

python3如何利用requests模块实现爬取页面内容的实例详解

本篇文章主要介绍了python3使用requests模块爬取页面内容的实战演练,具有一定的参考价值,有兴趣的可以了解一下
1.安装pip
我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip。
$ sudo apt install python-pip
安装成功,查看PIP版本:
$ pip -V
2.安装requests模块
这里我是通过pip方式进行安装:
$ pip install requests
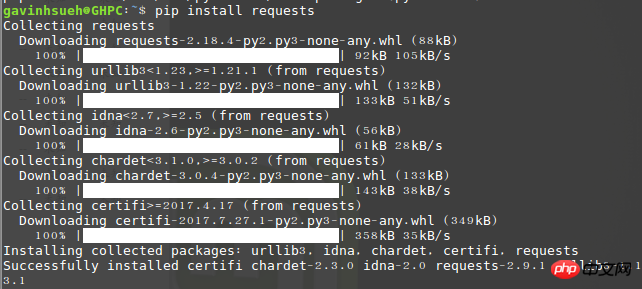
运行import requests,如果没提示错误,那说明已经安装成功了!

检验是否安装成功
3.安装beautifulsoup4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找、修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。
$ sudo apt-get install python3-bs4
注:这里我使用的是python3的安装方式,如果你用的是python2,可以使用下面命令安装。
$ sudo pip install beautifulsoup4
4.requests模块浅析
1)发送请求
首先当然是要导入 Requests 模块:
>>> import requests
然后,获取目标抓取网页。这里我以下为例:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
这里返回一个名为 r 的响应对象。我们可以从这个对象中获取所有我们想要的信息。这里的get是http的响应方法,所以举一反三你也可以将其替换为put、delete、post、head。
2)传递URL参数
有时我们想为 URL 的查询字符串传递某种数据。如果你是手工构建 URL,那么数据会以键/值对的形式置于 URL 中,跟在一个问号的后面。例如, cnblogs.com/get?key=val。 Requests 允许你使用 params 关键字参数,以一个字符串字典来提供这些参数。
举例来说,当我们google搜索“python爬虫”关键词时,newwindow(新窗口打开)、q及oq(搜索关键词)等参数可以手工组成URL ,那么你可以使用如下代码:
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)3)响应内容
通过r.text或r.content来获取页面响应内容。
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.textRequests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。这里补充一点r.text和r.content二者的区别,简单说:
resp.text返回的是Unicode型的数据;
resp.content返回的是bytes型也就是二进制的数据;
所以如果你想取文本,可以通过r.text,如果想取图片,文件,则可以通过r.content。
4)获取网页编码
>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
5)获取响应状态码
我们可以检测响应状态码:
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 200
5.案例演示
最近公司刚引入了一款OA系统,这里我以其官方说明文档页面为例,并且只抓取页面中文章标题和内容等有用信息。
演示环境
操作系统:linuxmint
python版本:python 3.5.2
使用模块:requests、beautifulsoup4
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)程序运行返回爬去结果:
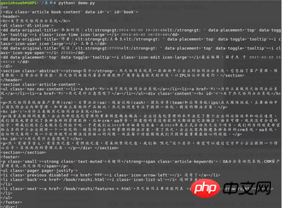
抓取成功
关于爬去结果乱码问题
其实起初我是直接用的系统默认自带的python2操作的,但在抓取返回内容的编码乱码问题上折腾了老半天,google了多种解决方案都无效。在被python2“整疯“之后,只好老老实实用python3了。对于python2的爬取页面内容乱码问题,欢迎各位前辈们分享经验,以帮助我等后生少走弯路。
以上是python3如何利用requests模块实现爬取页面内容的实例详解的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



