

详解异步代理和代理池的python代码

本文主要介绍了Python实现异步代理爬虫及代理池的相关知识,具有很好的参考价值,下面跟着小编一起来看下吧
使用python asyncio实现了一个异步代理池,根据规则爬取代理网站上的免费代理,在验证其有效后存入redis中,定期扩展代理的数量并检验池中代理的有效性,移除失效的代理。同时用aiohttp实现了一个server,其他的程序可以通过访问相应的url来从代理池中获取代理。
源码
Github
环境
Python 3.5+
Redis
PhantomJS(可选)
Supervisord(可选)
因为代码中大量使用了asyncio的async和await语法,它们是在Python3.5中才提供的,所以最好使用Python3.5及以上的版本,我使用的是Python3.6。
依赖
redis
aiohttp
bs4
lxml
requests
selenium
selenium包主要是用来操作PhantomJS的。
下面来对代码进行说明。
1. 爬虫部分
核心代码
async def start(self):
for rule in self._rules:
parser = asyncio.ensure_future(self._parse_page(rule)) # 根据规则解析页面来获取代理
logger.debug('{0} crawler started'.format(rule.rule_name))
if not rule.use_phantomjs:
await page_download(ProxyCrawler._url_generator(rule), self._pages, self._stop_flag) # 爬取代理网站的页面
else:
await page_download_phantomjs(ProxyCrawler._url_generator(rule), self._pages,
rule.phantomjs_load_flag, self._stop_flag) # 使用PhantomJS爬取
await self._pages.join()
parser.cancel()
logger.debug('{0} crawler finished'.format(rule.rule_name))上面的核心代码实际上是一个用asyncio.Queue实现的生产-消费者模型,下面是该模型的一个简单实现:
import asyncio from random import random async def produce(queue, n): for x in range(1, n + 1): print('produce ', x) await asyncio.sleep(random()) await queue.put(x) # 向queue中放入item async def consume(queue): while 1: item = await queue.get() # 等待从queue中获取item print('consume ', item) await asyncio.sleep(random()) queue.task_done() # 通知queue当前item处理完毕 async def run(n): queue = asyncio.Queue() consumer = asyncio.ensure_future(consume(queue)) await produce(queue, n) # 等待生产者结束 await queue.join() # 阻塞直到queue不为空 consumer.cancel() # 取消消费者任务,否则它会一直阻塞在get方法处 def aio_queue_run(n): loop = asyncio.get_event_loop() try: loop.run_until_complete(run(n)) # 持续运行event loop直到任务run(n)结束 finally: loop.close() if name == 'main': aio_queue_run(5)
运行上面的代码,一种可能的输出如下:
produce 1 produce 2 consume 1 produce 3 produce 4 consume 2 produce 5 consume 3 consume 4 consume 5
