
这篇文章主要跟大家介绍了关于Python MySQL数据库连接池组件pymysqlpool的相关资料,文中通过示例代码介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。
引言
pymysqlpool (本地下载)是数据库工具包中新成员,目的是能提供一个实用的数据库连接池中间件,从而避免在应用中频繁地创建和释放数据库连接资源。
功能
连接池本身是线程安全的,可在多线程环境下使用,不必担心连接资源被多个线程共享的问题;
提供尽可能紧凑的接口用于数据库操作;
连接池的管理位于包内完成,客户端可以通过接口获取池中的连接资源(返回 pymysql.Connection);
将最大程度地与 dataobj 等兼容,便于使用;
连接池本身具备动态增加连接数的功能,即 max_pool_size 和 step_size 会用于控制每次增加的连接数和最大连接数;
连接池最大连接数亦动态增加,需要开启 enable_auto_resize 开关,此后当任何一次连接获取超时发生,均记为一次惩罚,并且将 max_pool_size 扩大一定倍数。
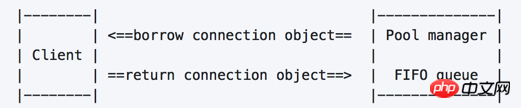
基本工作流程
注意,当多线程同时请求时,若池中没有可用的连接对象,则需要排队等待
初始化后优先创建 step_size 个连接对象,放在连接池中;
客户端请求连接对象,连接池会从中挑选最近没使用的连接对象返回(同时会检查连接是否正常);
客户端使用连接对象,执行相应操作后,调用接口返回连接对象;
连接池回收连接对象,并将其加入池中的队列,供其它请求使用。
|--------| |--------------| | | <==borrow connection object== | Pool manager | | Client | | | | | ==return connection object==> | FIFO queue | |--------| |--------------|
参数配置
pool_name: 连接池的名称,多种连接参数对应多个不同的连接池对象,多单例模式;
host: 数据库地址
user: 数据库服务器用户名
password: 用户密码
database: 默认选择的数据库
port: 数据库服务器的端口
charset: 字符集,默认为 ‘utf8'
use_dict_cursor: 使用字典格式或者元组返回数据;
max_pool_size: 连接池优先最大连接数;
step_size: 连接池动态增加连接数大小;
enable_auto_resize: 是否动态扩展连接池,即当超过 max_pool_size 时,自动扩展 max_pool_size;
pool_resize_boundary: 该配置为连接池最终可以增加的上上限大小,即时扩展也不可超过该值;
auto_resize_scale: 自动扩展 max_pool_size 的增益,默认为 1.5 倍扩展;
wait_timeout: 在排队等候连接对象时,最多等待多久,当超时时连接池尝试自动扩展当前连接数;
kwargs: 其他配置参数将会在创建连接对象时传递给 pymysql.Connection
1、使用 cursor 上下文管理器(快捷方式,但每次获取都会申请连接对象,多次调用效率不高):
from pymysqlpool import ConnectionPool
config = {
'pool_name': 'test',
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root',
'database': 'test'
}
def connection_pool():
# Return a connection pool instance
pool = ConnectionPool(**config)
pool.connect()
return pool
# 直接访问并获取一个 cursor 对象,自动 commit 模式会在这种方式下启用
with connection_pool().cursor() as cursor:
print('Truncate table user')
cursor.execute('TRUNCATE user')
print('Insert one record')
result = cursor.execute('INSERT INTO user (name, age) VALUES (%s, %s)', ('Jerry', 20))
print(result, cursor.lastrowid)
print('Insert multiple records')
users = [(name, age) for name in ['Jacky', 'Mary', 'Micheal'] for age in range(10, 15)]
result = cursor.executemany('INSERT INTO user (name, age) VALUES (%s, %s)', users)
print(result)
print('View items in table user')
cursor.execute('SELECT * FROM user')
for user in cursor:
print(user)
print('Update the name of one user in the table')
cursor.execute('UPDATE user SET name="Chris", age=29 WHERE id = 16')
cursor.execute('SELECT * FROM user ORDER BY id DESC LIMIT 1')
print(cursor.fetchone())
print('Delete the last record')
cursor.execute('DELETE FROM user WHERE id = 16')2、使用 connection 上下文管理器:
import pandas as pd
from pymysqlpool import ConnectionPool
config = {
'pool_name': 'test',
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root',
'database': 'test'
}
def connection_pool():
# Return a connection pool instance
pool = ConnectionPool(**config)
pool.connect()
return pool
with connection_pool().connection() as conn:
pd.read_sql('SELECT * FROM user', conn)
# 或者
connection = connection_pool().borrow_connection()
pd.read_sql('SELECT * FROM user', conn)
connection_pool().return_connection(connection)更多测试请移步 test_example.py。
依赖
pymysql:将依赖该工具包完成数据库的连接等操作;
pandas:测试时使用了 pandas。
以上是Python MySQL数据库中pymysqlpool是如何使用的?的详细内容。更多信息请关注PHP中文网其他相关文章!





















