

JAVA WEB 笔记--中文乱码
JAVA WEB 乱码问题解析
乱码原因
在Java Web开发过程中,经常遇到乱码的问题,造成乱码的原因,概括起来就是对字符编码和解码的方式不匹配。
既然乱码的原因是字符编码与解码的方式不匹配,那么为什么我们一定要对字符进行编码,不编码可不可以呢?这是因为在计算机中存储数据的基本单位是1个字节,即8个bit,那么它所能表达的字符的最多有28=256个,而在我们现实社会中存在的字符(汉字、英文、其他文字等等)远远多余这个数字,所以为了解决字符与字节的矛盾,对字符进行编码处理才能存储在计算机中。
编码与解码
在计算机中常见的编码方式有ASCII、ISO-8859-1、GB2312、UTF-16、UTF-8几种编码方式。
ASCII码是使用一个字节的低7位来表示的,所以共能表达的字符最多有27=128个。ISO-8859-1是ISO组织基于ASCII码的基础上扩展来的,兼容ASCII码,涵盖了大多数西欧字符。ISO8859-1使用一个字节来表示,所以其能表达的字符最多有256个。GB2312,采用了双字节编码,编码范围是A1-F7,其中A1-A9是符号区,B0-F7是汉字区,包含6763个汉字。GBK是为了扩展GB2312编码,并加入了更多的汉字,总能表达的汉字有21003个。UTF-16是采用定长的编码方式,无论什么字符都采用2个字节进行表示,这也是JAVA内存中字符的存储格式。与UTF-16相反,UTF-8采用了变长的编码方式,不同的类型的字符可以由1-6个字节组成。
下面以字符串“日向雏田”来看一下在计算机中不同编码方式的编码,如下图。

乱码分析与解决
对于JAVA WEB中乱码问题,我们划分位请求导致的乱码和响应导致的乱码,对于不同的乱码我们要分析其乱码原因,即字符编码的方式是什么,解码的方式是什么。
对于由于请求导致的乱码我们要分析Http请求,查看其编码方式,由于HTTP请求分为Get请求和Post请求,我们接下来分别对其进行讨论。
对于Get请求,是浏览器默认的请求方式,和表单提交时设置为“Get”时的提交方式。我们通过火狐浏览器我们查看其具体内容如下:
地址栏为:
请求内容为:

通过上面请求我们可以看到,GET请求中查询字符串放在了请求行中存放,发送到WEB服务器中,通过“日向雏田”编码我们可以看到,浏览器对该字符串采用的编码方式为“UTF-8”。
查看服务器代码我们可以看到乱码(如下图),这是因为服务器在接受到该字符串编码后的数据默认通过ISO-8859-1的方式进行解码,所以造成了编码与解码的方式不统一。

解决方案如下:
首先获取字符串user解码前的编码,然后指定该字符串的编码方式,如下图:

解决方案示意图如下:

在Java web开发过程中,我们在超链接中传递参数,经常遇到中文的情况。对此情况下,我们需要对中文进行编码,我们可以设置为UTF-8,解码方案同上。
<a href="${pageContext.request.contextPath}/Test?user=<%=URLEncoder.encode("日向雏田", "UTF-8")%>">点击</a>对于Post请求,是表单提交时设置为“Post”时的提交方式。我们通过火狐浏览器我们查看其具体内容如下:
地址栏及其页面为:

post请求内容为:

由上图我们可以知道,在post请求中,将请求内容直接放在请求体中发送给web服务器,编码方式为“utf-8”。
在此响应Servlet中,doPost方法体如下:
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String user=request.getParameter("user");
System.out.println(user);//输出为æ¥åéç°
}
此处乱码的原因依然时在代码getParameter(“user”)时,web服务器采用默认的解码方案“ISO-8859-1”进行解码,导致了编码与解码方案的不同意,解决方案可以采用get请求乱码的解决方案,但是还有一种更为简单的解决方案,直接指定方法体的编码/解码方案为“utf-8”。方案如下。
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8"); //设置请求体的编码/解码方案为UTF-8 但是请求行的编码解码方案不会受影响
String user=request.getParameter("user");
System.out.println(user); //输出为日向雏田
}以上对于请求导致的乱码情况分析完毕。
在影响导致的乱码中,web服务器会将响应的内容写入响应体中,返回给客户端并不会涉及到状态行中的情况。如向浏览器输出”HelloWorld“其响应如下图所说。
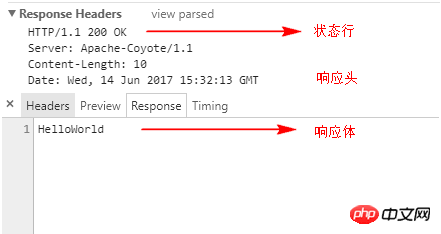
对于响应导致的乱码我们不得不涉及到四个方法,如下:
response.setHeader("Content-Type", "text/html;cahrset=utf-8");//设置发送到客户端的响应的内容类型和响应内容的编码类型(响应体的编码类型)
response.setCharacterEncoding("utf-8");//设置响应体的编码类型
response.getWriter(); //获取响应的输出字符流
response.getOutputStream(); //获取响应的输出字节流
对于设置响应体的编码类型,如response.setHeader("Content-Type", "text/html;cahrset=utf-8");与response.setCharacterEncoding("utf-8");这2个方法设置的编码方式等效,若没有设置响应体的编码方式,则默认为ISO-8859-1,而且后面设置响应体字符的编码方式会迭代前面的设置编码的方式。这两个方法均在getWriter方法前有效,在getWriter方法设置编码的方法会无效。
但是这2个方法却有点不同,即setHeader("Content-Type", "text/html;cahrset=utf-8")这个方法浏览器会自动采用该响应体的编码方式进行解码,而setCharacterEncoding()该方法并不是所有的浏览器都会采用该方法的编码方式进行解码,下面对这2个方法进行测试,效果如下:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setHeader("Content-Type", "text/html;charset=utf-8");
response.getWriter().write("日向雏田");
} 
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8");
response.getWriter().write("日向雏田");
} 
从上面可以看到第一个方法对于浏览器来说,支持的较好,提倡采用第一种方法设置响应体的字符编码方式。
对于获取响应字符输出流的方法,如果在此之前没有设置响应体的编码方式,那么默认为null,即ISO-8859-1方式进行编码。而且后面设置的编码方式会覆盖前面设置的编码方式。在getWriter()方法之后设置的编码无效。
对于获取响应输出字节流,我们在输出字符串时,我们需要设置字符串的编码方式如果没有那么默认ISO-8859-1。
对于前面2个输出流,由于只有一个输出缓存,所以这两个方法互斥。
以上,为了保证响应无乱码,需要保证字符编码和解码方法的统一,方案如下:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 方案1
// response.setHeader("Content-Type", "text/html;charset=utf-8");
// response.getWriter().write("日向雏田");
// 方案2
// response.getOutputStream().write("日向雏田".getBytes("UTF-8"));
// 方案1,2互斥
}
此外在Java web开发过程中,我们还会遇到当进行文件下载时,中文文件名导致的问题,如下图所示:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
response.setHeader("content-disposition", "attachment;filename="+fileName);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}采用火狐浏览器进行测试,查看页面效果,及其响应结果如下:


经过查看响应头分析,下载文件名存放在响应头中,且对于中文文字没有采用UTF-8、UTF-16、GBK等等能识别中文的编码,那么对于中文文件名导致采用哪种编码方式呢?查看REF 7578得知,在此处采用ASCII编码,但是REF规定,如果不可避免的要使用非ASCII码的字符,程序员应该均匀的使用UTF-8,来最小化交互操作的问题。
所以,解决方案就是把文件名编码成UTF-8,传递给响应头,浏览器(部分)默认对该文件名进行UTF-8解码处理。
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
String utf_8Name=URLEncoder.encode(fileName,"utf-8");//解决方案
response.setHeader("content-disposition", "attachment;filename="+utf_8Name);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}效果如下:其中火狐浏览器并没有对其解码

