
介绍一下scrapy 爬虫框架
安装方法 pip install scrapy 就可以实现安装了。我自己用anaconda 命令为conda install scrapy。

1 Engine从Spider处获得爬取请求(Request)<br>2Engine将爬取请求转发给Scheduler,用于调度
3 Engine从Scheduler处获得下一个要爬取的请求<br>4 Engine将爬取请求通过中间件发送给Downloader<br>5 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine<br>6 Engine将收到的响应通过中间件发送给Spider处理Engine将爬取请求转发给Scheduler,用于调度
7 Spider处理响应后产生爬取项(scraped Item)<br>和新的爬取请求(Requests)给Engine<br>8 Engine将爬取项发送给Item Pipeline(框架出口)<br>9 Engine将爬取请求发送给Scheduler
Engine控制各模块数据流,不间断从Scheduler处<br>获得爬取请求,直至请求为空<br>框架入口:Spider的初始爬取请求<br>框架出口:Item Pipeline
Engine <br>(1) 控制所有模块之间的数据流<br>(2) 根据条件触发事件<br>不需要用户修改
Downloader<br>根据请求下载网页<br>不需要用户修改
Scheduler<br>对所有爬取请求进行调度管理<br>不需要用户修改
Downloader Middleware<br>目的:实施Engine、Scheduler和Downloader<br>之间进行用户可配置的控制<br>功能:修改、丢弃、新增请求或响应<br>用户可以编写配置代码
Spider<br>(1) 解析Downloader返回的响应(Response)<br>(2) 产生爬取项(scraped item)<br>(3) 产生额外的爬取请求(Request)<br>需要用户编写配置代码
Item Pipelines<br>(1) 以流水线方式处理Spider产生的爬取项<br>(2) 由一组操作顺序组成,类似流水线,每个操<br>作是一个Item Pipeline类型<br>(3) 可能操作包括:清理、检验和查重爬取项中<br>的HTML数据、将数据存储到数据库<br>需要用户编写配置代码
了解了基本概念之后我们开始写第一个scrapy爬虫吧。
首先要新建一个爬虫项目scrapy startproject xxx(项目名)

这个爬虫就简单的爬取一个小说网站的书名与作者吧。
我们现在创建了爬虫项目book现在来编辑他的配置
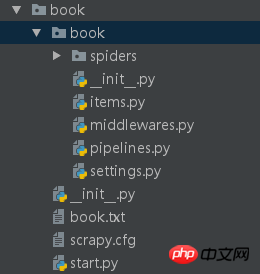
二级book目录下这些就是配置文件上面已经介绍过了,在修改这些之前
我们现在一级book目录下创建一个start.py 来用于scrapy爬虫能在IDE里
面运行。文件里面写下如下代码。

