

Pandas数据处理实例展示:全球上市公司数据整理
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用。
本文通过实例操作来介绍用pandas进行数据整理。
照例先说下我的运行环境,如下:
windows 7, 64位
python 3.5
pandas 0.19.2版本
在拿到原始数据后,我们先来看看数据的情况,并思考下我们需要什么样的数据结果。
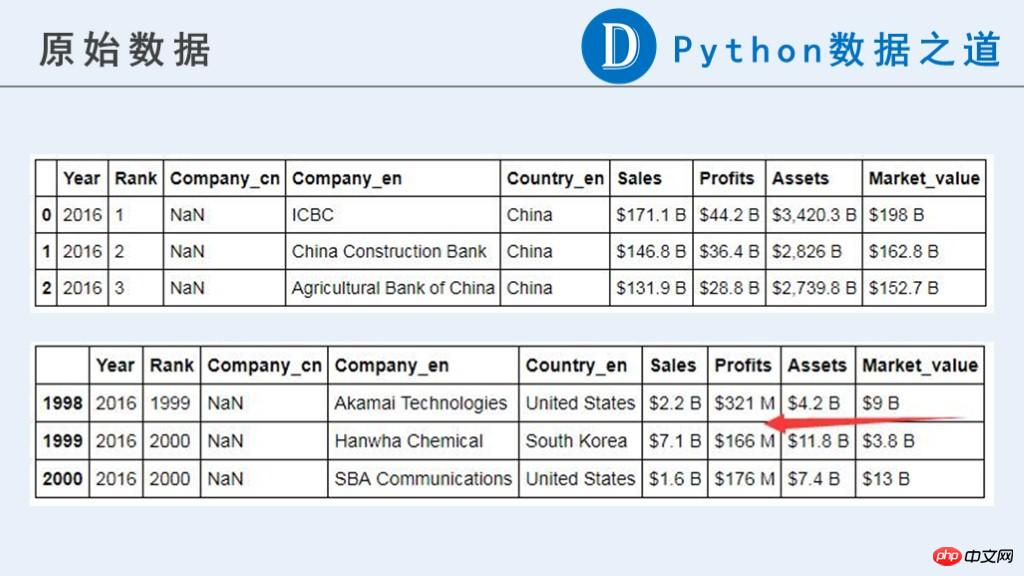
下面是原始数据:
在本文中,我们需要以下的初步结果,以供以后继续使用。
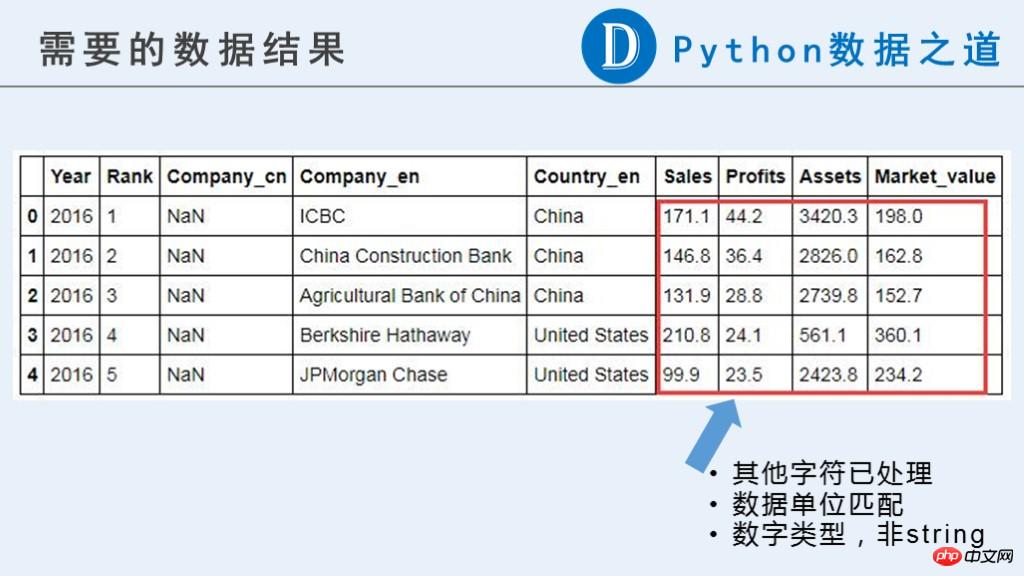
可以看到,原始数据中,跟企业相关的数据中(“Sales”,“Profits”,“Assets”,“Market_value”),目前都是不是可以用来计算的数字类型。
原始内容中包含货币符号”$“,“-”,纯字母组成的字符串以及其他一些我们认为异常的信息。更重要的是,这些数据的单位并不一致。分别有以“B”(Billion,十亿)和“M”(Million,百万)表示的。在后续计算之前需要进行单位统一。
1 处理方法 Method-1
首先想到的处理思路就是将数据信息分别按十亿(’B’)和百万(‘M’)进行拆分,分别进行处理,最后在合并到一起。过程如下所示。
加载数据,并添加列的名称
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)获取单位为十亿(’B’)的数据
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_b获取单位为百万(‘M’)的数据
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_m这种方法理解起来比较简单,但操作起来会比较繁琐,尤其是如果有很多列数据需要处理的话,会花费很多时间。
进一步的处理,我这里就不描述了。当然,各位可以试试这个方法。
下面介绍稍微简单一点的方法。
2 处理方法 Method-2
2.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
下面来处理’Sales’列
2.2 替换相关的异常字符
首先是替换相关的异常字符,包括美元的货币符号’$’,纯字母的字符串’undefined’,以及’B’。 这里,我们想统一把数据的单位整理成十亿,所以’B’可以直接进行替换。而’M’需要更多的处理步骤。
2.3 处理’M’相关的数据
处理含有百万“M”为单位的数据,即以“M”结尾的数据,思路如下:
(1)设定查找条件mask;
(2)替换字符串“M”为空值
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
