

Python采集--数据的储存
Python网络数据采集3-数据存到CSV以及MySql
先热热身,下载某个页面的所有图片。
import requestsfrom bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
start_url = 'https://www.pythonscraping.com'r = requests.get(start_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')# 获取所有img标签img_tags = soup.find_all('img')for tag in img_tags:print(tag['src'])http://pythonscraping.com/img/lrg%20(1).jpg
将网页表格存储到CSV文件中
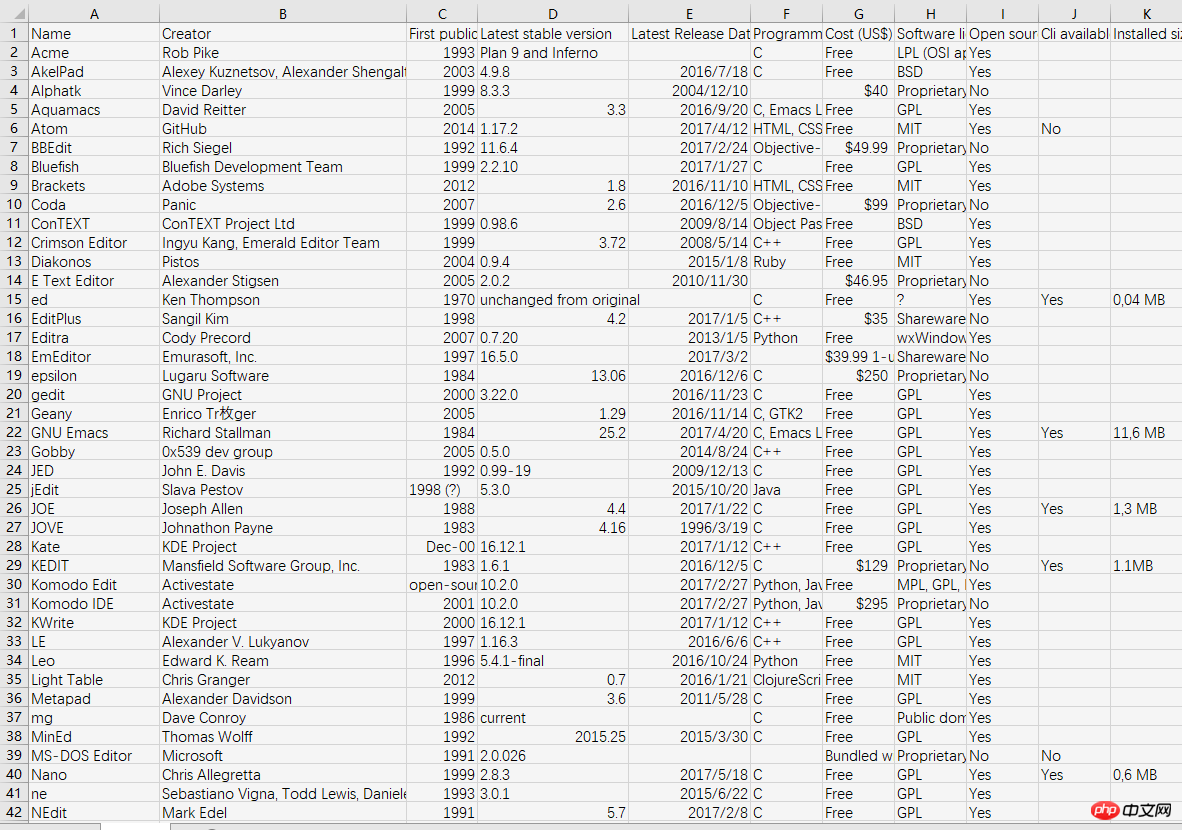
以这个网址为例,有好几个表格,我们对第一个表格进行爬取。Wiki-各种编辑器的比较
import csvimport requestsfrom bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
url = 'https://en.wikipedia.org/wiki/Comparison_of_text_editors'r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')# 只要第一个表格rows = soup.find('table', class_='wikitable').find_all('tr')# csv写入时候每写一行会有一空行被写入,所以设置newline为空with open('editors.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)for row in rows:
csv_row = []for cell in row.find_all(['th', 'td']):
csv_row.append(cell.text)
writer.writerow(csv_row)需要注意的有一点,打开文件的时候需要指定newline='',因为写入csv文件时,每写入一行就会有一空行被写入。
从网络读取CSV文件
上面介绍了将网页内容存到CSV文件中。如果是从网上获取到了CSV文件呢?我们不希望下载后再从本地读取。但是网络请求的话,返回的是字符串而非文件对象。csv.reader()需要传入一个文件对象。故需要将获取到的字符串转换成文件对象。Python的内置库,StringIO和BytesIO可以将字符串/字节当作文件一样来处理。对于csv模块,要求reader迭代器返回字符串类型,所以使用StringIO,如果处理二进制数据,则用BytesIO。转换为文件对象,就能用CSV模块处理了。
下面的代码最为关键的就是data_file = StringIO(csv_data.text)将字符串转换为类似文件的对象。
from io import StringIOimport csvimport requests csv_data = requests.get('http://pythonscraping.com/files/MontyPythonAlbums.csv') data_file = StringIO(csv_data.text) reader = csv.reader(data_file)for row in reader:print(row)