爬取页面
async def page_download(urls, pages, flag):
url_generator = urls
async with aiohttp.ClientSession() as session:
for url in url_generator:
if flag.is_set():
break
await asyncio.sleep(uniform(delay - 0.5, delay + 1))
logger.debug('crawling proxy web page {0}'.format(url))
try:
async with session.get(url, headers=headers, timeout=10) as response:
page = await response.text()
parsed = html.fromstring(decode_html(page)) # 使用bs4来辅助lxml解码网页:http://lxml.de/elementsoup.html#Using only the encoding detection
await pages.put(parsed)
url_generator.send(parsed) # 根据当前页面来获取下一页的地址
except StopIteration:
break
except asyncio.TimeoutError:
logger.error('crawling {0} timeout'.format(url))
continue # TODO: use a proxy
except Exception as e:
logger.error(e)使用aiohttp实现的网页爬取函数,大部分代理网站都可以使用上面的方法来爬取,对于使用js动态生成页面的网站可以使用selenium控制PhantomJS来爬取——本项目对爬虫的效率要求不高,代理网站的更新频率是有限的,不需要频繁的爬取,完全可以使用PhantomJS。
解析代理
最简单的莫过于用xpath来解析代理了,使用Chrome浏览器的话,直接通过右键就能获得选中的页面元素的xpath:
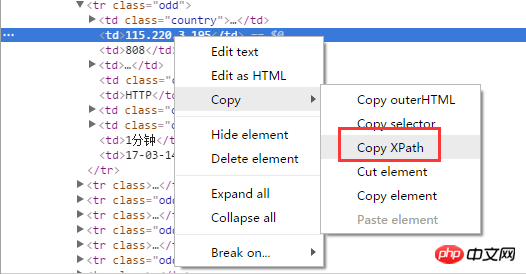
安装Chrome的扩展“XPath Helper”就可以直接在页面上运行和调试xpath,十分方便:
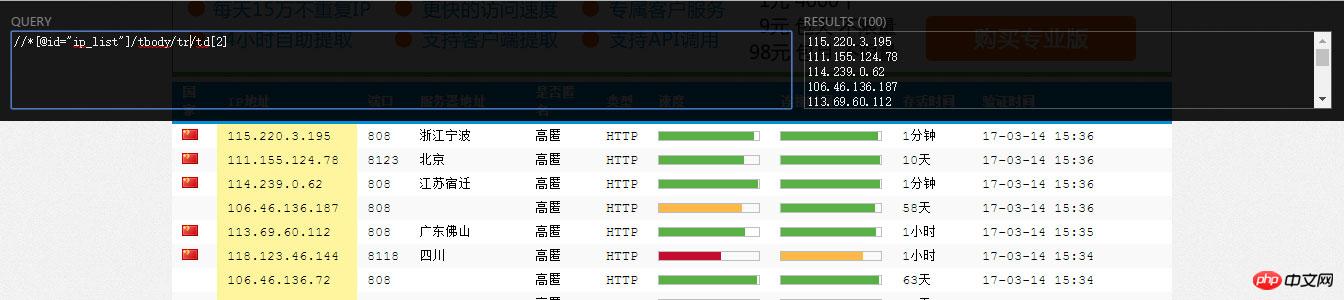
BeautifulSoup不支持xpath,使用lxml来解析页面,代码如下:
async def _parse_proxy(self, rule, page):
ips = page.xpath(rule.ip_xpath) # 根据xpath解析得到list类型的ip地址集合
ports = page.xpath(rule.port_xpath) # 根据xpath解析得到list类型的ip地址集合
if not ips or not ports:
logger.warning('{2} crawler could not get ip(len={0}) or port(len={1}), please check the xpaths or network'.
format(len(ips), len(ports), rule.rule_name))
return
proxies = map(lambda x, y: '{0}:{1}'.format(x.text.strip(), y.text.strip()), ips, ports)
if rule.filters: # 根据过滤字段来过滤代理,如“高匿”、“透明”等
filters = []
for i, ft in enumerate(rule.filters_xpath):
field = page.xpath(ft)
if not field:
logger.warning('{1} crawler could not get {0} field, please check the filter xpath'.
format(rule.filters[i], rule.rule_name))
continue
filters.append(map(lambda x: x.text.strip(), field))
