

Java中HashMap遍历与使用的示例详解

map的几种遍历方式:
Map< String, String> map = new HashMap<>();
map.put("aa", "@sohu.com");
map.put("bb","@163.com");
map.put("cc", "@sina.com");
System.out.println("普通的遍历方法,通过Map.keySet遍历key和value");//普通使用,二次取值
for (String key : map.keySet()) {
System.out.println("key= "+key+" and value= "+map.get(key));
}
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String, String> entry = it.next();
System.out.println("key= "+entry.getKey()+" and value= "+entry.getValue());
}
System.out.println("通过Map.entrySet遍历key和value"); //推荐这种,特别是容量大的时候
for(Map.Entry<String, String> entry : map.entrySet()){
System.out.println("key= "+entry.getKey()+" and value= "+entry.getValue());
}
System.out.println(“通过Map.values()遍历所有的value,但不能遍历key”);
for(String v : map.values()){
System.out.println("value = "+v);
}HashMap和Hashtable的联系和区别
实现原理相同,功能相同,底层都是哈希表结构,查询速度快,在很多情况下可以互用,早期的版本一般都是安全的。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
hashmap的特点
HashMap是map接口的子类,是将键映射到值的对象,其中键和值都是对象,不是线程安全的
hashMap用hash表来存储map的键
key是无序唯一,可以有一个为null
value无序不唯一,可以有对个null
linkedHashMap使用hash表存储map中的键,并且使用linked双向链表管理顺序
我们用的最多的是HashMap,在Map 中插入、删除和定位元素,HashMap 是最好的选择。如果需要输出的顺序和输入的相同,那么用LinkedHashMap 可以实现,它还可以按读取顺序来排列.
HashMap是一个最常用的Map,它根据键的hashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为NULL,允许多条记录的值为NULL。HashMap不支持线程同步,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致性。
如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
几大常用集合的效率对比 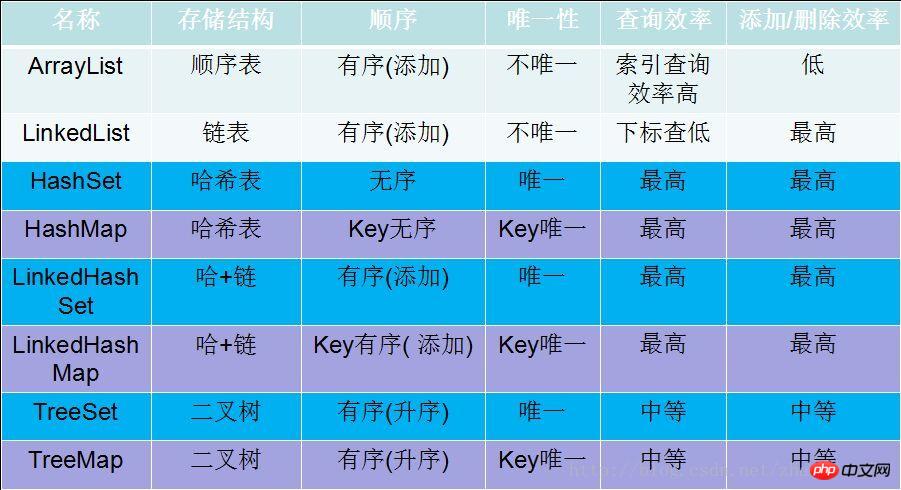
以上是Java中HashMap遍历与使用的示例详解的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题








 突破或从Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或从Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一种强大且表达力丰富的处理数据集合的方式。然而,使用Stream时,一个常见问题是:如何从forEach操作中中断或返回? 传统循环允许提前中断或返回,但Stream的forEach方法并不直接支持这种方式。本文将解释原因,并探讨在Stream处理系统中实现提前终止的替代方法。 延伸阅读: Java Stream API改进 理解Stream forEach forEach方法是一个终端操作,它对Stream中的每个元素执行一个操作。它的设计意图是处

 Java程序查找胶囊的体积
Feb 07, 2025 am 11:37 AM
Java程序查找胶囊的体积
Feb 07, 2025 am 11:37 AM
胶囊是一种三维几何图形,由一个圆柱体和两端各一个半球体组成。胶囊的体积可以通过将圆柱体的体积和两端半球体的体积相加来计算。本教程将讨论如何使用不同的方法在Java中计算给定胶囊的体积。 胶囊体积公式 胶囊体积的公式如下: 胶囊体积 = 圆柱体体积 两个半球体体积 其中, r: 半球体的半径。 h: 圆柱体的高度(不包括半球体)。 例子 1 输入 半径 = 5 单位 高度 = 10 单位 输出 体积 = 1570.8 立方单位 解释 使用公式计算体积: 体积 = π × r2 × h (4