![WLAN扩展模块已停止[修复]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN扩展模块已停止[修复]
Feb 19, 2024 pm 02:18 PM
WLAN扩展模块已停止[修复]
Feb 19, 2024 pm 02:18 PM
如果您的Windows计算机上的WLAN扩展模块出现问题,可能会导致您与互联网断开连接。这种情况常常让人感到困扰,但幸运的是,本文提供了一些简单的建议,可以帮助您解决这个问题,让您的无线连接重新正常运行。修复WLAN扩展模块已停止如果您的Windows计算机上的WLAN可扩展性模块已停止工作,请按照以下建议进行修复:运行网络和Internet故障排除程序禁用并重新启用无线网络连接重新启动WLAN自动配置服务修改电源选项修改高级电源设置重新安装网络适配器驱动程序运行一些网络命令现在,让我们来详细看
 WLAN可扩展性模块无法启动
Feb 19, 2024 pm 05:09 PM
WLAN可扩展性模块无法启动
Feb 19, 2024 pm 05:09 PM
本文详细介绍了解决事件ID10000的方法,该事件表明无线局域网扩展模块无法启动。在Windows11/10PC的事件日志中可能会显示此错误。WLAN可扩展性模块是Windows的一个组件,允许独立硬件供应商(IHV)和独立软件供应商(ISV)为用户提供定制的无线网络特性和功能。它通过增加Windows默认功能以扩展本机Windows网络组件的功能。在操作系统加载网络组件时,WLAN可扩展性模块作为初始化的一部分启动。如果无线局域网扩展模块遇到问题无法启动,您可能会在事件查看器的日志中看到错误消
 python中CURL和python requests的相互转换如何实现
May 03, 2023 pm 12:49 PM
python中CURL和python requests的相互转换如何实现
May 03, 2023 pm 12:49 PM
curl和Pythonrequests都是发送HTTP请求的强大工具。虽然curl是一种命令行工具,可让您直接从终端发送请求,但Python的请求库提供了一种更具编程性的方式来从Python代码中发送请求。将curl转换为Pythonrequestscurl命令的基本语法如下所示:curl[OPTIONS]URL将curl命令转换为Python请求时,我们需要将选项和URL转换为Python代码。这是一个示例curlPOST命令:curl-XPOSThttps://example.com/api
 Python爬虫Requests库怎么使用
May 16, 2023 am 11:46 AM
Python爬虫Requests库怎么使用
May 16, 2023 am 11:46 AM
1、安装requests库因为学习过程使用的是Python语言,需要提前安装Python,我安装的是Python3.8,可以通过命令python--version查看自己安装的Python版本,建议安装Python3.X以上的版本。安装好Python以后可以直接通过以下命令安装requests库。pipinstallrequestsPs:可以切换到国内的pip源,例如阿里、豆瓣,速度快为了演示功能,我这里使用nginx模拟了一个简单网站。下载好了以后,直接运行根目录下的nginx.exe程序就可
 Python常用标准库及第三方库2-sys模块
Apr 10, 2023 pm 02:56 PM
Python常用标准库及第三方库2-sys模块
Apr 10, 2023 pm 02:56 PM
一、sys模块简介前面介绍的os模块主要面向操作系统,而本篇的sys模块则主要针对的是Python解释器。sys模块是Python自带的模块,它是与Python解释器交互的一个接口。sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分。二、sys模块常用方法通过dir()方法可以查看sys模块中带有哪些方法:import sys print(dir(sys))1.sys.argv-获取命令行参数sys.argv作用是实现从程序外部向程序传递参数,它能够获取命令行参数列
 Python编程:详解命名元组(namedtuple)的使用要点
Apr 11, 2023 pm 09:22 PM
Python编程:详解命名元组(namedtuple)的使用要点
Apr 11, 2023 pm 09:22 PM
前言本文继续来介绍Python集合模块,这次主要简明扼要的介绍其内的命名元组,即namedtuple的使用。闲话少叙,我们开始——记得点赞、关注和转发哦~ ^_^创建命名元组Python集合中的命名元组类namedTuples为元组中的每个位置赋予意义,并增强代码的可读性和描述性。它们可以在任何使用常规元组的地方使用,且增加了通过名称而不是位置索引方式访问字段的能力。其来自Python内置模块collections。其使用的常规语法方式为:import collections XxNamedT
 Python如何使用Requests请求网页
Apr 25, 2023 am 09:29 AM
Python如何使用Requests请求网页
Apr 25, 2023 am 09:29 AM
Requests继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的URL和POST数据自动编码。安装方式利用pip安装$pipinstallrequestsGET请求基本GET请求(headers参数和parmas参数)1.最基本的GET请求可以直接用get方法'response=requests.get("http://www.baidu.com/"
 python requests post如何使用
Apr 29, 2023 pm 04:52 PM
python requests post如何使用
Apr 29, 2023 pm 04:52 PM
python模拟浏览器发送post请求importrequests格式request.postrequest.post(url,data,json,kwargs)#post请求格式request.get(url,params,kwargs)#对比get请求发送post请求传参分为表单(x-www-form-urlencoded)json(application/json)data参数支持字典格式和字符串格式,字典格式用json.dumps()方法把data转换为合法的json格式字符串次方法需要
