

编码的秘密(python版)
编码(python版)
最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你。
编码的概念
编码就是将信息从一种格式转换成另一种格式,计算机只认识二进制,简单的理解,将我们眼睛看到的文字转换为计算机能够识别的二进制格式视为编码,而二进制以某种编码格式转换为我们能看的文字的过程可以看成是解码。既然计算机只能认识二进制0,1,那么我们用的字母、数字和文字等是怎样和他们对应的呢?那就请继续看吧!
python中查看默认的编码规范是:
1 |
|
ASCⅡ码
我们都知道计算机是米国发明的,起初的时候也只有米国那些国家使用,而他们的语言仅仅只有26个字母组成,再加上一些符号,所以在一开始的时候,用的编码规则就是ASCⅡ码。ASCⅡ,中文名叫美国信息交换标准代码,因为名叫American Standard Code for Information Interchange,下面我们来看看ASCⅡ表:

ASCⅡ码用一个字节,也就是8位二进制组来标识一个字符,比如00100001就代表字符!,第一版的ASCⅡ没有用到最高的一个bit,所以取值范围为0-127,只能表示128字符。为了满足西欧等国家的字符要求,于是用上了最高位的bit,能表示的字符也从128增加到了256个。

在python中使用函数ord(),可以字符转换为对应数值,使用函数chr可以将数值转换为对应字符:
1 |
|
GB2312和GBK
当计算机漂洋过海来到了中国,ASCⅡ已经不能满足我大天朝的需求了,常用的汉字大致都有2k-3k。所以中国国家标准总局在1980发布了《信息交换用汉字编码字符集》,也就是GB2313标准。GB2312一共收录了7445个字符(6763个汉字和682个其他符号),包括拉丁字母、希腊字母和日文平假名等,基本上满足了国人的需求。
在GB2312中每个汉字使用两个字节来表示,分为高字节和低字节,汉字区高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768,其中有5个空位是D7FA-D7FE,规定第一个字节大于127的就代表这是一个汉字的开始(这一个字节和下一个字节就代表一个汉字),每个字节的最高位都位1。
但是对于人名、古汉语等方面出现的罕用字,GB2312不能处理,后来就出现了GBK。GBK向下兼容GB2312,其编码范围从8140到FEFE(不包括xx7F),共23940个码位,共收录了21003个汉字,这还是很厉害的了。现在我们使用的计算机默认的就是GBK编码。

Unicode和UTF-8
我们国家搞出了GBK,其他的国家也搞出了各种各样的编码,比如小日本的SJIJ,宝岛台湾的BIG5,国际组织一看,这不行啊,每个地方都各自搞各自的,那么在不同的国家之间就会出现不兼容,我用GBK编码格式写的软件,弄到你编码格式为SJIJ的计算机就不能执行了。所以就出现了Unicode,也称万国码。unicode是用2个字节来表示一个字符的,65536类个字符,这足以覆盖世界上所有的文字。
这样虽好,但是美国人民就不开心了,我一个字母,比如'a'就需要占用一个字节,现在需要占用两个字节,这样就大大的浪费了内存和硬盘的空间,所有后来就出现了UTF-32,UTF-16和UTF-8,前两个这里就不在敖述了,现在并不常用,我们这看看这个UTF-8,UTF-8是一种可变长的编码格式,存储英文字母只需要一个字节,存储汉字需要3个字节,但超大字符集中的更大多数汉字要占4个字节。我们在内存里面的数据是unicode,在传输数据和保存数据的时候使用UTF-8已节省空间和带宽。
Python2的编码
在python2中默认的编码是ASCII,python2的字符串类型有两种:str和Unicode,这两个只是字符串类型的名字,我们主要看它们在内存里面的内存地址:
1 2 3 |
|
'\xe5\xbd\xac\xe5\xbd\xac' #字节数据
u'\u5f6c\u5f6c' #Unicode数据

在python2中,str类型字符串类型在内存中存储的是bytes数据,Unicode类型字符串在内存中存储的是unicode数据。那两种数据之间是什么关系了?这里就涉及到了解码(encode)和编码(decode)了。
1 |
|
由上运行结果可知,unicode转换为bytes数据的过程是编码。从bytes数据转换为unicode数据的过程是解码。我们再来看一下:
1 |
|
我们可以看到得到一堆乱文,name存在内存里的时候是以UTF编码成的bytes数据,而我们这里decode('big5')使用big5来解码,虽然成功了,但是输出结果却不是我们想要的结果。
当我们把第一行coding改为big5的时候就不会出现乱文了,
1 |
|
所以我们用什么规则编码的就要用什么区解码!

注意:我们在终端显示出来的明文,就是你用户所看到的,其实都是已经转换成unicode到内存里面,而bytes数据一般都是计算机识别的。
Python3的编码
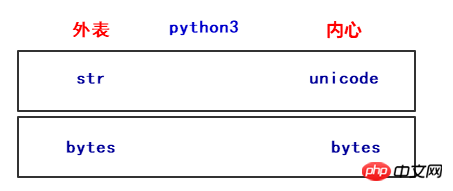
在Python3中也定义了2种类型的字符串类型,str和bytes,str类型存储unicode数据,bytes类型存储bytes数据。
1 2 3 4 5 |
|
如上运行结果,bytes转换为unicode为解码,uicode转为bytes数据类型为编码。