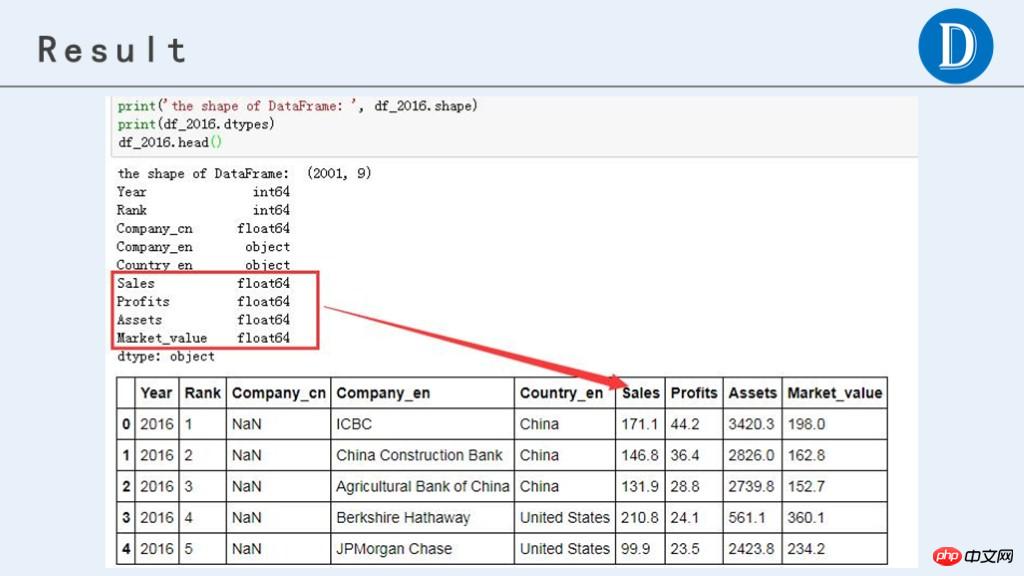
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()最终处理后,获得的数据结果如下:
以上是Pandas数据处理实例展示:全球上市公司数据整理的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 解决常见的pandas安装问题:安装错误的解读和解决方法
Feb 19, 2024 am 09:19 AM
解决常见的pandas安装问题:安装错误的解读和解决方法
Feb 19, 2024 am 09:19 AM
pandas安装教程:解析常见安装错误及其解决方法,需要具体代码示例引言:Pandas是一个强大的数据分析工具,广泛应用于数据清洗、数据处理和数据可视化等方面,因此在数据科学领域备受推崇。然而,由于环境配置和依赖问题,安装pandas可能会遇到一些困难和错误。本文将为大家提供一份pandas安装教程,并解析一些常见的安装错误及其解决方法。一、安装pandas
 如何使用pandas正确读取txt文件
Jan 19, 2024 am 08:39 AM
如何使用pandas正确读取txt文件
Jan 19, 2024 am 08:39 AM
如何使用pandas正确读取txt文件,需要具体代码示例Pandas是一个广泛使用的Python数据分析库,它可以用于处理各种各样的数据类型,包括CSV文件、Excel文件、SQL数据库等。同时,它也可以用于读取文本文件,例如txt文件。但是,在读取txt文件时,我们有时会遇到一些问题,例如编码问题、分隔符问题等。本文将介绍如何使用pandas正确读取txt
 使用pandas读取txt文件的实用技巧
Jan 19, 2024 am 09:49 AM
使用pandas读取txt文件的实用技巧
Jan 19, 2024 am 09:49 AM
使用pandas读取txt文件的实用技巧,需要具体代码示例在数据分析和数据处理中,txt文件是一种常见的数据格式。使用pandas读取txt文件可以快速、方便地进行数据处理。本文将介绍几种实用的技巧,以帮助你更好的使用pandas读取txt文件,并配以具体的代码示例。读取带有分隔符的txt文件使用pandas读取带有分隔符的txt文件时,可以使用read_c
 揭秘Pandas中高效的数据去重方法:快速去除重复数据的技巧
Jan 24, 2024 am 08:12 AM
揭秘Pandas中高效的数据去重方法:快速去除重复数据的技巧
Jan 24, 2024 am 08:12 AM