['Name', 'Year'] ["Monty Python's Flying Circus", '1970'] ['Another Monty Python Record', '1971'] ["Monty Python's Previous Record", '1972'] ['The Monty Python Matching Tie and Handkerchief', '1973'] ['Monty Python Live at Drury Lane', '1974'] ['An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail', '1975'] ['Monty Python Live at City Center', '1977'] ['The Monty Python Instant Record Collection', '1977'] ["Monty Python's Life of Brian", '1979'] ["Monty Python's Cotractual Obligation Album", '1980'] ["Monty Python's The Meaning of Life", '1983'] ['The Final Rip Off', '1987'] ['Monty Python Sings', '1989'] ['The Ultimate Monty Python Rip Off', '1994'] ['Monty Python Sings Again', '2014']
DictReader可以像操作字典那样获取数据,把表的第一行(一般是标头)作为key。可访问每一行中那个某个key对应的数据。
每一行数据都是OrderDict,使用Key可访问。看上面打印信息的第一行,说明由Name和Year两个Key。也可以使用reader.fieldnames查看。
from io import StringIOimport csvimport requests csv_data = requests.get('http://pythonscraping.com/files/MontyPythonAlbums.csv') data_file = StringIO(csv_data.text) reader = csv.DictReader(data_file)# 查看Keyprint(reader.fieldnames)for row in reader:print(row['Year'], row['Name'], sep=': ')
['Name', 'Year'] 1970: Monty Python's Flying Circus 1971: Another Monty Python Record 1972: Monty Python's Previous Record 1973: The Monty Python Matching Tie and Handkerchief 1974: Monty Python Live at Drury Lane 1975: An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail 1977: Monty Python Live at City Center 1977: The Monty Python Instant Record Collection 1979: Monty Python's Life of Brian 1980: Monty Python's Cotractual Obligation Album 1983: Monty Python's The Meaning of Life 1987: The Final Rip Off 1989: Monty Python Sings 1994: The Ultimate Monty Python Rip Off 2014: Monty Python Sings Again
存储数据
大数据存储与数据交互能力, 在新式的程序开发中已经是重中之重了.
