

对Beautifulsoup和selenium用法的简单介绍
Beautifulsoup和selenium的简单使用
requests库的复习
好久没用requests了,因为一会儿要写个简单的爬虫,所以还是随便写一点复习下。
import requests r = requests.get('https://api.github.com/user', auth=('haiyu19931121@163.com', 'Shy18137803170'))print(r.status_code) # 状态码200print(r.json()) # 返回json格式print(r.text) # 返回文本print(r.headers) # 头信息print(r.encoding) # 编码方式,一般utf-8# 当写入文件比较大时,避免内存耗尽,可以一次写指定的字节数或者一行。# 一次读一行,chunk_size=512为默认值for chunk in r.iter_lines():print(chunk)# 一次读取一块,大小为512for chunk in r.iter_content(chunk_size=512):print(chunk)
注意iter_lines和iter_content返回的都是字节数据,若要写入文件,不管是文本还是图片,都需要以wb的方式打开。
Beautifulsoup的使用
进入正题,早就听说这个著名的库,以前写爬虫用正则表达式虽然不麻烦,但有时候会匹配不准确。使用Beautifulsoup可以准确从HTML标签中提取数据。虽然是慢了点,但是简单好使呀。
from bs4 import BeautifulSoup html_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""# 就注意一点,第二个参数指定解析器,必须填上,不然会有警告。推荐使用lxmlsoup = BeautifulSoup(html_doc, 'lxml')
紧接着上面的代码,看下面一些简单的操作。使用点属性的行为,会得到第一个查找到的符合条件的数据。是find方法的简写。
soup.a soup.find('p')
上面的两句是等价的。
# soup.body是一个Tag对象。是body标签中所有html代码print(soup.body)
<body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body>
# 获取body里所有文本,不含标签print(soup.body.text)# 等同于下面的写法soup.body.get_text()# 还可以这样写,strings是所有文本的生成器for string in soup.body.strings:print(string, end='')
The Dormouse's story Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well. ...
