install wkhtmltopdf # ubuntu $ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后就可以上代码了,不过写代码之前还是先整理一下思绪。程序的目的是要把所有 URL 对应的 html 正文部分保存到本地,然后利用 pdfkit 把这些文件转换成一个 pdf 文件。我们把任务拆分一下,首先是把某一个 URL 对应的 html 正文保存到本地,然后找到所有的 URL 执行相同的操作。
用 Chrome 浏览器找到页面正文部分的标签,按 F12 找到正文对应的 p 标签: <p >,该 p 是网页的正文内容。用 requests 把整个页面加载到本地后,就可以使用 beautifulsoup 操作 HTML 的 dom 元素 来提取正文内容了。
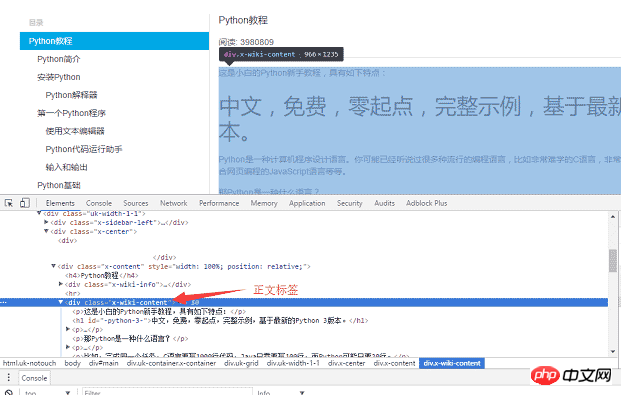
具体的实现代码如下:用 soup.find_all 函数找到正文标签,然后把正文部分的内容保存到 a.html 文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)第二步就是把页面左侧所有 URL 解析出来。采用同样的方式,找到 左侧菜单标签 <ul >
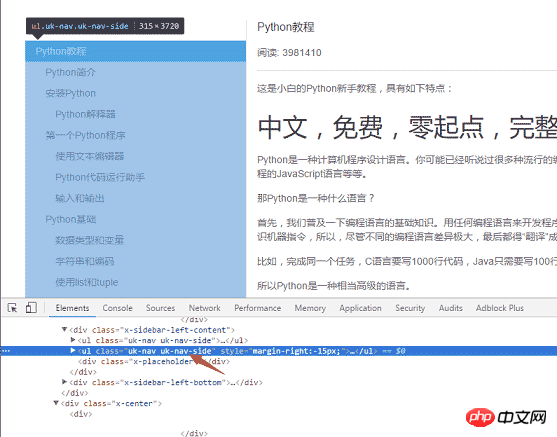
具体代码实现逻辑:因为页面上有两个uk-nav uk-nav-side的 class 属性,而真正的目录列表是第二个。所有的 url 获取了,url 转 html 的函数在第一步也写好了。
def get_url_list():
"""
获取所有URL目录列表
"""
response = requests.get("http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000")
soup = BeautifulSoup(response.content, "html5lib")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls最后一步就是把 html 转换成pdf文件了。转换成 pdf 文件非常简单,因为 pdfkit 把所有的逻辑都封装好了,你只需要调用函数 pdfkit.from_file
def save_pdf(htmls):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options)执行 save_pdf 函数,电子书 pdf 文件就生成了,效果图:
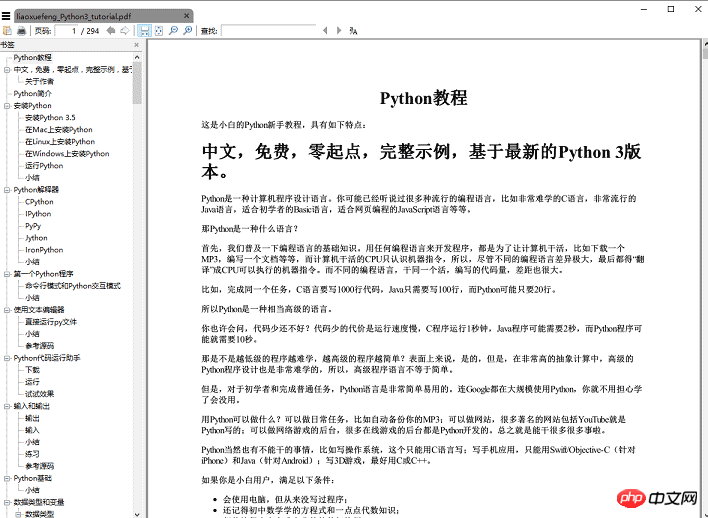
总结
总共代码量加起来不到50行,不过,且慢,其实上面给出的代码省略了一些细节,比如,如何获取文章的标题,正文内容的 img 标签使用的是相对路径,如果要想在 pdf 中正常显示图片就需要将相对路径改为绝对路径,还有保存下来的 html 临时文件都要删除,这些细节末叶都放在github上。
【相关推荐】
1. Python免费视频教程
3. Python学习手册
以上是python爬虫抓取的数据转换成 PDF的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
MySQL 有免费的社区版和收费的企业版。社区版可免费使用和修改,但支持有限,适合稳定性要求不高、技术能力强的应用。企业版提供全面商业支持,适合需要稳定可靠、高性能数据库且愿意为支持买单的应用。选择版本时考虑的因素包括应用关键性、预算和技术技能。没有完美的选项,只有最合适的方案,需根据具体情况谨慎选择。
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 mysql 需要互联网吗
Apr 08, 2025 pm 02:18 PM
mysql 需要互联网吗
Apr 08, 2025 pm 02:18 PM
MySQL 可在无需网络连接的情况下运行,进行基本的数据存储和管理。但是,对于与其他系统交互、远程访问或使用高级功能(如复制和集群)的情况,则需要网络连接。此外,安全措施(如防火墙)、性能优化(选择合适的网络连接)和数据备份对于连接到互联网的 MySQL 数据库至关重要。
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:轻量级、高水平可扩展的Python数据库HadiDB(hadidb)是一个用Python编写的轻量级数据库,具备高度水平的可扩展性。安装HadiDB使用pip安装:pipinstallhadidb用户管理创建用户:createuser()方法创建一个新用户。authentication()方法验证用户身份。fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 mysql workbench 可以连接到 mariadb 吗
Apr 08, 2025 pm 02:33 PM
mysql workbench 可以连接到 mariadb 吗
Apr 08, 2025 pm 02:33 PM
MySQL Workbench 可以连接 MariaDB,前提是配置正确。首先选择 "MariaDB" 作为连接器类型。在连接配置中,正确设置 HOST、PORT、USER、PASSWORD 和 DATABASE。测试连接时,检查 MariaDB 服务是否启动,用户名和密码是否正确,端口号是否正确,防火墙是否允许连接,以及数据库是否存在。高级用法中,使用连接池技术优化性能。常见错误包括权限不足、网络连接问题等,调试错误时仔细分析错误信息和使用调试工具。优化网络配置可以提升性能
 mysql 需要服务器吗
Apr 08, 2025 pm 02:12 PM
mysql 需要服务器吗
Apr 08, 2025 pm 02:12 PM
对于生产环境,通常需要一台服务器来运行 MySQL,原因包括性能、可靠性、安全性和可扩展性。服务器通常拥有更强大的硬件、冗余配置和更严格的安全措施。对于小型、低负载应用,可在本地机器运行 MySQL,但需谨慎考虑资源消耗、安全风险和维护成本。如需更高的可靠性和安全性,应将 MySQL 部署到云服务器或其他服务器上。选择合适的服务器配置需要根据应用负载和数据量进行评估。