前两个参数是固定的,第三个参数是你spider的名字
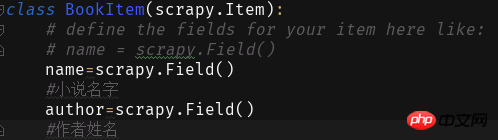
接下来我们就在items里面填写字段:
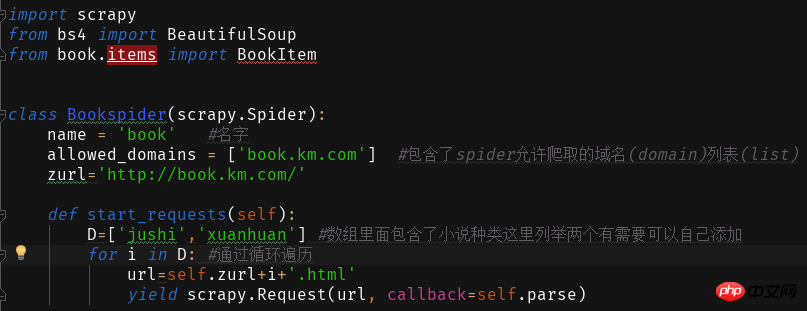
然后在spider中创建爬虫主程序book.py
我们要爬取的网站为
通过点击网站不同种类小说会发现网站地址是+小说种类拼音.html
通过这个我们来写读取网页的内容
得到这个之后我们通过parse 函数来解析所获取的网页并提取所需信息。
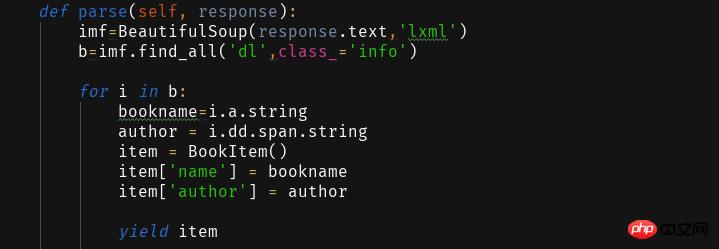
网页分析提取数据是通过BeautifulSoup库来的,这里就略了。自己分析2333~
程序写好我们要存储所爬取的信息就要编辑Pipelines.py 了
这里提供两个保存方式
1保存为txt文本
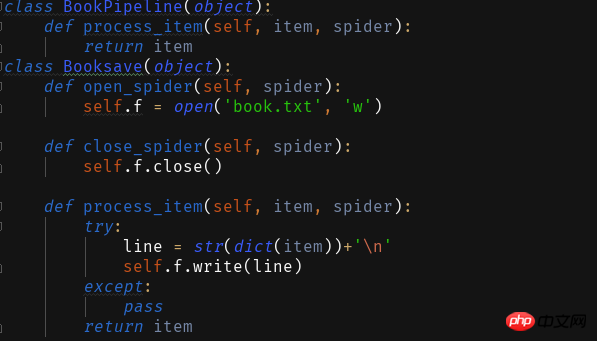
2 存入数据库
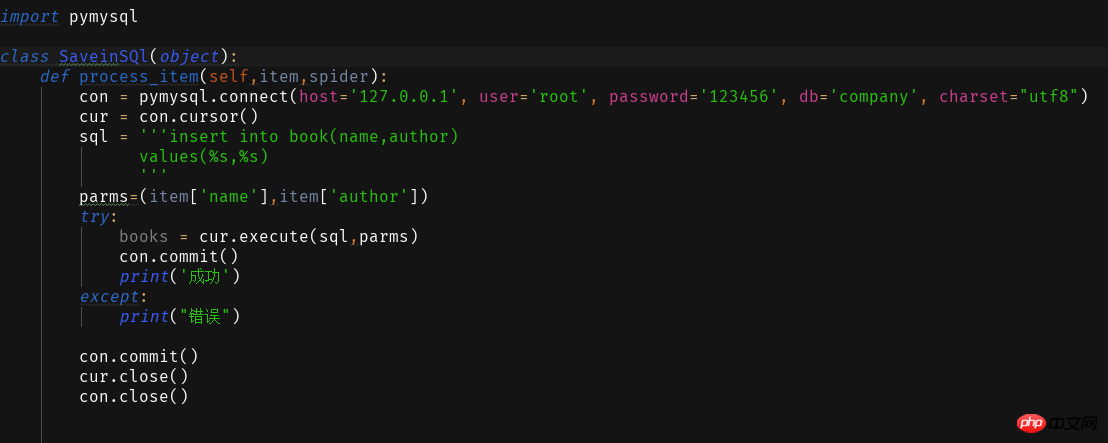
要让这个成功运行我们还需要在setting.py中配置
<span style="color: #000000">ITEM_PIPELINES = { 'book.pipelines.xxx': 300,}<br>xxx为存储方法的类名,想用什么方法存储就改成那个名字就好运行结果没什么看头就略了<br>第一个爬虫框架就这样啦期末忙没时间继续完善这个爬虫之后有时间将这个爬虫完善成把小说内容等一起爬下来的程序再来分享一波。<br>附一个book的完整代码:<br></span>import scrapyfrom bs4 import BeautifulSoupfrom book.items import BookItemclass Bookspider(scrapy.Spider):
name = 'book' #名字
allowed_domains = ['book.km.com'] #包含了spider允许爬取的域名(domain)列表(list)
zurl=''def start_requests(self):
D=['jushi','xuanhuan'] #数组里面包含了小说种类这里列举两个有需要可以自己添加for i in D: #通过循环遍历
url=self.zurl+i+'.html'yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
imf=BeautifulSoup(response.text,'lxml')
b=imf.find_all('dl',class_='info')for i in b:
bookname=i.a.stringauthor = i.dd.span.stringitem = BookItem()
item['name'] = bookname
item['author'] = authoryield item<br>
以上是scrapy爬虫框架的介绍的详细内容。更多信息请关注PHP中文网其他相关文章!





