存储媒体文件的2种主要方式: 只获取url链接, 或直接将源文件下载下来
直接引用url链接的优点:
爬虫运行得更快,耗费的流量更少,因为只要链接,不需要下载文件。
可以节省很多存储空间,因为只需要存储 URL 链接就可以。
存储 URL 的代码更容易写,也不需要实现文件下载代码。
不下载文件能够降低目标主机服务器的负载。
直接引用url链接的缺点:
这些内嵌在网站或应用中的外站 URL 链接被称为盗链(hotlinking), 每个网站都会实施防盗链措施。
因为链接文件在别人的服务器上,所以应用就要跟着别人的节奏运行了。
盗链是很容易改变的。如果盗链图片放在博客上,要是被对方服务器发现,很可能被恶搞。如果 URL 链接存起来准备以后再用,可能用的时候链接已经失效了,或者是变成了完全无关的内容。
python3的urllib.request.urlretrieve可以根据文件的url下载文件:
from urllib.request import urlretrievefrom urllib.request import urlopenfrom bs4 import BeautifulSouphtml = urlopen("http://www.pythonscraping.com")bsObj = BeautifulSoup(html)imageLocation = bsObj.find("a", {"id": "logo"}).find("img")["src"]urlretrieve (imageLocation, "logo.jpg")
csv(comma-separated values, 逗号分隔值)是存储表格数据的常用文件格式
网络数据采集的一个常用功能就是获取html表格并写入csv
除了用户定义的变量名,mysql是不区分大小写的, 习惯上mysql关键字用大写表示
连接与游标(connection/cursor)是数据库编程的2种模式:
连接模式除了要连接数据库之外, 还要发送数据库信息, 处理回滚操作, 创建游标对象等
一个连接可以创建多个游标, 一个游标跟踪一种状态信息, 比如数据库的使用状态. 游标还会包含最后一次查询执行的结果. 通过调用游标函数, 如fetchall获取查询结果
游标与连接使用完毕之后,务必要关闭, 否则会导致连接泄漏, 会一直消耗数据库资源
使用try ... finally语句保证数据库连接与游标的关闭
让数据库更高效的几种方法:
给每张表都增加id字段. 通常数据库很难智能地选择主键
用智能索引, CREATE INDEX definition ON dictionary (id, definition(16));
选择合适的范式
发送Email, 通过爬虫或api获取信息, 设置条件自动发送Email! 那些订阅邮件, 肯定就是这么来的!
保存链接之间的联系
比如链接A,能够在这个页面里找到链接B。则可以表示为A -> B。我们就是要保存这种联系到数据库。先建表:
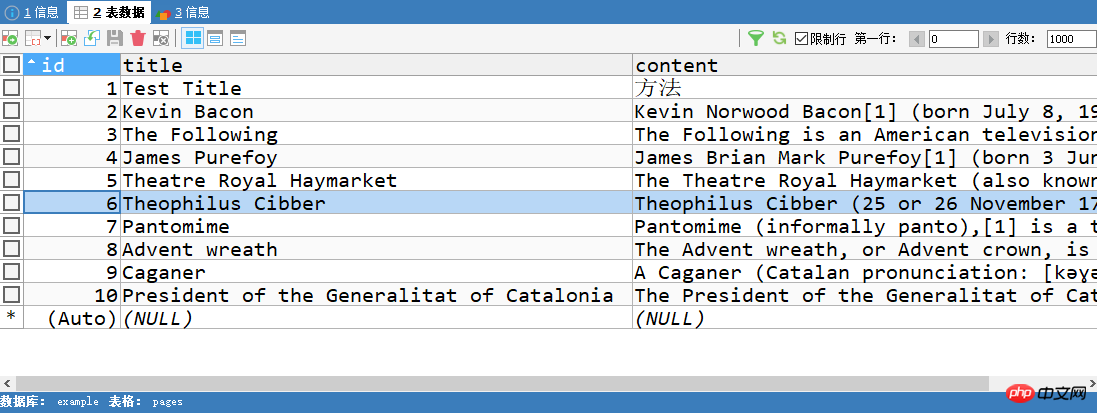
pages表只保存链接url。
CREATE TABLE `pages` ( `id` int(11) NOT NULL AUTO_INCREMENT, `url` varchar(255) DEFAULT NULL, `created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) )
links表保存链接的fromId和toId,这两个id和pages里面的id是一致的。如1 -> 2就是pages里id为1的url页面里可以访问到id为2的url的意思。
CREATE TABLE `links` ( `id` int(11) NOT NULL AUTO_INCREMENT, `fromId` int(11) DEFAULT NULL, `toId` int(11) DEFAULT NULL, `created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`)
