

Python中基本的数据结构--列表

Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推
列表
1、定义列表,取出列表中的值
1 names = [] #定义空列表 2 names = ['a','b','c'] #定义一个非空列表 3 4 # 取出列表中的值 5 6 >>> names = ['a','b','c'] 7 >>> names[0] 8 'a' 9 >>> names[1]10 'b'11 >>> names[2]12 'c'13 >>> names[-1]#倒着取最后一个值14 'c'
2、切片
1 >>> names = ['a','b','c','d'] # 列表的下标值是从0开始取值的 2 >>> names[1:3] #取1到3之间的元素,包括1,不包括3 3 ['b', 'c'] 4 >>> names[1:-1] #取1到-1之间的元素,包括1,不包括-1 5 ['b', 'c'] 6 >>> names[0:3] 7 ['a', 'b', 'c'] 8 >>> names[:3] #从头开始取,0可以省略,效果等同于names[0:3] 9 ['a', 'b', 'c']10 >>> names[3:] #想取到最后一个值,必须不能写-1,只能这么写11 ['d']12 >>> names[0::2] #后面的2表示:每隔一个元素就取一个13 ['a', 'c']14 >>> names[::2] #从头开始0可以省略,效果跟上一句一样15 ['a', 'c']
切片小结:
①序列始终都是从左向右切片的,不能是从右向左
①列表切片时,起始位的元素是包括的,结束位的元素是不包括(又叫顾头不顾尾),最后一个位置表示步长(names[开始位:结束位:步长])
②如果从0位置取值,0可以省略
③想取最后一个值时,结束位不能是-1,因为结束位的元素不包括,所以只能留空
3、列表函数&方法
函数:
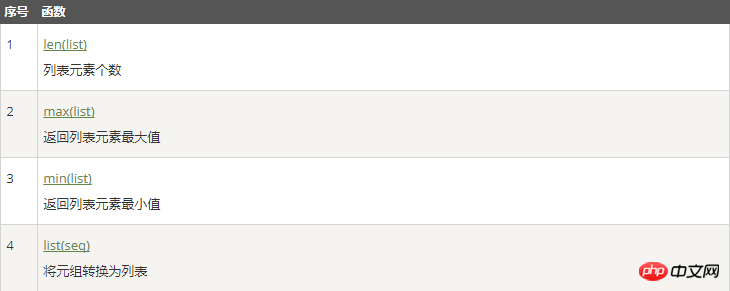
方法:
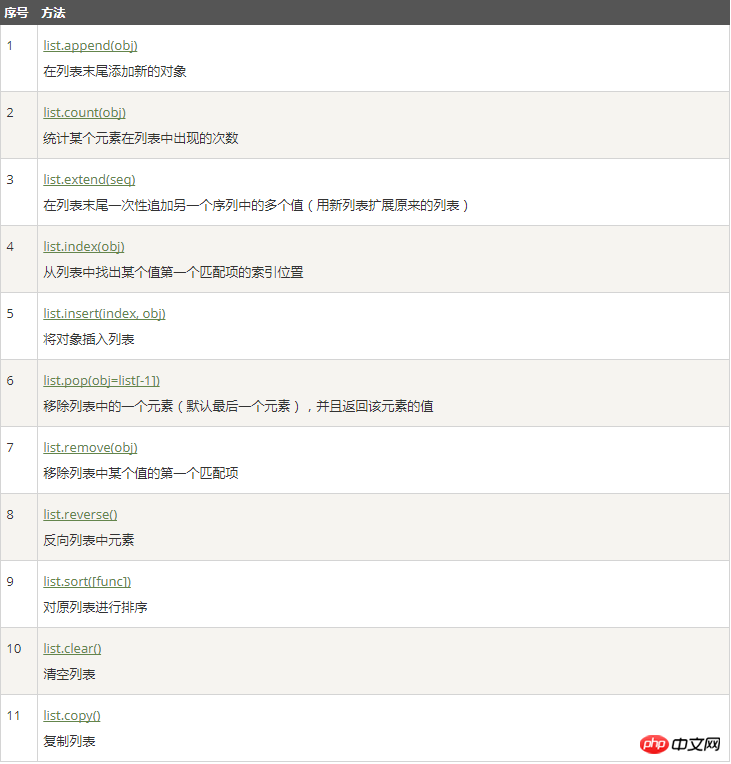
演示:
1 # append 列表末尾添加新的对象 2 >>> names = ['a','b','c','d'] 3 >>> names.append('e') 4 >>> names 5 ['a', 'b', 'c', 'd', 'e']#e是新加的元素 6 7 # insert(下标值,插入的内容) 8 >>> names = ['a','b','c','d'] 9 >>> names.insert(0,'1') #0表示需要插入的下标值,'1'表示插入的内容10 >>> names11 ['1', 'a', 'b', 'c', 'd'] #在下标值为0的地方插入'1'12 13 #修改列表中的元素,直接是 names[下标值] = 新值14 >>> names = ['a','b','c','d']15 >>> names[1] = '1'16 >>> names17 ['a', '1', 'c', 'd']18 19 20 #扩展(extend)names2的列表合并到names1中,但是,names2这个列表依然存在,如果想删除names2这个变量,则只需del names2即可21 >>> names1 = ['a','b','c','d']22 >>> names2 = [1,2,3,4]23 >>> names1.extend(names2)24 >>> names125 ['a', 'b', 'c', 'd', 1, 2, 3, 4]26 27 #统计(count(元素))28 >>> names = ['a','b','c','d','a']29 >>> names.count('a') #统计'a'元素的个数30 231 32 #翻转(reverse())33 >>> names = ['a','b','c','d']34 >>> names.reverse()35 >>> names36 ['d', 'c', 'b', 'a'] #将整个列表翻转过来37 38 #排序(sort())39 >>> names = [4,2,3,1]40 >>> names.sort()41 >>> names42 [1, 2, 3, 4]43 44 #获取下标值(index(元素))45 >>> names = ['a','b','c','d']46 >>> names.index('a')47 048 49 #清空列表(clear())50 >>> names = ['a','b','c','d']51 >>> names.clear()52 >>> names53 []删除(del、remove(元素)、pop())
#根据下标值删除元素>>> names = ['a','b','c','d']>>> del names[0]
>>> names
['b', 'c', 'd']#根据元素删除>>> names = ['a','b','c','d']>>> names.remove('a')>>> names