# 获得该标签里的文本。print(soup.title.string)
The Dormouse's story
# Tag对象的get方法可以根据属性的名称获得属性的值,此句表示得到第一个p标签里class属性的值print(soup.p.get('class'))# 和下面的写法等同print(soup.p['class'])
['title']
# 查看a标签的所有属性,以字典形式给出print(soup.a.attrs)
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}# 标签的名称soup.title.name
title
find_all
使用最多的当属find_all / find方法了吧,前者查找所有符合条件的数据,返回一个列表。后者则是这个列表中的第一个数据。find_all有一个limit参数,限制列表的长度(即查找符合条件的数据的个数)。当limit=1其实就成了find方法 。
find_all同样有简写方法。
soup.find_all('a', id='link1') soup('a', id='link1')
上面两种写法是等价的,第二种写法便是简写。
find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs)name
name就是想要搜索的标签,比如下面就是找到所有的p标签。不仅能填入字符串,还能传入正则表达式、列表、函数、True。
传入True的话,就没有限制,什么都查找了。
recursive
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
# title不是html的直接子节点,但是会检索其下所有子孙节点soup.html.find_all("title")# [The Dormouse's story ]# 参数设置为False,只会找直接子节点soup.html.find_all("title", recursive=False)# []# title就是head的直接子节点,所以这个参数此时无影响a = soup.head.find_all("title", recursive=False)# [The Dormouse's story ]keyword和attrs
使用keyword,加上一个或者多个限定条件,缩小查找范围。
# 查看所有id为link1的p标签soup.find_all('a', id='link1')
如果按类查找,由于class关键字Python已经使用。可以用class_,或者不指定关键字,又或者使用attrs填入字典。
soup.find_all('p', class_='story')
soup.find_all('p', 'story')
