关于AbstractQueuedSynchronizer
JDK1.5之后引入了并发包java.util.concurrent,大大提高了Java程序的并发性能。关于java.util.concurrent包我总结如下:
AbstractQueuedSynchronizer是并发类诸如ReentrantLock、CountDownLatch、Semphore的核心
CAS算法是AbstractQueuedSynchronizer的核心
可以说AbstractQueuedSynchronizer是并发类的重中之重。其实之前在ReentrantLock实现原理深入探究一文中已经有结合ReentrantLock详细解读过AbstractQueuedSynchronizer,但限于当时水平原因,回看一年半前的此文,感觉对于AbstractQueuedSynchronizer的解读理解还不够深,因此这里更新一篇文章,再次解读AbstractQueuedSynchronizer的数据结构即相关源码实现,本文基于JDK1.7版本。
AbstactQueuedSynchronizer的基本数据结构
AbstractQueuedSynchronizer的基本数据结构为Node,关于Node,JDK作者写了详细的注释,这里我大致总结几点:
AbstractQueuedSynchronizer的等待队列是CLH队列的变种,CLH队列通常用于自旋锁,AbstractQueuedSynchronizer的等待队列用于阻塞同步器
每个节点中持有一个名为"status"的字段用于是否一条线程应当阻塞的追踪,但是status字段并不保证加锁
一条线程如果它处于队列的头,那么他会尝试去acquire,但是成为头并不保证成功,它只是有权利去竞争
要进入队列,你只需要自动将它拼接在队列尾部即可;要从队列中移除,你只需要设置header字段
下面我用一张表格总结一下Node中持有哪些变量且每个变量的含义:
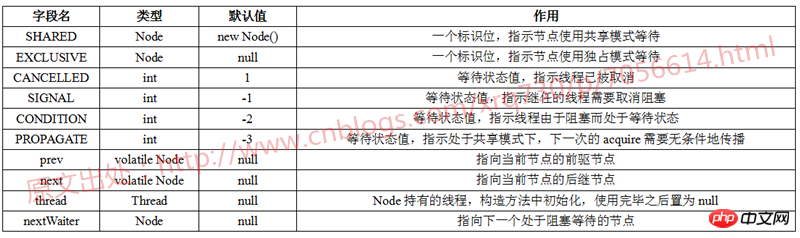
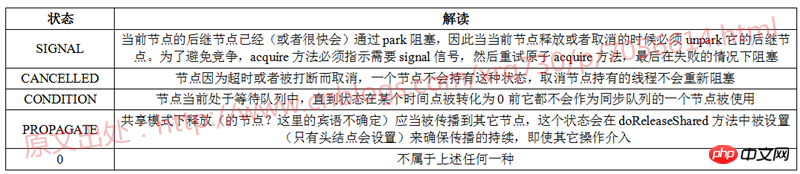
关于SIGNAL、CANCELLED、CONDITION、PROPAGATE四个状态,JDK源码的注释中同样有了详细的解读,再用一张表格总结一下:
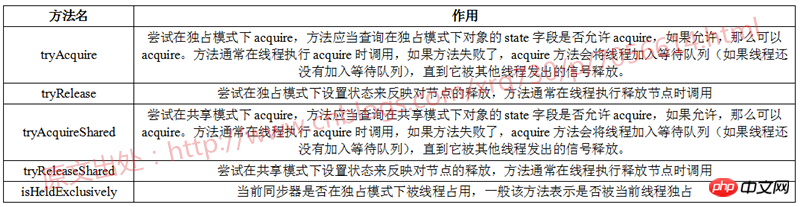
AbstractQueuedSynchronizer供子类实现的方法
AbstractQueuedSynchzonizer是基于模板模式的实现,不过它的模板模式写法有点特别,整个类中没有任何一个abstract的抽象方法,取而代之的是,需要子类去实现的那些方法通过一个方法体抛出UnsupportedOperationException异常来让子类知道。
AbstractQueuedSynchronizer类中一共有五处方法供子类实现,用表格总结一下:
这里的acquire不好翻译,所以就直接原词放上来了,因为acquire是一个动词,后面并没有带宾语,因此不知道具体acquire的是什么。按照我个人理解,acquire的意思应当是根据状态字段state去获取一个执行当前动作的资格。
比如ReentrantLock的lock()方法最终会调用acquire方法,那么:
线程1去lock(),执行acquire,发现state=0,因此有资格执行lock()的动作,将state设置为1,返回true
线程2去lock(),执行acquire,发现state=1,因此没有资格执行lock()的动作,返回false
这种理解我认为应当是比较准确的。
独占模式acquire实现流程
有了上面的这些基础,我们看一下独占式acquire的实现流程,主要是在线程acquire失败后,是如何构建数据结构的,先看理论,之后再用一个例子画图说明。
看一下AbstractQuueuedSynchronizer的acquire方法实现流程,acquire方法是用于独占模式下进行操作的:
1 public final void acquire(int arg) { 2 if (!tryAcquire(arg) && 3 acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) 4 selfInterrupt(); 5 }tryAcquire方法前面说过了,是子类实现的一个方法,如果tryAcquire返回的是true(成功),即表明当前线程获得了一个执行当前动作的资格,自然也就不需要构建数据结构进行阻塞等待。
如果tryAcquire方法返回的是false,那么当前线程没有获得执行当前动作的资格,接着执行"acquireQueued(addWaiter(Node.EXCLUSIVE), arg))"这句代码,这句话很明显,它是由两步构成的:
addWaiter,添加一个等待者
acquireQueued,尝试从等待队列中去获取执行一次acquire动作
分别看一下每一步做了什么。
addWaiter
先看第一步,addWaiter做了什么,从传入的参数Node.EXCLUSIVE我们知道这是独占模式的:
1 private Node addWaiter(Node mode) { 2 Node node = new Node(Thread.currentThread(), mode); 3 // Try the fast path of enq; backup to full enq on failure 4 Node prev = tail; 5 if (prev != null) { 6 node.prev = prev; 7 if (compareAndSetTail(prev, node)) { 8 prev.next = node; 9 return node;10 }11 }12 enq(node);13 return node;14 }首先看第4行~第11行的代码,获得当前数据结构中的尾节点,如果有尾节点,那么先获取这个节点认为它是前驱节点prev,然后:
新生成的Node的前驱节点指向prev
并发下只有一条线程可以通过CAS算法让自己的Node成为尾节点,此时将此prev的next指向该线程对应的Node
因此在数据结构中有节点的情况下,所有新增节点都是作为尾节点插入数据结构。从注释上来看,这段逻辑的存在的意义是以最短路径O(1)的效果完成快速入队,以最大化减小开销。
假如当前节点没有被设置为尾节点,那么执行enq方法:
1 private Node enq(final Node node) { 2 for (;;) { 3 Node t = tail; 4 if (t == null) { // Must initialize 5 if (compareAndSetHead(new Node())) 6 tail = head; 7 } else { 8 node.prev = t; 9 if (compareAndSetTail(t, node)) {10 t.next = node;11 return t;12 }13 }14 }15 }这段代码的逻辑为:
如果尾节点为空,即当前数据结构中没有节点,那么new一个不带任何状态的Node作为头节点
如果尾节点不为空,那么并发下使用CAS算法将当前Node追加成为尾节点,由于是一个for(;;)循环,因此所有没有成功acquire的Node最终都会被追加到数据结构中
看完了代码,用一张图表示一下AbstractQueuedSynchronizer的整体数据结构(比较简单,就不自己画了,网上随便找了一张图):

acquireQueued
队列构建好了,下一步就是在必要的时候从队列里面拿出一个Node了,这就是acquireQueued方法,顾名思义,从队列里面acquire。看下acquireQueued方法的实现:
1 final boolean acquireQueued(final Node node, int arg) { 2 boolean failed = true; 3 try { 4 boolean interrupted = false; 5 for (;;) { 6 final Node p = node.prevecessor(); 7 if (p == head && tryAcquire(arg)) { 8 setHead(node); 9 p.next = null; // help GC10 failed = false;11 return interrupted;12 }13 if (shouldParkAfterFailedAcquire(p, node) &&14 parkAndCheckInterrupt())15 interrupted = true;16 }17 } finally {18 if (failed)19 cancelAcquire(node);20 }21 }这段代码描述了几件事:
从第6行的代码获取节点的前驱节点p,第7行的代码判断p是前驱节点并tryAcquire我们知道,只有当前第一个持有Thread的节点才会尝试acquire,如果节点acquire成功,那么setHead方法,将当前节点作为head、将当前节点中的thread设置为null、将当前节点的prev设置为null,这保证了数据结构中头结点永远是一个不带Thread的空节点
如果当前节点不是前驱节点或者tryAcquire失败,那么执行第13行~第15行的代码,做了两步操作,首先判断在acquie失败后是否应该park,其次park并检查中断状态
看一下第一步shouldParkAfterFailedAcquire代码做了什么:
1 private static boolean shouldParkAfterFailedAcquire(Node prev, Node node) { 2 int ws = prev.waitStatus; 3 if (ws == Node.SIGNAL) 4 /* 5 * This node has already set status asking a release 6 * to signal it, so it can safely park. 7 */ 8 return true; 9 if (ws > 0) {10 /*11 * prevecessor was cancelled. Skip over prevecessors and12 * indicate retry.13 */14 do {15 node.prev = prev = prev.prev;16 } while (prev.waitStatus > 0);17 prev.next = node;18 } else {19 /*20 * waitStatus must be 0 or PROPAGATE. Indicate that we21 * need a signal, but don't park yet. Caller will need to22 * retry to make sure it cannot acquire before parking.23 */24 compareAndSetWaitStatus(prev, ws, Node.SIGNAL);25 }26 return false;27 }这里每个节点判断它前驱节点的状态,如果:
它的前驱节点是SIGNAL状态的,返回true,表示当前节点应当park
它的前驱节点的waitStatus>0,相当于CANCELLED(因为状态值里面只有CANCELLED是大于0的),那么CANCELLED的节点作废,当前节点不断向前找并重新连接为双向队列,直到找到一个前驱节点waitStats不是CANCELLED的为止
它的前驱节点不是SIGNAL状态且waitStatus<=0,此时执行第24行代码,利用CAS机制,如果waitStatus的前驱节点是0那么更新为SIGNAL状态
如果判断判断应当park,那么parkAndCheckInterrupt方法:
LockSupport.park(
利用LockSupport的park方法让当前线程阻塞。
独占模式release流程
上面整理了独占模式的acquire流程,看到了等待的Node是如何构建成一个数据结构的,下面看一下释放的时候做了什么,release方法的实现为:
1 public final boolean release(int arg) {2 if (tryRelease(arg)) {3 Node h = head;4 if (h != null && h.waitStatus != 0)5 unparkSuccessor(h);6 return true;7 }8 return false;9 }tryRelease同样是子类去实现的,表示当前动作我执行完了,要释放我执行当前动作的资格,讲这个资格让给其它线程,然后tryRelease释放成功,获取到head节点,如果head节点的waitStatus不为0的话,执行unparkSuccessor方法,顾名思义unparkSuccessor意为unpark头结点的继承者,方法实现为:
1 private void unparkSuccessor(Node node) { 2 /* 3 * If status is negative (i.e., possibly needing signal) try 4 * to clear in anticipation of signalling. It is OK if this 5 * fails or if status is changed by waiting thread. 6 */ 7 int ws = node.waitStatus; 8 if (ws < 0) 9 compareAndSetWaitStatus(node, ws, 0);10 11 /*12 * Thread to unpark is held in successor, which is normally13 * just the next node. But if cancelled or apparently null,14 * traverse backwards from tail to find the actual15 * non-cancelled successor.16 */17 Node s = node.next;18 if (s == null || s.waitStatus > 0) {19 s = null;20 for (Node t = tail; t != null && t != node; t = t.prev)21 if (t.waitStatus <= 0)22 s = t;23 }24 if (s != null)25 LockSupport.unpark(s.thread);26 }这段代码比较好理解,整理一下流程:
头节点的waitStatus<0,将头节点的waitStatus设置为0
拿到头节点的下一个节点s,如果s==null或者s的waitStatus>0(被取消了),那么从队列尾巴开始向前寻找一个waitStatus<=0的节点作为后继要唤醒的节点
最后,如果拿到了一个不等于null的节点s,就利用LockSupport的unpark方法让它取消阻塞。
实战举例:数据结构构建
上面的例子讲解地过于理论,下面利用ReentrantLock举个例子,但是这里不讲ReentrantLock实现原理,只是利用ReentrantLock研究AbstractQueuedSynchronizer的acquire和release。示例代码为:
1 /** 2 * @author 五月的仓颉 3 */ 4 public class AbstractQueuedSynchronizerTest { 5 6 @Test 7 public void testAbstractQueuedSynchronizer() { 8 Lock lock = new ReentrantLock(); 9 10 Runnable runnable0 = new ReentrantLockThread(lock);11 Thread thread0 = new Thread(runnable0);12 thread0.setName("线程0");13 14 Runnable runnable1 = new ReentrantLockThread(lock);15 Thread thread1 = new Thread(runnable1);16 thread1.setName("线程1");17 18 Runnable runnable2 = new ReentrantLockThread(lock);19 Thread thread2 = new Thread(runnable2);20 thread2.setName("线程2");21 22 thread0.start();23 thread1.start();24 thread2.start();25 26 for (;;);27 }28 29 private class ReentrantLockThread implements Runnable {30 31 private Lock lock;32 33 public ReentrantLockThread(Lock lock) {34 this.lock = lock;35 }36 37 @Override38 public void run() {39 try {40 lock.lock();41 for (;;);42 } finally {43 lock.unlock();44 }45 }46 47 }48 49 }全部是死循环,相当于第一条线程(线程0)acquire成功之后,后两条线程(线程1、线程2)阻塞,下面的代码就不考虑后两条线程谁先谁后的问题,就一条线程(线程1)流程执行到底、另一条线程(线程2)流程执行到底这么分析了。
这里再把addWaiter和enq两个方法源码贴一下:
1 private Node addWaiter(Node mode) { 2 Node node = new Node(Thread.currentThread(), mode); 3 // Try the fast path of enq; backup to full enq on failure 4 Node prev = tail; 5 if (prev != null) { 6 node.prev = prev; 7 if (compareAndSetTail(prev, node)) { 8 prev.next = node; 9 return node;10 }11 }12 enq(node);13 return node;14 } 1 private Node enq(final Node node) { 2 for (;;) { 3 Node t = tail; 4 if (t == null) { // Must initialize 5 if (compareAndSetHead(new Node())) 6 tail = head; 7 } else { 8 node.prev = t; 9 if (compareAndSetTail(t, node)) {10 t.next = node;11 return t;12 }13 }14 }15 }首先第一个acquire失败的线程1,由于此时整个数据结构中么没有任何数据,因此addWaiter方法第4行中拿到的prev=tail为空,执行enq方法,首先第3行获取tail,第4行判断到tail是null,因此头结点new一个Node出来通过CAS算法设置为数据结构的head,tail同样也是这个Node,此时数据结构为:

为了方便描述,prev和next,我给每个Node随便加了一个地址。接着继续enq,因为enq内是一个死循环,所以继续第3行获取tail,new了一个空的Node之后tail就有了,执行else判断,通过第8行~第10行代码将当前线程对应的Node追加到数据结构尾部,那么当前构建的数据结构为:
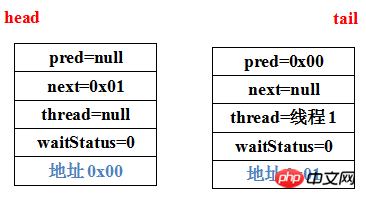
这样,线程1对应的Node被加入数据结构,成为数据结构的tail,而数据结构的head是一个什么都没有的空Node。
接着线程2也acquire失败了,线程2既然acquire失败,那也要准备被加入数据结构中,继续先执行addWaiter方法,由于此时已经有了tail,因此不需要执行enq方法,可以直接将当前Node添加到数据结构尾部,那么当前构建的数据结构为:

至此,两个阻塞的线程构建的三个Node已经全部归位。
实战举例:线程阻塞
上述流程只是描述了构建数据结构的过程,并没有描述线程1、线程2阻塞的流程,因此接着继续用实际例子看一下线程1、线程2如何阻塞。贴一下acquireQueued、shouldParkAfterFailedAcquire两个方法源码:
1 final boolean acquireQueued(final Node node, int arg) { 2 boolean failed = true; 3 try { 4 boolean interrupted = false; 5 for (;;) { 6 final Node p = node.prevecessor(); 7 if (p == head && tryAcquire(arg)) { 8 setHead(node); 9 p.next = null; // help GC10 failed = false;11 return interrupted;12 }13 if (shouldParkAfterFailedAcquire(p, node) &&14 parkAndCheckInterrupt())15 interrupted = true;16 }17 } finally {18 if (failed)19 cancelAcquire(node);20 }21 } 1 private static boolean shouldParkAfterFailedAcquire(Node prev, Node node) { 2 int ws = prev.waitStatus; 3 if (ws == Node.SIGNAL) 4 /* 5 * This node has already set status asking a release 6 * to signal it, so it can safely park. 7 */ 8 return true; 9 if (ws > 0) {10 /*11 * prevecessor was cancelled. Skip over prevecessors and12 * indicate retry.13 */14 do {15 node.prev = prev = prev.prev;16 } while (prev.waitStatus > 0);17 prev.next = node;18 } else {19 /*20 * waitStatus must be 0 or PROPAGATE. Indicate that we21 * need a signal, but don't park yet. Caller will need to22 * retry to make sure it cannot acquire before parking.23 */24 compareAndSetWaitStatus(prev, ws, Node.SIGNAL);25 }26 return false;27 }<p><span style="font-size: 13px; font-family: 宋体">首先是线程1,它的前驱节点是head节点,在它tryAcquire成功的情况下,执行第8行~第11行的代码。做几件事情:</span></p>
<ol class=" list-paddingleft-2">
