

分享js-spark-md5使用教程

js-spark-md5是歪果仁开发的东西,有点多,但是我们只要一个js文件即可,具体类包我存在自己的oschina上,下载地址:
js-spark-md5是做什么的? js-spark-md5是号称全宇宙最快的前端类包,可以无需上传文件就快速获取本地文件md5.
可能你觉得这没什么,但是,当你做一个文件系统时候,就有这需求,用这个简单的前端类库就能实现你“秒传”的功能!这里我解释下,每个文件的md5值都是唯一的,这也是很多下载网站,会告诉你原文件的md5是多少,然后下载完毕让你自行去对比下,如果一致,就说明文件是完整的。
好了,正因为每个文件的md5是一样的,那么,我们在做文件上传的时候,就只要在前端先获取要上传的文件md5,并把文件md5传到服务器,对比之前文件的md5,如果存在相同的md5,我们只要把文件的名字传到服务器关联之前的文件即可,并不需要再次去上传相同的文件,再去耗费存储资源、上传的时间、网络带宽。
js-spark-md5使用教程:
1.先引入js类包
2.写文件表单
代码:
<script> var log=document.getElementById("log"); document.getElementById("file").addEventListener("change", function() { var blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice, file = this.files[0], chunkSize = 2097152, // read in chunks of 2MB chunks = Math.ceil(file.size / chunkSize), currentChunk = 0, spark = new SparkMD5.ArrayBuffer(), frOnload = function(e){ // log.innerHTML+="\nread chunk number "+parseInt(currentChunk+1)+" of "+chunks; spark.append(e.target.result); // append array buffer currentChunk++; if (currentChunk < chunks) loadNext(); else log.innerHTML+="\n加载结束 :\n\n计算后的文件md5:\n"+spark.end()+"\n\n现在你可以选择另外一个文件!\n"; }, frOnerror = function () { log.innerHTML+="\糟糕,好像哪里错了."; }; function loadNext() { var fileReader = new FileReader(); fileReader.onload = frOnload; fileReader.onerror = frOnerror; var start = currentChunk * chunkSize, end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize; fileReader.readAsArrayBuffer(blobSlice.call(file, start, end)); }; loadNext(); }); </script>
1
2
3
4
5
6
7
8
9
10
11
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<form method="POST"enctype="multipart/form-data"onsubmit="return false;">
<input id=file type=file placeholder="select a file"/>
</form>
<pre id=log>登录后复制
注意,spark.end()就是文件的md5值,文件引用顺序一定不能倒了,要不无法正常工作。
正常工作的截图:
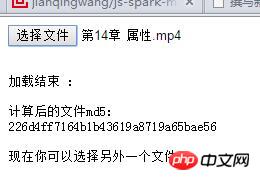
本人博客:基于js-spark-md5前端js类库,快速获取文件Md5值
以上是分享js-spark-md5使用教程的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!
热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP与Vue:完美搭档的前端开发利器
Mar 16, 2024 pm 12:09 PM
PHP与Vue:完美搭档的前端开发利器
Mar 16, 2024 pm 12:09 PM
PHP与Vue:完美搭档的前端开发利器在当今互联网高速发展的时代,前端开发变得愈发重要。随着用户对网站和应用的体验要求越来越高,前端开发人员需要使用更加高效和灵活的工具来创建响应式和交互式的界面。PHP和Vue.js作为前端开发领域的两个重要技术,搭配起来可以称得上是完美的利器。本文将探讨PHP和Vue的结合,以及详细的代码示例,帮助读者更好地理解和应用这两
 Win11系统中'我的电脑”路径有何不同?快速查找方法!
Mar 29, 2024 pm 12:33 PM
Win11系统中'我的电脑”路径有何不同?快速查找方法!