soup.find_all('p', attrs={"class": "story"})上面三种方法等价。class_可以接受字符串、正则表达式、函数、True。
text
搜索文本值,好像使用string参数也是一样的结果。
a = soup.find_all(text='Elsie')# 或者,4.4以上版本请使用texta = soup.find_all(string='Elsie')
text参数也可以接受字符串、正则表达式、True、列表。
CSS选择器
还能使用CSS选择器呢。使用select方法就好了,select始终返回一个列表。
列举几个常用的操作。
# 所有div标签soup.select('div')# 所有id为username的元素soup.select('.username')# 所有class为story的元素soup.select('#story')# 所有div元素之内的span元素,中间可以有其他元素soup.select('div span')# 所有div元素之内的span元素,中间没有其他元素soup.select('div > span')# 所有具有一个id属性的input标签,id的值无所谓soup.select('input[id]')# 所有具有一个id属性且值为user的input标签soup.select('input[id="user"]')# 搜索多个,class为link1或者link2的元素都符合soup.select("#link1, #link2")一个爬虫小例子
上面介绍了requests和beautifulsoup4的基本用法,使用这些已经可以写一些简单的爬虫了。来试试吧。
此例子来自《Python编程快速上手——让繁琐的工作自动化》[美] AI Sweigart
这个爬虫会批量下载XKCD漫画网的图片,可以指定下载的页面数。
import osimport requestsfrom bs4 import BeautifulSoup# exist_ok=True,若文件夹已经存在也不会报错os.makedirs('xkcd')
url = 'https://xkcd.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def save_img(img_url, limit=1):
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024*1024):
f.write(chunk)# 每次下载一张图片,就减1limit -= 1# 找到上一张图片的网址if limit > 0:try:
prev = 'https://xkcd.com' + soup.find('a', rel='prev').get('href')except AttributeError:print('Link Not Exist')else:
save_img(prev, limit)if __name__ == '__main__':
save_img(url, limit=20)print('Done!')Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading ... Done!
多线程下载
单线程的速度有点慢,比如可以使用多线程,由于我们在获取prev的时候,知道了每个网页的网址是很有规律的。它像这样。只是最后的数字不一样,所以我们可以很方便地使用range来遍历。
import osimport threadingimport requestsfrom bs4 import BeautifulSoup
os.makedirs('xkcd')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def download_imgs(start, end):for url_num in range(start, end):
img_url = 'https://xkcd.com/' + str(url_num)
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024 * 1024):
f.write(chunk)if __name__ == '__main__':# 下载从1到30,每个线程下载10个threads = []for i in range(1, 30, 10):
thread_obj = threading.Thread(target=download_imgs, args=(i, i + 10))
threads.append(thread_obj)
thread_obj.start()# 阻塞,等待线程执行结束都会等待for thread in threads:
thread.join()# 所有线程下载完毕,才打印print('Done!')来看下结果吧。
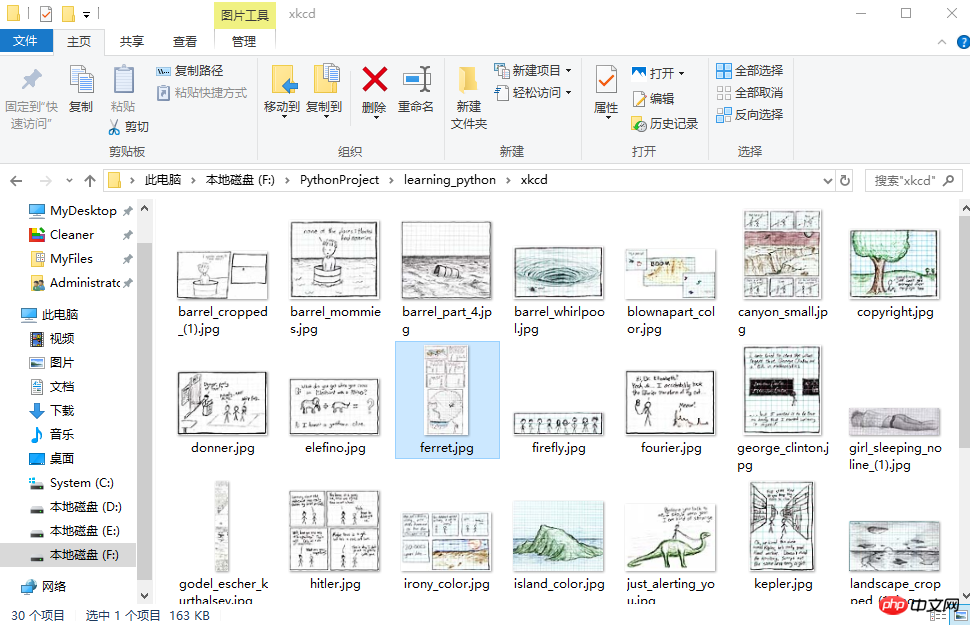
初步了解selenium
selenium用来作自动化测试。使用前需要下载驱动,我只下载了Firefox和Chrome的。网上随便一搜就能下载到了。接下来将下载下来的文件其复制到将安装目录下,比如Firefox,将对应的驱动程序放到C:\Program Files (x86)\Mozilla Firefox,并将这个路径添加到环境变量中,同理Chrome的驱动程序放到C:\Program Files (x86)\Google\Chrome\Application并将该路径添加到环境变量。最后重启IDE开始使用吧。
模拟百度搜索