以上是JAVA WEB 笔记--中文乱码的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 小红书笔记怎么删除
Mar 21, 2024 pm 08:12 PM
小红书笔记怎么删除
Mar 21, 2024 pm 08:12 PM
小红书笔记怎么删除?在小红书APP中是可以编辑笔记的,多数的用户不知道小红书笔记如何的删除,接下来就是小编为用户带来的小红书笔记删除方法图文教程,感兴趣的用户快来一起看看吧!小红书使用教程小红书笔记怎么删除1、首先打开小红书APP进入到主页面,选择右下角【我】进入到专区;2、之后在我的专区,点击下图所示的笔记页面,选择要删除的笔记;3、进入到笔记页面,右上角【三个点】;4、最后下方会展开功能栏,点击【删除】即可完成。
 使命召唤战区手游怎么设置中文
Mar 22, 2024 am 08:41 AM
使命召唤战区手游怎么设置中文
Mar 22, 2024 am 08:41 AM
使命召唤战区作为全新上线的一款手游,有很多的玩家都非常的好奇要怎么样才能够将这款游戏的语言设置为中文,其实非常的简单,玩家只需要下载中文的语言包,随后进行使用就可以进行修改了,详细的内容可以在这篇中文设置方法介绍之中进行了解,让我们一起来看看吧。使命召唤战区手游怎么设置中文1、首先进入游戏,点击界面右上角的设置图标。2、在出现的菜单栏中,找到【Download】这个选项并且点击。3、在这个页面中选择【SIMPLIFIEDCHINESE】(简体中文),就可以对简体中文的安装包进行下载了。4、回到设
 Excel表格怎么设置显示中文?Excel切换中文操作教程
Mar 14, 2024 pm 03:28 PM
Excel表格怎么设置显示中文?Excel切换中文操作教程
Mar 14, 2024 pm 03:28 PM
Excel表格是现在很多人都在使用的办公软件之一,有些用户因为电脑是win11系统,因此显示的是英文界面,想要切换成中文界面,但是不知道应该怎么操作,针对这个问题,本期小编就来为广大用户们进行解答,一起来看看今日软件教程所分享的内容吧。 Excel切换中文操作教程: 1、进入软件,点击页面上方工具栏左侧的“File”选项。 2、在下方给出的选项中选择“options”。 3、进入新界面后,点击左侧的“language”选项
 VSCode 设置中文:完全指南
Mar 25, 2024 am 11:18 AM
VSCode 设置中文:完全指南
Mar 25, 2024 am 11:18 AM
VSCode设置中文:完全指南在软件开发中,VisualStudioCode(简称VSCode)是一个常用的集成开发环境。对于使用中文的开发者来说,将VSCode设置为中文界面可以提升工作效率。本文将为大家提供一个完整的指南,详细介绍如何将VSCode设置为中文界面,并提供具体的代码示例。第一步:下载安装语言包在打开VSCode后,点击左
 小红书发布过的笔记不见了怎么办?它刚发的笔记搜不到的原因是什么?
Mar 21, 2024 pm 09:30 PM
小红书发布过的笔记不见了怎么办?它刚发的笔记搜不到的原因是什么?
Mar 21, 2024 pm 09:30 PM
作为一名小红书的用户,我们都曾遇到过发布过的笔记突然不见了的情况,这无疑让人感到困惑和担忧。在这种情况下,我们该怎么办呢?本文将围绕“小红书发布过的笔记不见了怎么办”这一主题,为你详细解答。一、小红书发布过的笔记不见了怎么办?首先,不要惊慌。如果你发现笔记不见了,保持冷静是关键,不要慌张。这可能是由于平台系统故障或操作失误引起的。检查发布记录很简单。只需打开小红书App,点击“我”→“发布”→“所有发布”,就可以查看自己的发布记录。在这里,你可以轻松找到之前发布的笔记。3.重新发布。如果找到了之
 wwe2k24会有中文吗
Mar 13, 2024 pm 04:40 PM
wwe2k24会有中文吗
Mar 13, 2024 pm 04:40 PM
《WWE2K24》乃由VisualConcepts倾力打造的竞速体育游,已于2024年3月9日正式问世。此款游戏倍受赞誉,众多玩家热切关注其是否设有中文版。遗憾的是,迄今为止,《WWE2K24》尚未推出中文语言版本。wwe2k24会有中文吗答:目前不支持中文。WWE2K24在Steam国区的标准版售价为199元,豪华版为329元,纪念版为395元。该游戏的配置要求较高,无论处理器、显卡或运行内存等方面,均有一定标准。官方推荐配置以及最低配置介绍:
 小红书怎么在笔记中添加商品链接 小红书在笔记中添加商品链接教程
Mar 12, 2024 am 10:40 AM
小红书怎么在笔记中添加商品链接 小红书在笔记中添加商品链接教程
Mar 12, 2024 am 10:40 AM
小红书怎么在笔记中添加商品链接?在小红书这款app中用户不仅可以浏览各种内容还可以进行购物,所以这款app中关于购物推荐、好物分享的内容是非常多的,如果小伙伴在这款app也是一个达人的话,也可以分享一些购物经验,找到商家进行合作,在笔记中添加连接之类的,很多人都愿意使用这款app购物,因为不仅方便,而且有很多达人会进行一些推荐,可以一边浏览有趣内容,一边看看有没有适合自己的衣服商品。一起看看如何在笔记中添加商品链接吧!小红书笔记添加商品链接方法 在手机桌面上打开app。 在app首页点击
 解决PHP写入txt文件中文乱码的技巧
Mar 27, 2024 pm 01:18 PM
解决PHP写入txt文件中文乱码的技巧
Mar 27, 2024 pm 01:18 PM
解决PHP写入txt文件中文乱码的技巧随着互联网的迅猛发展,PHP作为一种广泛应用的编程语言,被越来越多的开发者所使用。在PHP开发中,经常需要对文本文件进行读写操作,其中包括写入中文内容的txt文件。然而,由于编码格式的问题,有时候会导致写入的中文出现乱码。本文将介绍一些解决PHP写入txt文件中文乱码的技巧,并提供具体的代码示例。问题分析在PHP中,文本