['b', 'c', 'd']#删除最后一个>>> names = ['a','b','c','d']>>> names.pop()'d'>>> names
['a', 'b', 'c']扩展:
#如果pop()中有下标值,则是删掉具体某个元素,其效果和del的效果是一样的>>> names = ['a','b','c','d']>>> names.pop(1) #在输入下标值得情况下和del的效果是一样的'b'>>> names ['a', 'c', 'd']#del关键字不仅可以删除列表中的元素,也可以删除变量names = ['a','b','c','d']#删除names这个变量del names
copy:
1 >>> names = ['a','b','c','d']2 >>> names2 = names.copy()3 >>> names24 ['a', 'b', 'c', 'd']
注:这边的copy都是浅copy,只能copy第一层。深浅拷贝的详细信息:点击这里
以上是Python中基本的数据结构--列表的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 C语言 sum 的作用是什么?
Apr 03, 2025 pm 02:21 PM
C语言 sum 的作用是什么?
Apr 03, 2025 pm 02:21 PM
C语言中没有内置求和函数,需自行编写。可通过遍历数组并累加元素实现求和:循环版本:使用for循环和数组长度计算求和。指针版本:使用指针指向数组元素,通过自增指针遍历高效求和。动态分配数组版本:动态分配数组并自行管理内存,确保释放已分配内存以防止内存泄漏。
 谁得到更多的Python或JavaScript?
Apr 04, 2025 am 12:09 AM
谁得到更多的Python或JavaScript?
Apr 04, 2025 am 12:09 AM
Python和JavaScript开发者的薪资没有绝对的高低,具体取决于技能和行业需求。1.Python在数据科学和机器学习领域可能薪资更高。2.JavaScript在前端和全栈开发中需求大,薪资也可观。3.影响因素包括经验、地理位置、公司规模和特定技能。
 H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面需要持续维护,这是因为代码漏洞、浏览器兼容性、性能优化、安全更新和用户体验提升等因素。有效维护的方法包括建立完善的测试体系、使用版本控制工具、定期监控页面性能、收集用户反馈和制定维护计划。
 distinctIdistinguish有关系吗
Apr 03, 2025 pm 10:30 PM
distinctIdistinguish有关系吗
Apr 03, 2025 pm 10:30 PM
distinct 和 distinguish 虽都与区分有关,但用法不同:distinct(形容词)描述事物本身的独特性,用于强调事物之间的差异;distinguish(动词)表示区分行为或能力,用于描述辨别过程。在编程中,distinct 常用于表示集合中元素的唯一性,如去重操作;distinguish 则体现在算法或函数的设计中,如区分奇数和偶数。优化时,distinct 操作应选择合适的算法和数据结构,而 distinguish 操作应优化区分逻辑效率,并注意编写清晰可读的代码。
 如何理解 C 语言中的 !x?
Apr 03, 2025 pm 02:33 PM
如何理解 C 语言中的 !x?
Apr 03, 2025 pm 02:33 PM
!x 的理解!x 是 C 语言中的逻辑非运算符,对 x 的值进行布尔取反,即真变假,假变真。但要注意,C 语言中真假由数值而非布尔类型表示,非零视为真,只有 0 才视为假。因此,!x 对负数的处理与正数相同,都视为真。
 C语言中 sum 是什么意思?
Apr 03, 2025 pm 02:36 PM
C语言中 sum 是什么意思?
Apr 03, 2025 pm 02:36 PM
C语言中没有内置的sum函数用于求和,但可以通过以下方法实现:使用循环逐个累加元素;使用指针逐个访问并累加元素;对于大数据量,考虑并行计算。
 如何获取58同城工作页面上的实时申请和浏览人数数据?
Apr 05, 2025 am 08:06 AM
如何获取58同城工作页面上的实时申请和浏览人数数据?
Apr 05, 2025 am 08:06 AM
如何在爬虫时获取58同城工作页面的动态数据?在使用爬虫工具爬取58同城的某个工作页面时,可能会遇到这样�...
 PS一直显示正在载入是什么原因?
Apr 06, 2025 pm 06:39 PM
PS一直显示正在载入是什么原因?
Apr 06, 2025 pm 06:39 PM
PS“正在载入”问题是由资源访问或处理问题引起的:硬盘读取速度慢或有坏道:使用CrystalDiskInfo检查硬盘健康状况并更换有问题的硬盘。内存不足:升级内存以满足PS对高分辨率图片和复杂图层处理的需求。显卡驱动程序过时或损坏:更新驱动程序以优化PS和显卡之间的通信。文件路径过长或文件名有特殊字符:使用简短的路径和避免使用特殊字符。PS自身问题:重新安装或修复PS安装程序。