下面这个例子会打开Chrome浏览器,访问百度首页,模拟输入The Zen of Python,随后点击百度一下,当然也可以用回车代替。Keys下是一些不能用字符串表示的键,比如方向键、Tab、Enter、Esc、F1~F12、Backspace等。然后等待3秒,页面跳转到知乎首页,接着返回到百度,最后退出(关闭)浏览器。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time browser = webdriver.Chrome()# Chrome打开百度首页browser.get('https://www.baidu.com/')# 找到输入区域input_area = browser.find_element_by_id('kw')# 区域内填写内容input_area.send_keys('The Zen of Python')# 找到"百度一下"search = browser.find_element_by_id('su')# 点击search.click()# 或者按下回车# input_area.send_keys('The Zen of Python', Keys.ENTER)time.sleep(3) browser.get('https://www.zhihu.com/') time.sleep(2)# 返回到百度搜索browser.back() time.sleep(2)# 退出浏览器browser.quit()
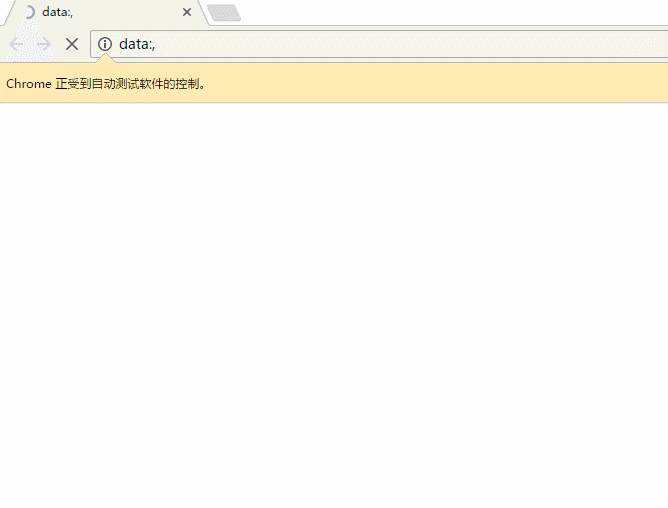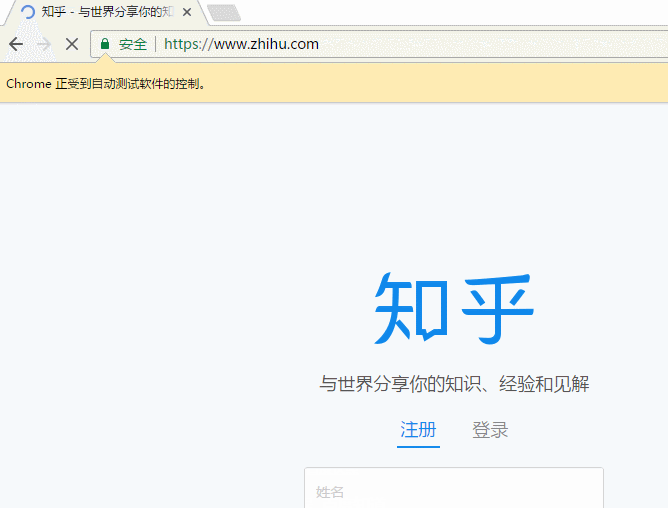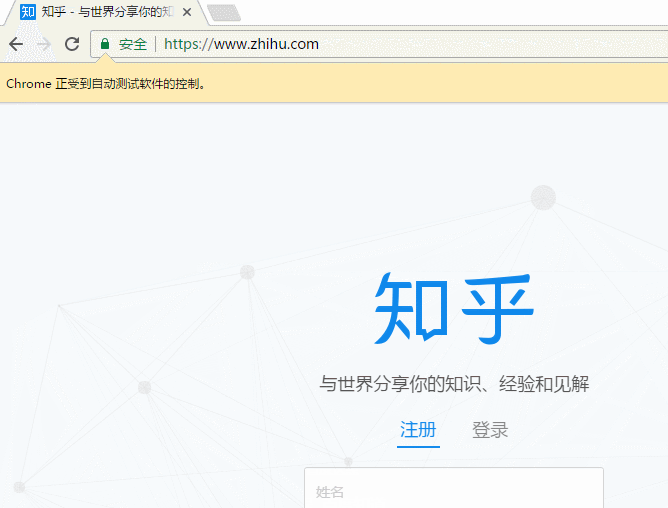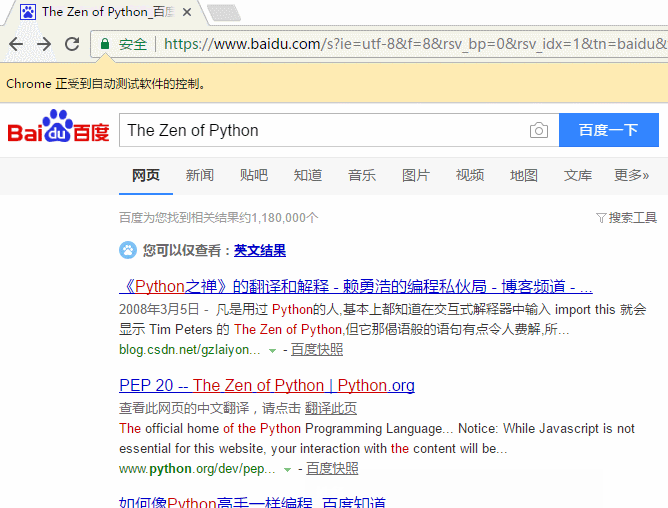
send_keys模拟输入内容。可以使用element的clear()方法清空输入。一些其他模拟点击浏览器按钮的方法如下
browser.back() # 返回按钮browser.forward() # 前进按钮browser.refresh() # 刷新按钮browser.close() # 关闭当前窗口browser.quit() # 退出浏览器
查找方法
以下列举常用的查找Element的方法。
| 方法名 | 返回的WebElement |
|---|---|
| find_element_by_id(id) | 匹配id属性值的元素 |
| find_element_by_name(name) | 匹配name属性值的元素 |
| find_element_by_class_name(name) | 匹配CSS的class值的元素 |
| find_element_by_tag_name(tag) | 匹配标签名的元素,如div |
| find_element_by_css_selector(selector) | 匹配CSS选择器 |
| find_element_by_xpath(xpath) | 匹配xpath |
