

多页面爬虫在nodejs中的示例代码分析

本篇文章主要介绍了基于nodejs 的多页面爬虫 ,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
前言
前端时间再回顾了一下node.js,于是顺势做了一个爬虫来加深自己对node的理解。
主要用的到是request,cheerio,async三个模块
request
用于请求地址和快速下载图片流。
cheerio
为服务器特别定制的,快速、灵活、实施的jQuery核心实现.
便于解析html代码。
async
异步调用,防止堵塞。
核心思路
用request 发送一个请求。获取html代码,取得其中的img标签和a标签。
通过获取的a表情进行递归调用。不断获取img地址和a地址,继续递归
获取img地址通过request(photo).pipe(fs.createWriteStream(dir “/” filename));进行快速下载。
function requestall(url) {
request({
uri: url,
headers: setting.header
}, function (error, response, body) {
if (error) {
console.log(error);
} else {
console.log(response.statusCode);
if (!error && response.statusCode == 200) {
var $ = cheerio.load(body);
var photos = [];
$('img').each(function () {
// 判断地址是否存在
if ($(this).attr('src')) {
var src = $(this).attr('src');
var end = src.substr(-4, 4).toLowerCase();
if (end == '.jpg' || end == '.png' || end == '.jpeg') {
if (IsURL(src)) {
photos.push(src);
}
}
}
});
downloadImg(photos, dir, setting.download_v);
// 递归爬虫
$('a').each(function () {
var murl = $(this).attr('href');
if (IsURL(murl)) {
setTimeout(function () {
fetchre(murl);
}, timeout);
timeout += setting.ajax_timeout;
} else {
setTimeout(function () {
fetchre("http://www.ivsky.com/" + murl);
}, timeout);
timeout += setting.ajax_timeout;
}
})
}
}
});
}防坑
1.在request通过图片地址下载时,绑定error事件防止爬虫异常的中断。
2.通过async的mapLimit限制并发。
3.加入请求报头,防止ip被屏蔽。
4.获取一些图片和超链接地址,可能是相对路径(待考虑解决是否有通过方法)。
function downloadImg(photos, dir, asyncNum) {
console.log("即将异步并发下载图片,当前并发数为:" + asyncNum);
async.mapLimit(photos, asyncNum, function (photo, callback) {
var filename = (new Date().getTime()) + photo.substr(-4, 4);
if (filename) {
console.log('正在下载' + photo);
// 默认
// fs.createWriteStream(dir + "/" + filename)
// 防止pipe错误
request(photo)
.on('error', function (err) {
console.log(err);
})
.pipe(fs.createWriteStream(dir + "/" + filename));
console.log('下载完成');
callback(null, filename);
}
}, function (err, result) {
if (err) {
console.log(err);
} else {
console.log(" all right ! ");
console.log(result);
}
})
}测试:
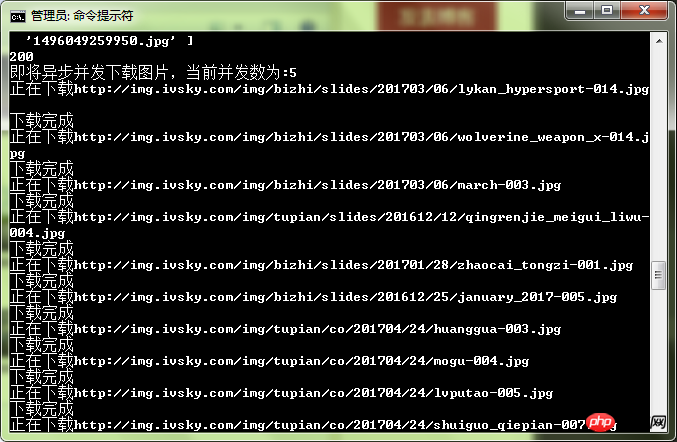
可以感觉到速度还是比较快的。
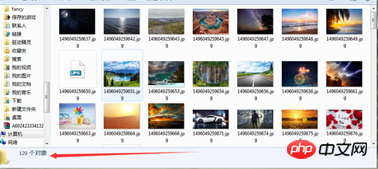
以上是多页面爬虫在nodejs中的示例代码分析的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 nodejs和vuejs区别
Apr 21, 2024 am 04:17 AM
nodejs和vuejs区别
Apr 21, 2024 am 04:17 AM
Node.js 是一种服务器端 JavaScript 运行时,而 Vue.js 是一个客户端 JavaScript 框架,用于创建交互式用户界面。Node.js 用于服务器端开发,如后端服务 API 开发和数据处理,而 Vue.js 用于客户端开发,如单页面应用程序和响应式用户界面。

 nodejs怎么连接mysql数据库
Apr 21, 2024 am 06:13 AM
nodejs怎么连接mysql数据库
Apr 21, 2024 am 06:13 AM
要连接 MySQL 数据库,需要遵循以下步骤:安装 mysql2 驱动程序。使用 mysql2.createConnection() 创建连接对象,其中包含主机地址、端口、用户名、密码和数据库名称。使用 connection.query() 执行查询。最后使用 connection.end() 结束连接。
 nodejs安装目录里的npm与npm.cmd文件有什么区别
Apr 21, 2024 am 05:18 AM
nodejs安装目录里的npm与npm.cmd文件有什么区别
Apr 21, 2024 am 05:18 AM
Node.js 安装目录中有两个与 npm 相关的文件:npm 和 npm.cmd,区别如下:扩展名不同:npm 是可执行文件,npm.cmd 是命令窗口快捷方式。Windows 用户:npm.cmd 可以在命令提示符下使用,npm 只能从命令行运行。兼容性:npm.cmd 特定于 Windows 系统,npm 跨平台可用。使用建议:Windows 用户使用 npm.cmd,其他操作系统使用 npm。
 nodejs中的全局变量有哪些
Apr 21, 2024 am 04:54 AM
nodejs中的全局变量有哪些
Apr 21, 2024 am 04:54 AM
Node.js 中存在以下全局变量:全局对象:global核心模块:process、console、require运行时环境变量:__dirname、__filename、__line、__column常量:undefined、null、NaN、Infinity、-Infinity
 nodejs和java的差别大吗
Apr 21, 2024 am 06:12 AM
nodejs和java的差别大吗
Apr 21, 2024 am 06:12 AM
Node.js 和 Java 的主要差异在于设计和特性:事件驱动与线程驱动:Node.js 基于事件驱动,Java 基于线程驱动。单线程与多线程:Node.js 使用单线程事件循环,Java 使用多线程架构。运行时环境:Node.js 在 V8 JavaScript 引擎上运行,而 Java 在 JVM 上运行。语法:Node.js 使用 JavaScript 语法,而 Java 使用 Java 语法。用途:Node.js 适用于 I/O 密集型任务,而 Java 适用于大型企业应用程序。

 nodejs和java选哪个
Apr 21, 2024 am 04:40 AM
nodejs和java选哪个
Apr 21, 2024 am 04:40 AM
Node.js 和 Java 在 Web 开发中各有优劣,具体选择取决于项目要求。Node.js 擅长实时应用程序、快速开发和微服务架构,而 Java 则在企业级支持、性能和安全性方面占优。