<li><p><span style="font-size: 13px; font-family: 宋体">head为线程1对应的Node</span></p></li>
<li><p><span style="font-size: 13px; font-family: 宋体">线程1对应的Node的thread置空</span></p></li>
<li><p><span style="font-size: 13px; font-family: 宋体">线程1对应的Node的prev置空</span></p></li>
<li><p><span style="font-size: 13px; font-family: 宋体">原head的next置空,这样原head中的prev、next、thread都为空,对象内没有引用指向其他地方,GC可以认为这个Node是垃圾,对这个Node进行回收,注释"Help GC"就是这个意思</span></p></li>
<li><p><span style="font-size: 13px; font-family: 宋体">failed=false表示没有失败</span></p></li>
</ol>
<p><span style="font-size: 13px; font-family: 宋体">因此,如果线程1执行tryAcquire成功,那么数据结构将变为:</span></p>
<p><span style="font-size: 13px; font-family: 宋体"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/3d801230fc075de2d75122d27258c2ad-7.png" class="lazy" alt=""></span></p>
<p><span style="font-size: 13px; font-family: 宋体">从上述流程可以总结到:<span style="color: #ff0000"><strong>只有前驱节点为head的节点会尝试tryAcquire,其余都不会,结合后面的release选继承者的方式,保证了先acquire失败的线程会优先从阻塞状态中解除去重新acquire</strong></span>。这是一种公平的acquire方式,因为它遵循"先到先得"原则,但是我们可以动动手脚让这种公平变为非公平,比如ReentrantLock默认的费公平模式,这个留在后面说。</span></p>
<p><span style="font-size: 13px; font-family: 宋体">那如果线程1执行tryAcquire失败,那么要执行shouldParkAfterFailedAcquire方法了,shouldParkAfterFailedAcquire拿线程1的前驱节点也就是head节点的waitStatus做了一个判断,因为waitStatus=0,因此执行第18行~第20行的逻辑,将head的waitStatus设置为SIGNAL即-1,然后方法返回false,数据结构变为:</span></p>
<p><span style="font-size: 13px; font-family: 宋体"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/3d801230fc075de2d75122d27258c2ad-8.png" class="lazy" alt=""></span></p>
<p><span style="font-size: 13px; font-family: 宋体">看到这里就一个变化:head的waitStatus从0变成了-1。既然shouldParkAfterFailedAcquire返回false,acquireQueued的第13行~第14行的判断自然不通过,继续走for(;;)循环,如果tryAcquire失败显然又来到了shouldParkAfterFailedAcquire方法,此时线程1对应的Node的前驱节点head节点的waitStatus已经变为了SIGNAL即-1,因此执行第4行~第8行的代码,直接返回true出去。</span></p>
<p><span style="font-size: 13px; font-family: 宋体">shouldParkAfterFailedAcquire返回true,parkAndCheckInterrupt直接调用LockSupport的park方法:</span></p>
<div class="cnblogs_code"><pre class="brush:php;toolbar:false"> 1 private final boolean parkAndCheckInterrupt() { 2 LockSupport.park(this); 3 return Thread.interrupted(); 4 }至此线程1阻塞,线程2阻塞的流程与线程1阻塞的流程相同,可以自己分析一下。
另外再提一个问题,不知道大家会不会想:
为什么线程1对应的Node构建完毕不直接调用LockSupport的park方法进行阻塞?
为什么不直接把head的waitStatus直接设置为Signal而要从0设置为Signal?
我认为这是AbstractQueuedSynchronizer开发人员做了类似自旋的操作。因为很多时候获取acquire进行操作的时间很短,阻塞会引起上下文的切换,而很短时间就从阻塞状态解除,这样相对会比较耗费性能。
因此我们看到线程1自构建完毕Node加入数据结构到阻塞,一共尝试了两次tryAcquire,如果其中有一次成功,那么线程1就没有必要被阻塞,提升了性能。
以上是剖析AbstractQueuedSynchronizer:独占模式重难点的详细内容。更多信息请关注PHP中文网其他相关文章!





