Pandas去重方法大揭秘:快速、高效的数据去重方式,需要具体代码示例在数据分析和处理过程中,经常会遇到数据中存在重复的情况。重复数据可能会对分析结果产生误导,因此去重是一个非常重要的工作环节。在Pandas这个强大的数据处理库中,提供了多种方法来实现数据去重,本文将介绍一些常用的去重方法,并附上具体的代码示例。基于单列去重最常见的情况是根据某一列的值是否重
 简易pandas安装教程:详细指导如何在不同操作系统上安装pandas
Feb 21, 2024 pm 06:00 PM
简易pandas安装教程:详细指导如何在不同操作系统上安装pandas
Feb 21, 2024 pm 06:00 PM
简易pandas安装教程:详细指导如何在不同操作系统上安装pandas,需要具体代码示例随着数据处理和分析的需求不断增加,pandas成为了许多数据科学家和分析师们的首选工具之一。pandas是一个强大的数据处理和分析库,可以轻松处理和分析大量结构化数据。本文将详细介绍如何在不同操作系统上安装pandas,以及提供具体的代码示例。在Windows操作系统上安
 Golang如何提升数据处理效率?
May 08, 2024 pm 06:03 PM
Golang如何提升数据处理效率?
May 08, 2024 pm 06:03 PM
Golang通过并发性、高效内存管理、原生数据结构和丰富的第三方库,提升数据处理效率。具体优势包括:并行处理:协程支持同时执行多个任务。高效内存管理:垃圾回收机制自动管理内存。高效数据结构:切片、映射和通道等数据结构快速访问和处理数据。第三方库:涵盖fasthttp和x/text等各种数据处理库。
 使用Redis提升Laravel应用的数据处理效率
Mar 06, 2024 pm 03:45 PM
使用Redis提升Laravel应用的数据处理效率
Mar 06, 2024 pm 03:45 PM
使用Redis提升Laravel应用的数据处理效率随着互联网应用的不断发展,数据处理效率成为了开发者们关注的重点之一。在开发基于Laravel框架的应用时,我们可以借助Redis来提升数据处理效率,实现数据的快速访问和缓存。本文将介绍如何使用Redis在Laravel应用中进行数据处理,并提供具体的代码示例。一、Redis简介Redis是一种高性能的内存数据
 pandas读取txt文件的常见问题解答
Jan 19, 2024 am 09:19 AM
pandas读取txt文件的常见问题解答
Jan 19, 2024 am 09:19 AM
Pandas是Python的一种数据分析工具,特别适合对数据进行清洗、处理和分析。在数据分析过程中,我们时常需要读取各种格式的数据文件,比如Txt文件。但在具体操作过程中,会遇到一些问题。本文将介绍pandas读取txt文件常见问题的解答,并提供相应的代码示例。问题1:如何读取txt文件?使用pandas的read_csv()函数可以读取txt文件。这是因为