| find_element_by_link_text(text) | 完全匹配提供的text的a标签 |
| find_element_by_partial_link_text(text) | 提供的text可以是a标签中文本中的一部分 |
登录CSDN
以下代码可以模拟输入账号密码,点击登录。整个过程还是很快的。
browser = webdriver.Chrome() browser.get('https://passport.csdn.net/account/login') browser.find_element_by_id('username').send_keys('haiyu19931121@163.com') browser.find_element_by_id('password').send_keys('**********') browser.find_element_by_class_name('logging').click()
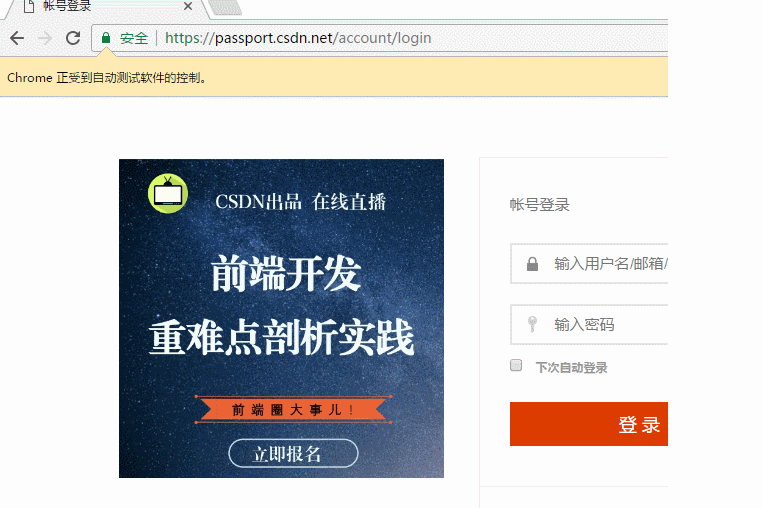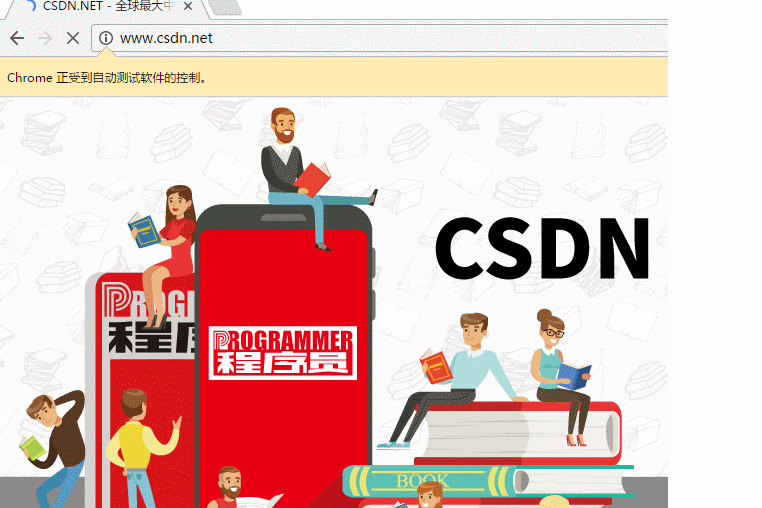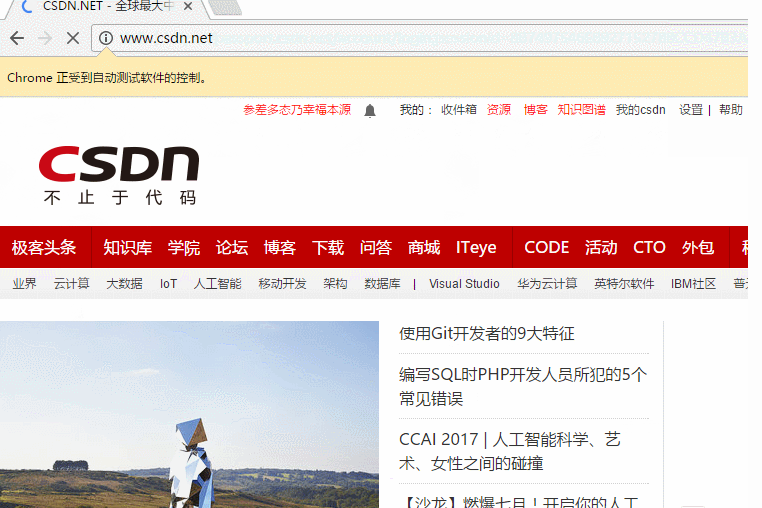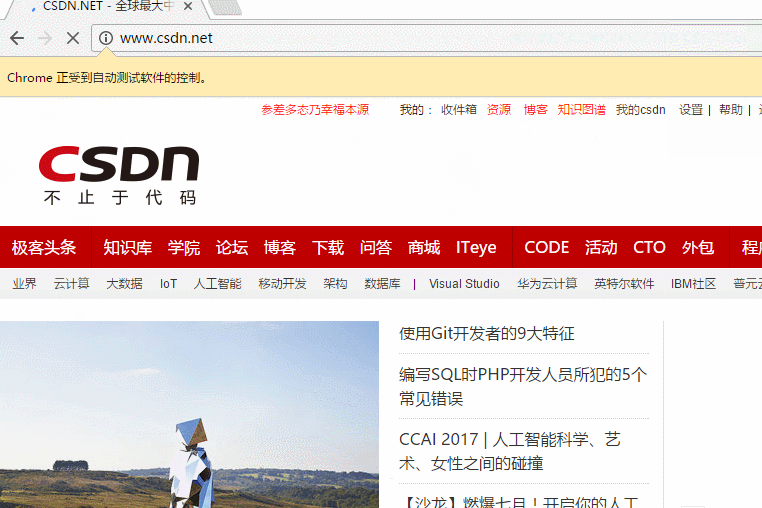
以上差不多都是API的罗列,其中有自己的理解,也有照搬官方文档的。
by @sunhaiyu
2017.7.13
以上是对Beautifulsoup和selenium用法的简单介绍的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何使用磁力链接
Feb 18, 2024 am 10:02 AM
如何使用磁力链接
Feb 18, 2024 am 10:02 AM
磁力链接是一种用于下载资源的链接方式,相比传统的下载方式更为便捷和高效。使用磁力链接可以通过点对点的方式下载资源,而不需要依赖中介服务器。本文将介绍磁力链接的使用方法及注意事项。一、什么是磁力链接磁力链接是一种基于P2P(Peer-to-Peer)协议的下载方式。通过磁力链接,用户可以直接连接到资源的发布者,从而完成资源的共享和下载。与传统的下载方式相比,磁
 如何使用mdf和mds文件
Feb 19, 2024 pm 05:36 PM
如何使用mdf和mds文件
Feb 19, 2024 pm 05:36 PM
mdf文件和mds文件怎么用随着计算机技术的不断进步,我们可以通过多种方式来存储和共享数据。在数字媒体领域,我们经常会遇到一些特殊的文件格式。在这篇文章中,我们将讨论一种常见的文件格式——mdf和mds文件,并介绍它们的使用方法。首先,我们需要了解mdf文件和mds文件的含义。mdf是CD/DVD镜像文件的扩展名,而mds文件则是mdf文件的元数据文件。
 crystaldiskmark是什么软件?-crystaldiskmark如何使用?