filters = zip(*filters)
selector = map(lambda x: x == rule.filters, filters)
proxies = compress(proxies, selector)
for proxy in proxies:
await self._proxies.put(proxy) # 解析后的代理放入asyncio.Queue中爬虫规则
网站爬取、代理解析、滤等等操作的规则都是由各个代理网站的规则类定义的,使用元类和基类来管理规则类。基类定义如下:
class CrawlerRuleBase(object, metaclass=CrawlerRuleMeta): start_url = None page_count = 0 urls_format = None next_page_xpath = None next_page_host = '' use_phantomjs = False phantomjs_load_flag = None filters = () ip_xpath = None port_xpath = None filters_xpath = ()
各个参数的含义如下:
start_url(必需)
爬虫的起始页面。
ip_xpath(必需)
爬取IP的xpath规则。
port_xpath(必需)
爬取端口号的xpath规则。
page_count
爬取的页面数量。
urls_format
页面地址的格式字符串,通过urls_format.format(start_url, n)来生成第n页的地址,这是比较常见的页面地址格式。
next_page_xpath,next_page_host
由xpath规则来获取下一页的url(常见的是相对路径),结合host得到下一页的地址:next_page_host + url。
use_phantomjs, phantomjs_load_flag
use_phantomjs用于标识爬取该网站是否需要使用PhantomJS,若使用,需定义phantomjs_load_flag(网页上的某个元素,str类型)作为PhantomJS页面加载完毕的标志。
filters
过滤字段集合,可迭代类型。用于过滤代理。
爬取各个过滤字段的xpath规则,与过滤字段按顺序一一对应。
元类CrawlerRuleMeta用于管理规则类的定义,如:如果定义use_phantomjs=True,则必须定义phantomjs_load_flag,否则会抛出异常,不在此赘述。
目前已经实现的规则有西刺代理、快代理、360代理、66代理和 秘密代理。新增规则类也很简单,通过继承CrawlerRuleBase来定义新的规则类YourRuleClass,放在proxypool/rules目录下,并在该目录下的init.py中添加from . import YourRuleClass(这样通过CrawlerRuleBase.subclasses()就可以获取全部的规则类了),重启正在运行的proxy pool即可应用新的规则。
2. 检验部分
免费的代理虽然多,但是可用的却不多,所以爬取到代理后需要对其进行检验,有效的代理才能放入代理池中,而代理也是有时效性的,还要定期对池中的代理进行检验,及时移除失效的代理。
这部分就很简单了,使用aiohttp通过代理来访问某个网站,若超时,则说明代理无效。
async def validate(self, proxies): logger.debug('validator started') while 1: proxy = await proxies.get() async with aiohttp.ClientSession() as session: try: real_proxy = 'http://' + proxy async with session.get(self.validate_url, proxy=real_proxy, timeout=validate_timeout) as resp: self._conn.put(proxy) except Exception as e: logger.error(e) proxies.task_done()
3. server部分
使用aiohttp实现了一个web server,启动后,访问http://host:port即可显示主页:
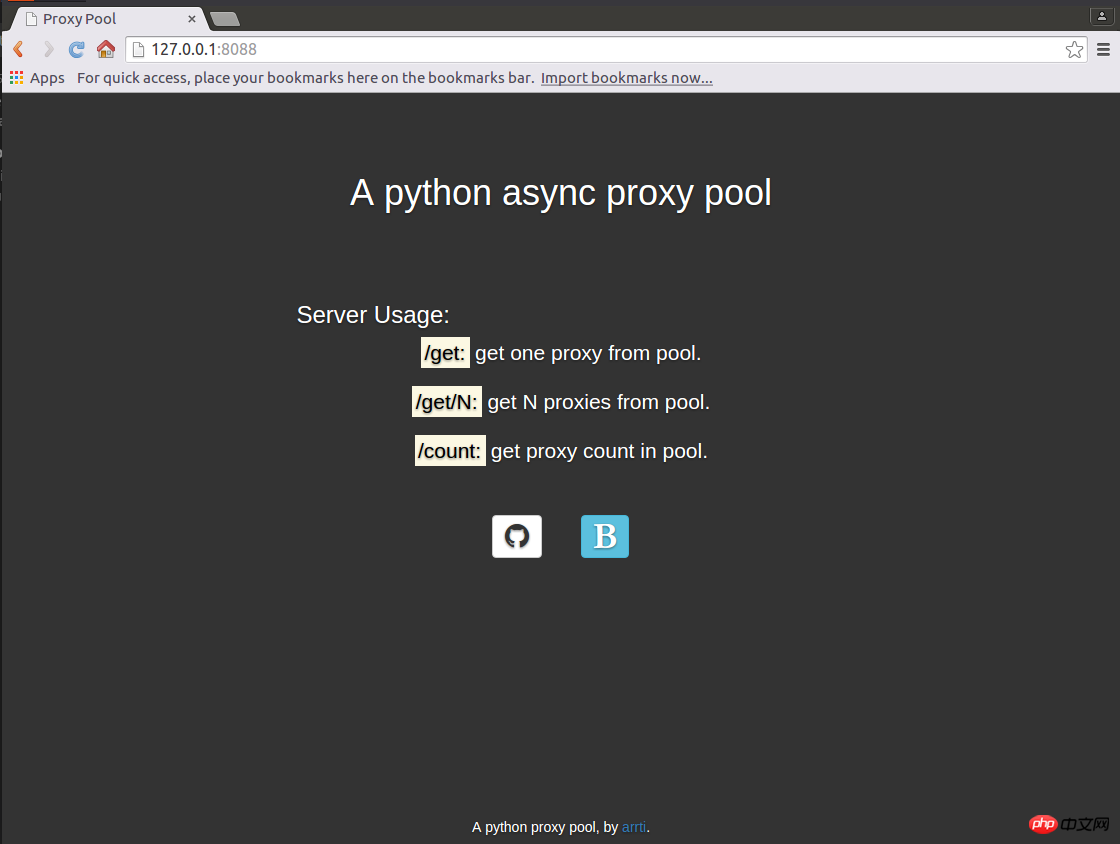
访问host:port/get来从代理池获取1个代理,如:'127.0.0.1:1080';
访问host:port/get/n来从代理池获取n个代理,如:"['127.0.0.1:1080', '127.0.0.1:443', '127.0.0.1:80']";
访问host:port/count来获取代理池的容量,如:'42'。
因为主页是一个静态的html页面,为避免每来一个访问主页的请求都要打开、读取以及关闭该html文件的开销,将其缓存到了redis中,通过html文件的修改时间来判断其是否被修改过,如果修改时间与redis缓存的修改时间不同,则认为html文件被修改了,则重新读取文件,并更新缓存,否则从redis中获取主页的内容。
返回代理是通过aiohttp.web.Response(text=ip.decode('utf-8'))实现的,text要求str类型,而从redis中获取到的是bytes类型,需要进行转换。返回的多个代理,使用eval即可转换为list类型。
返回主页则不同,是通过aiohttp.web.Response(body=main_page_cache, content_type='text/html') ,这里body要求的是bytes类型,直接将从redis获取的缓存返回即可,conten_type='text/html'必不可少,否则无法通过浏览器加载主页,而是会将主页下载下来——在运行官方文档中的示例代码的时候也要注意这点,那些示例代码基本上都没有设置content_type。
这部分不复杂,注意上面提到的几点,而关于主页使用的静态资源文件的路径,可以参考之前的博客《aiohttp之添加静态资源路径》。
4. 运行
将整个代理池的功能分成了3个独立的部分:
proxypool
定期检查代理池容量,若低于下限则启动代理爬虫并对代理检验,通过检验的爬虫放入代理池,达到规定的数量则停止爬虫。
proxyvalidator
用于定期检验代理池中的代理,移除失效代理。
proxyserver
启动server。
这3个独立的任务通过3个进程来运行,在Linux下可以使用supervisod来=管理这些进程,下面是supervisord的配置文件示例:
; supervisord.conf [unix_http_server] file=/tmp/supervisor.sock [inet_http_server] port=127.0.0.1:9001 [supervisord] logfile=/tmp/supervisord.log logfile_maxbytes=5MB logfile_backups=10 loglevel=debug pidfile=/tmp/supervisord.pid nodaemon=false minfds=1024 minprocs=200 [rpcinterface:supervisor] supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface [supervisorctl] serverurl=unix:///tmp/supervisor.sock [program:proxyPool] command=python /path/to/ProxyPool/run_proxypool.py redirect_stderr=true stdout_logfile=NONE [program:proxyValidator] command=python /path/to/ProxyPool/run_proxyvalidator.py redirect_stderr=true stdout_logfile=NONE [program:proxyServer] command=python /path/to/ProxyPool/run_proxyserver.py autostart=false redirect_stderr=true stdout_logfile=NONE
因为项目自身已经配置了日志,所以这里就不需要再用supervisord捕获stdout和stderr了。通过supervisord -c supervisord.conf启动supervisord,proxyPool和proxyServer则会随之自动启动,proxyServer需要手动启动,访问http://127.0.0.1:9001即可通过网页来管理这3个进程了:
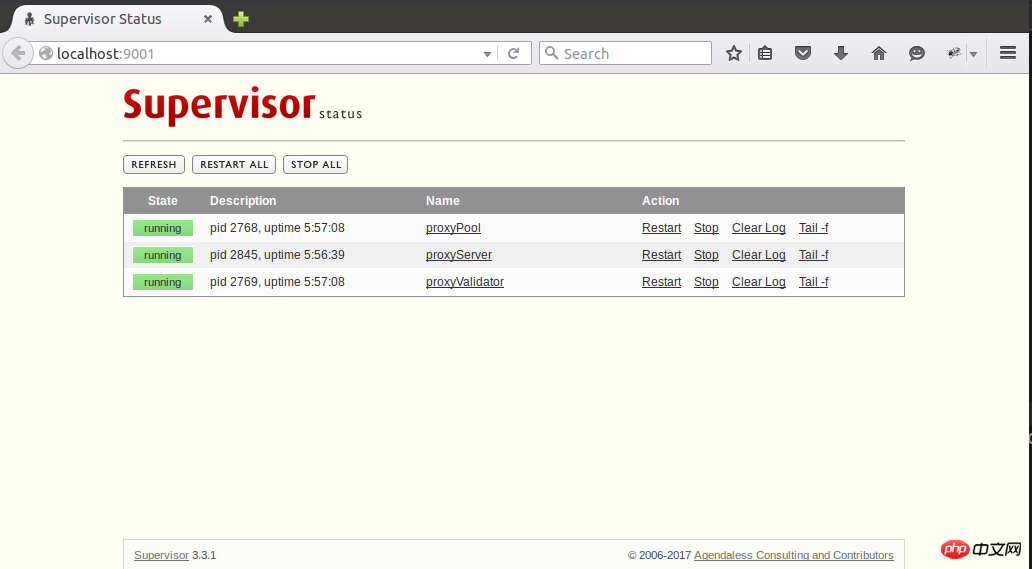
supervisod的官方文档说目前(版本3.3.1)不支持python3,但是我在使用过程中没有发现什么问题,可能也是由于我并没有使用supervisord的复杂功能,只是把它当作了一个简单的进程状态监控和启停工具了。
【相关推荐】
1. Python免费视频教程
3. Python学习手册
以上是详解异步代理和代理池的python代码的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 PHP和Python:代码示例和比较
Apr 15, 2025 am 12:07 AM
PHP和Python:代码示例和比较
Apr 15, 2025 am 12:07 AM
PHP和Python各有优劣,选择取决于项目需求和个人偏好。1.PHP适合快速开发和维护大型Web应用。2.Python在数据科学和机器学习领域占据主导地位。
 CentOS上如何进行PyTorch模型训练
Apr 14, 2025 pm 03:03 PM
CentOS上如何进行PyTorch模型训练
Apr 14, 2025 pm 03:03 PM
在CentOS系统上高效训练PyTorch模型,需要分步骤进行,本文将提供详细指南。一、环境准备:Python及依赖项安装:CentOS系统通常预装Python,但版本可能较旧。建议使用yum或dnf安装Python3并升级pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。CUDA与cuDNN(GPU加速):如果使用NVIDIAGPU,需安装CUDATool
 Python vs. JavaScript:社区,图书馆和资源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社区,图书馆和资源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社区、库和资源方面的对比各有优劣。1)Python社区友好,适合初学者,但前端开发资源不如JavaScript丰富。2)Python在数据科学和机器学习库方面强大,JavaScript则在前端开发库和框架上更胜一筹。3)两者的学习资源都丰富,但Python适合从官方文档开始,JavaScript则以MDNWebDocs为佳。选择应基于项目需求和个人兴趣。
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 CentOS下PyTorch版本怎么选
Apr 14, 2025 pm 02:51 PM
CentOS下PyTorch版本怎么选
Apr 14, 2025 pm 02:51 PM
在CentOS下选择PyTorch版本时,需要考虑以下几个关键因素:1.CUDA版本兼容性GPU支持:如果你有NVIDIAGPU并且希望利用GPU加速,需要选择支持相应CUDA版本的PyTorch。可以通过运行nvidia-smi命令查看你的显卡支持的CUDA版本。CPU版本:如果没有GPU或不想使用GPU,可以选择CPU版本的PyTorch。2.Python版本PyTorch
 minio安装centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安装centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO对象存储:CentOS系统下的高性能部署MinIO是一款基于Go语言开发的高性能、分布式对象存储系统,与AmazonS3兼容。它支持多种客户端语言,包括Java、Python、JavaScript和Go。本文将简要介绍MinIO在CentOS系统上的安装和兼容性。CentOS版本兼容性MinIO已在多个CentOS版本上得到验证,包括但不限于:CentOS7.9:提供完整的安装指南,涵盖集群配置、环境准备、配置文件设置、磁盘分区以及MinI
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