上面的建表语句看起来有点臃肿,我是先用可视化工具建表后,再用show create table pages这样的语句查看的。
import reimport pymysqlimport requestsfrom bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
conn = pymysql.connect(host='localhost', user='root', password='admin', db='wiki', charset='utf8')
cur = conn.cursor()def insert_page_if_not_exists(url):
cur.execute(f"SELECT * FROM pages WHERE url='{url}';")# 这条url没有插入的话if cur.rowcount == 0:# 那就插入cur.execute(f"INSERT INTO pages(url) VALUES('{url}');")
conn.commit()# 刚插入数据的idreturn cur.lastrowid# 否则已经存在这条数据,因为url一般是唯一的,所以获取一个就行,取脚标0是获得idelse:return cur.fetchone()[0]def insert_link(from_page, to_page):print(from_page, ' -> ', to_page)
cur.execute(f"SELECT * FROM links WHERE fromId={from_page} AND toId={to_page};")# 如果查询不到数据,则插入,插入需要两个pages的id,即两个urlif cur.rowcount == 0:
cur.execute(f"INSERT INTO links(fromId, toId) VALUES({from_page}, {to_page});")
conn.commit()# 链接去重pages = set()# 得到所有链接def get_links(page_url, recursion_level):global pagesif recursion_level == 0:return# 这是刚插入的链接page_id = insert_page_if_not_exists(page_url)
r = requests.get('https://en.wikipedia.org' + page_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
link_tags = soup.find_all('a', href=re.compile('^/wiki/[^:/]*$'))for link_tag in link_tags:# page_id是刚插入的url,参数里再次调用了insert_page...方法,获得了刚插入的url里能去往的url列表# 由此形成联系,比如刚插入的id为1,id为1的url里能去往的id有2、3、4...,则形成1 -> 2, 1 -> 3这样的联系insert_link(page_id, insert_page_if_not_exists(link_tag['href']))if link_tag['href'] not in pages:
new_page = link_tag['href']
pages.add(new_page)# 递归查找, 只能递归recursion_level次get_links(new_page, recursion_level - 1)if __name__ == '__main__':try:
get_links('/wiki/Kevin_Bacon', 5)except Exception as e:print(e)finally:
cur.close()
conn.close()1 -> 2 2 -> 1 1 -> 2 1 -> 3 3 -> 4 4 -> 5 4 -> 6 4 -> 7 4 -> 8 4 -> 4 4 -> 4 4 -> 9 4 -> 9 3 -> 10 10 -> 11 10 -> 12 10 -> 13 10 -> 14 10 -> 15 10 -> 16 10 -> 17 10 -> 18 10 -> 19 10 -> 20 10 -> 21 ...
看打印的信息,一目了然。看前两行打印,pages表里id为1的url可以访问id为2的url,同时pages表里id为2的url可以访问id为1的url...依次类推。
首先需要使用insert_page_if_not_exists(page_url)获得链接的id,然后使用insert_link(fromId, toId)形成联系。fromId是当前页面的url,toId则是从当前页面能够去往的url的id,这些能去往的url用bs4找到以列表形式返回。当前所处的url即page_id,所以需要在insert_link的第二个参数中,再次调用insert_page_if_not_exists(link)以获得列表中每个url的id。由此形成了联系。比如刚插入的id为1,id为1的url里能去往的id有2、3、4...,则形成1 -> 2, 1 -> 3这样的联系。
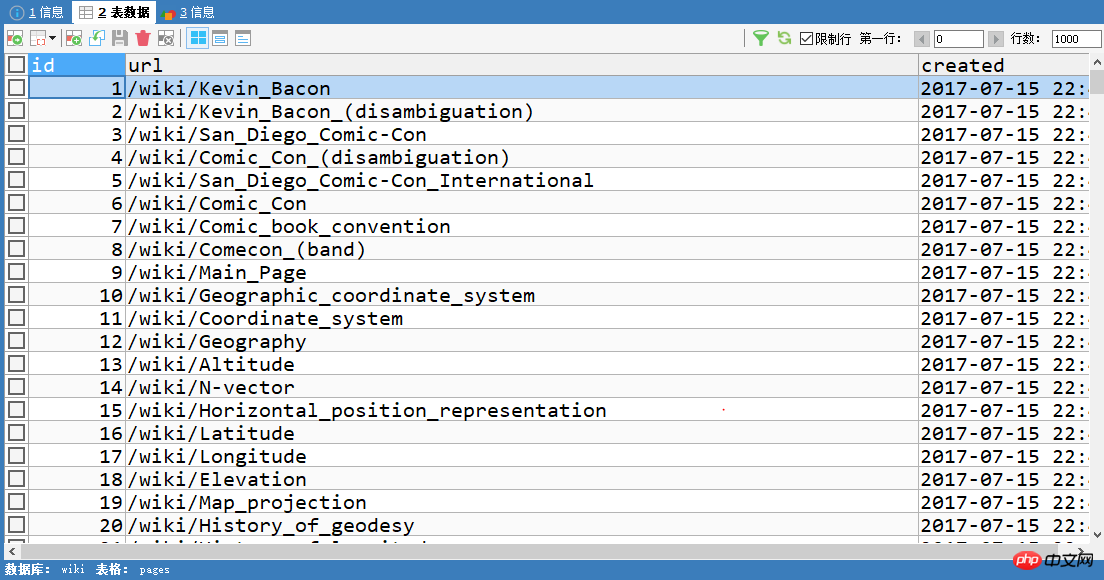
看下数据库。下面是pages表,每一个id都对应一个url。
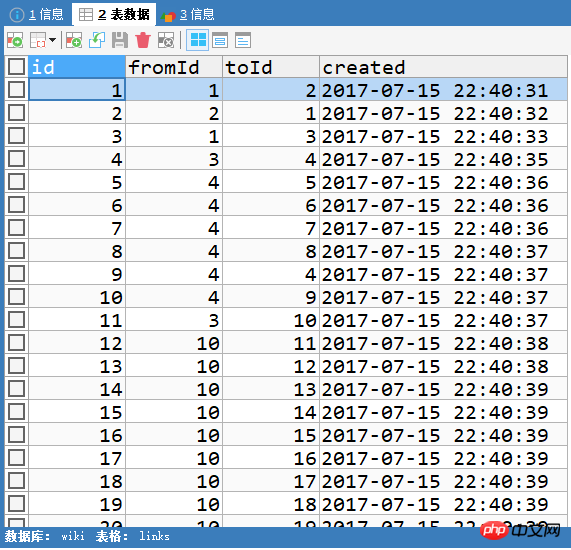
然后下面是links表,fromId和toId就是pages中的id。当然和打印的数据是一样的咯,不过打印了看看就过去了,存下来的话哪天需要分析这些数据就大有用处了。
以上是Python采集--数据的储存的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上运行,但体验可能不佳。首先确保系统已更新到最新补丁,然后下载与系统架构匹配的VS Code安装包,按照提示安装。安装后,注意某些扩展程序可能与Windows 8不兼容,需要寻找替代扩展或在虚拟机中使用更新的Windows系统。安装必要的扩展,检查是否正常工作。尽管VS Code在Windows 8上可行,但建议升级到更新的Windows系统以获得更好的开发体验和安全保障。
 PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
 vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
在 VS Code 中,可以通过以下步骤在终端运行程序:准备代码和打开集成终端确保代码目录与终端工作目录一致根据编程语言选择运行命令(如 Python 的 python your_file_name.py)检查是否成功运行并解决错误利用调试器提升调试效率
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
 visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
VS Code 可用于编写 Python,并提供许多功能,使其成为开发 Python 应用程序的理想工具。它允许用户:安装 Python 扩展,以获得代码补全、语法高亮和调试等功能。使用调试器逐步跟踪代码,查找和修复错误。集成 Git,进行版本控制。使用代码格式化工具,保持代码一致性。使用 Linting 工具,提前发现潜在问题。