Mar 29, 2024 pm 12:33 PM
Win11系统中“我的电脑”路径有何不同?快速查找方法!随着Windows系统的不断更新,最新的Windows11系统也带来了一些新的变化和功能。其中一个常见的问题是用户在Win11系统中找不到“我的电脑”的路径,这在之前的Windows系统中通常是很简单的操作。本文将介绍Win11系统中“我的电脑”的路径有何不同,以及快速查找的方法。在Windows1
 Django是前端还是后端?一探究竟!
Jan 19, 2024 am 08:37 AM
Django是前端还是后端?一探究竟!
Jan 19, 2024 am 08:37 AM
Django是一个Python编写的web应用框架,它强调快速开发和干净方法。尽管Django是一个web框架,但是要回答Django是前端还是后端这个问题,需要深入理解前后端的概念。前端是指用户直接和交互的界面,后端是指服务器端的程序,他们通过HTTP协议进行数据的交互。在前端和后端分离的情况下,前后端程序可以独立开发,分别实现业务逻辑和交互效果,数据的交
 简易JavaScript教程:获取HTTP状态码的方法
Jan 05, 2024 pm 06:08 PM
简易JavaScript教程:获取HTTP状态码的方法
Jan 05, 2024 pm 06:08 PM
JavaScript教程:如何获取HTTP状态码,需要具体代码示例前言:在Web开发中,经常会涉及到与服务器进行数据交互的场景。在与服务器进行通信时,我们经常需要获取返回的HTTP状态码来判断操作是否成功,根据不同的状态码来进行相应的处理。本篇文章将教你如何使用JavaScript获取HTTP状态码,并提供一些实用的代码示例。使用XMLHttpRequest
 Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言作为一种快速、高效的编程语言,在后端开发领域广受欢迎。然而,很少有人将Go语言与前端开发联系起来。事实上,使用Go语言进行前端开发不仅可以提高效率,还能为开发者带来全新的视野。本文将探讨使用Go语言进行前端开发的可能性,并提供具体的代码示例,帮助读者更好地了解这一领域。在传统的前端开发中,通常会使用JavaScript、HTML和CSS来构建用户界面
 WordPress 网站搭建指南:快速搭建个人网站
Mar 04, 2024 pm 04:39 PM
WordPress 网站搭建指南:快速搭建个人网站
Mar 04, 2024 pm 04:39 PM
WordPress网站搭建指南:快速搭建个人网站随着数字化时代的到来,拥有一个个人网站已经成为了一种时尚和必要。而WordPress作为最受欢迎的网站搭建工具,让搭建个人网站变得更加容易和便捷。本文将为大家提供一个快速搭建个人网站的指南,包含具体的代码示例,希望可以帮助到想要拥有自己网站的朋友们。第一步:购买域名和主机在开始搭建个人网站之前,首先要购买自己
 Django:前端和后端开发都能搞定的神奇框架!
Jan 19, 2024 am 08:52 AM
Django:前端和后端开发都能搞定的神奇框架!
Jan 19, 2024 am 08:52 AM
Django:前端和后端开发都能搞定的神奇框架!Django是一个高效、可扩展的Web应用程序框架。它能够支持多种Web开发模式,包括MVC和MTV,可以轻松地开发出高质量的Web应用程序。Django不仅支持后端开发,还能够快速构建出前端的界面,通过模板语言,实现灵活的视图展示。Django把前端开发和后端开发融合成了一种无缝的整合,让开发人员不必专门学习
 前端面试官常问的问题
Mar 19, 2024 pm 02:24 PM
前端面试官常问的问题
Mar 19, 2024 pm 02:24 PM
在前端开发面试中,常见问题涵盖广泛,包括HTML/CSS基础、JavaScript基础、框架和库、项目经验、算法和数据结构、性能优化、跨域请求、前端工程化、设计模式以及新技术和趋势。面试官的问题旨在评估候选人的技术技能、项目经验以及对行业趋势的理解。因此,应试者应充分准备这些方面,以展现自己的能力和专业知识。