由上图所示,在不同的编码之间转换的时候,我们都要经过unicode这个中转站,没办法,虽然unicode老大哥强大呢,当我们想把utf-8编码的数据转换为gbk的,我们就需要把utf-8的数据先解码成unicode,再由unicode编码成gbk。
在py2和py3中有个重要的区分就是,py2会自动把bytes数据解码成unicode,而py3就不会自动把bytes解码成unicode了。所以说py3更清晰的区分了bytes数据和unicode。
1 |
|
1 |
|
1 2 3 |
|
liubin
一个.py文件的"一生"
那我们创建.py文件,到执行.py文件,这里面的编码和解码是怎么来的呢?
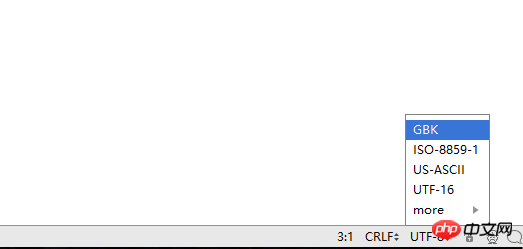
1.当我们创建一个.py文件的时候,会有一个默认的编码格式(这里以pycharm为例),在右下角,默认是UTF-8,当然你也可以选择其他的编码:
2.当我们在.py文件里面写入代码的时候,会以unicode的编码格式保存在内存中;
1 |
|
3.当我们保存的时候,会将Unicode数据编码成utf-8格式的数据,然后保存在硬盘里面;
4.当我们执行文件的时候,pycharm会调用python的解释器来读取文件,在py2中,默认会以ASCII将代码解码成unicode数据,但是ASCII码并不认识中文,所以就会出现报错。
1 |
|
所以,在py2中,我们需要加上:
1 |
|
但是在py3中就不存在这个问题了,只要编码的时候适用的是UTF-8,python3默认的编码规范就是UTF-8,它会用UTF-8来将UTF-8的bytes数据解码成unicode,然后在计算机终端显示!
以上是编码的秘密(python版)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。
热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 怎么在手机上把XML文件转换为PDF?
Apr 02, 2025 pm 10:12 PM
怎么在手机上把XML文件转换为PDF?
Apr 02, 2025 pm 10:12 PM
不可能直接在手机上用单一应用完成 XML 到 PDF 的转换。需要使用云端服务,通过两步走的方式实现:1. 在云端转换 XML 为 PDF,2. 在手机端访问或下载转换后的 PDF 文件。
 手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF的速度取决于以下因素:XML结构的复杂性手机硬件配置转换方法(库、算法)代码质量优化手段(选择高效库、优化算法、缓存数据、利用多线程)总体而言,没有绝对的答案,需要根据具体情况进行优化。
 C语言 sum 的作用是什么?
Apr 03, 2025 pm 02:21 PM
C语言 sum 的作用是什么?
Apr 03, 2025 pm 02:21 PM
C语言中没有内置求和函数,需自行编写。可通过遍历数组并累加元素实现求和:循环版本:使用for循环和数组长度计算求和。指针版本:使用指针指向数组元素,通过自增指针遍历高效求和。动态分配数组版本:动态分配数组并自行管理内存,确保释放已分配内存以防止内存泄漏。
 有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
无法找到一款将 XML 直接转换为 PDF 的应用程序,因为它们是两种根本不同的格式。XML 用于存储数据,而 PDF 用于显示文档。要完成转换,可以使用编程语言和库,例如 Python 和 ReportLab,来解析 XML 数据并生成 PDF 文档。
 xml怎么转换成图片
Apr 03, 2025 am 07:39 AM
xml怎么转换成图片
Apr 03, 2025 am 07:39 AM
可以将 XML 转换为图像,方法是使用 XSLT 转换器或图像库。XSLT 转换器:使用 XSLT 处理器和样式表,将 XML 转换为图像。图像库:使用 PIL 或 ImageMagick 等库,从 XML 数据创建图像,例如绘制形状和文本。
 XML转换成图片的大小如何控制?
Apr 02, 2025 pm 07:24 PM
XML转换成图片的大小如何控制?
Apr 02, 2025 pm 07:24 PM
想要通过XML生成图片,需要使用图形库(如Pillow、JFreeChart)作为桥梁,根据XML中的元数据(尺寸、颜色)生成图片。控制图片大小的关键在于调整XML中<width>和<height>标签的值。然而,在实际应用中,XML结构的复杂性、图形绘制的精细度、图片生成的速度和内存消耗,以及图片格式的选择,都对生成的图片大小产生影响,因此需要深入理解XML结构、熟练掌握图形库,以及考虑优化算法和图片格式选择等因素。
 xml格式化工具推荐
Apr 02, 2025 pm 09:03 PM
xml格式化工具推荐
Apr 02, 2025 pm 09:03 PM
XML格式化工具可以将代码按照规则排版,提高可读性和理解性。选择工具时,要注意自定义能力、对特殊情况的处理、性能和易用性。常用的工具类型包括在线工具、IDE插件和命令行工具。
 有没有手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 09:45 PM
有没有手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 09:45 PM
没有APP可以将所有XML文件转成PDF,因为XML结构灵活多样。XML转PDF的核心是将数据结构转换为页面布局,需要解析XML并生成PDF。常用的方法包括使用Python库(如ElementTree)解析XML,并利用ReportLab库生成PDF。对于复杂XML,可能需要使用XSLT转换结构。性能优化时,考虑使用多线程或多进程,并选择合适的库。