Mar 18, 2024 pm 02:58 PM
crystaldiskmark是什么软件?-crystaldiskmark如何使用?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark是一款适用于硬盘的小型HDD基准测试工具,可以快速测量顺序和随机读/写速度。接下来就让小编为大家介绍一下CrystalDiskMark,以及crystaldiskmark如何使用吧~一、CrystalDiskMark介绍CrystalDiskMark是一款广泛使用的磁盘性能测试工具,用于评估机械硬盘和固态硬盘(SSD)的读写速度和随机I/O性能。它是一款免费的Windows应用程序,并提供用户友好的界面和各种测试模式来评估硬盘驱动器性能的不同方面,并被广泛用于硬件评
 foobar2000怎么下载?-foobar2000怎么使用
Mar 18, 2024 am 10:58 AM
foobar2000怎么下载?-foobar2000怎么使用
Mar 18, 2024 am 10:58 AM
foobar2000是一款能随时收听音乐资源的软件,各种音乐无损音质带给你,增强版本的音乐播放器,让你得到更全更舒适的音乐体验,它的设计理念是将电脑端的高级音频播放器移植到手机上,提供更加便捷高效的音乐播放体验,界面设计简洁明了易于使用它采用了极简的设计风格,没有过多的装饰和繁琐的操作能够快速上手,同时还支持多种皮肤和主题,根据自己的喜好进行个性化设置,打造专属的音乐播放器支持多种音频格式的播放,它还支持音频增益功能根据自己的听力情况调整音量大小,避免过大的音量对听力造成损害。接下来就让小编为大
 网易邮箱大师怎么用
Mar 27, 2024 pm 05:32 PM
网易邮箱大师怎么用
Mar 27, 2024 pm 05:32 PM
网易邮箱,作为中国网民广泛使用的一种电子邮箱,一直以来以其稳定、高效的服务赢得了用户的信赖。而网易邮箱大师,则是专为手机用户打造的邮箱软件,它极大地简化了邮件的收发流程,让我们的邮件处理变得更加便捷。那么网易邮箱大师该如何使用,具体又有哪些功能呢,下文中本站小编将为大家带来详细的内容介绍,希望能帮助到大家!首先,您可以在手机应用商店搜索并下载网易邮箱大师应用。在应用宝或百度手机助手中搜索“网易邮箱大师”,然后按照提示进行安装即可。下载安装完成后,我们打开网易邮箱账号并进行登录,登录界面如下图所示
 百度网盘app怎么用
Mar 27, 2024 pm 06:46 PM
百度网盘app怎么用
Mar 27, 2024 pm 06:46 PM
在如今云存储已经成为我们日常生活和工作中不可或缺的一部分。百度网盘作为国内领先的云存储服务之一,凭借其强大的存储功能、高效的传输速度以及便捷的操作体验,赢得了广大用户的青睐。而且无论你是想要备份重要文件、分享资料,还是在线观看视频、听取音乐,百度网盘都能满足你的需求。但是很多用户们可能对百度网盘app的具体使用方法还不了解,那么这篇教程就将为大家详细介绍百度网盘app如何使用,还有疑惑的用户们就快来跟着本文详细了解一下吧!百度云网盘怎么用:一、安装首先,下载并安装百度云软件时,请选择自定义安装选
 BTCC教学:如何在BTCC交易所绑定使用MetaMask钱包?
Apr 26, 2024 am 09:40 AM
BTCC教学:如何在BTCC交易所绑定使用MetaMask钱包?
Apr 26, 2024 am 09:40 AM
MetaMask(中文也叫小狐狸钱包)是一款免费的、广受好评的加密钱包软件。目前,BTCC已支持绑定MetaMask钱包,绑定后可使用MetaMask钱包进行快速登入,储值、买币等,且首次绑定还可获得20USDT体验金。在BTCCMetaMask钱包教学中,我们将详细介绍如何注册和使用MetaMask,以及如何在BTCC绑定并使用小狐狸钱包。MetaMask钱包是什么?MetaMask小狐狸钱包拥有超过3,000万用户,是当今最受欢迎的加密货币钱包之一。它可免费使用,可作为扩充功能安装在网络
 pip镜像源简易指南:轻松掌握使用方法
Jan 16, 2024 am 10:18 AM
pip镜像源简易指南:轻松掌握使用方法
Jan 16, 2024 am 10:18 AM
轻松上手:如何使用pip镜像源随着Python在全球范围内的普及,pip成为了Python包管理的标准工具。然而,许多开发者在使用pip安装包时面临的一个常见问题是速度慢。这是因为默认情况下,pip从Python官方源或其他外部源下载包,而这些源可能位于海外服务器,导致下载速度缓慢。为了提高下载速度,我们可以使用pip镜像源。什么是pip镜像源?简单来说,就
