

python中如何django使用haystack:全文检索的框架的实例讲解

下面小编就为大家带来一篇python django使用haystack:全文检索的框架(实例讲解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
haystack:全文检索的框架
whoosh:纯Python编写的全文搜索引擎
jieba:一款免费的中文分词包
首先安装这三个包
pip install django-haystack
pip install whoosh
pip install jieba
1.修改settings.py文件,安装应用haystack,
2.在settings.py文件中配置搜索引擎
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
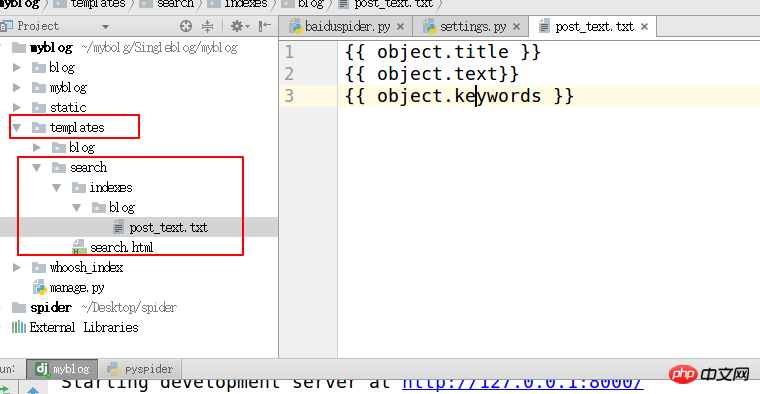
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3. 在templates目录下创建“search/indexes/blog/”目录 采用blog应用名字下面创建一个文件blog_text.txt
#指定索引的属性
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
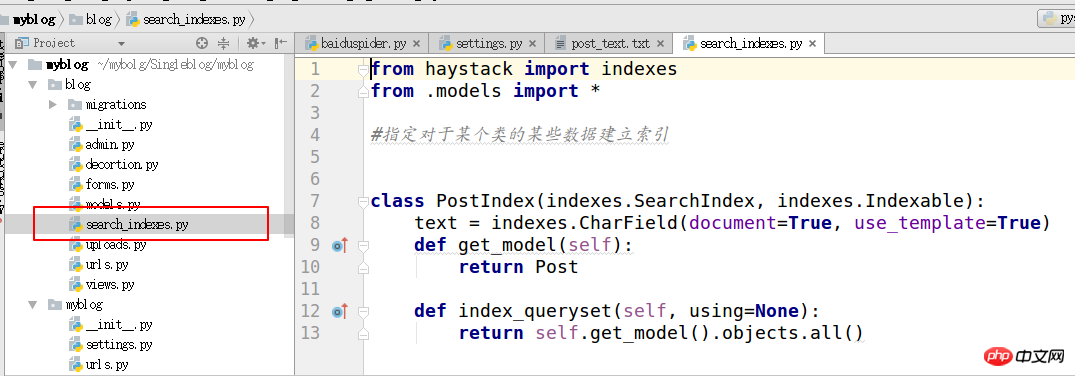
4.在需要搜索的应用下面创建search_indexes
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
5.
1. 修改haystack文件
2. 找到虚拟环境py_django下的haystack目录 这个目录根据自己使用的python环境不同,路径也不一样。
3. site-packages/haystack/backends/ 创建一个文件名为ChineseAnalyzer.py文件写入下面代码,用于中文分词
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()6.
1. 复制whoosh_backend.py文件,改为如下名称
whoosh_cn_backend.py
在复制出来的文件中导入中文分词模块
from .ChineseAnalyzer import ChineseAnalyzer
2. 更改词语分析类 改成中文
查找analyzer=StemmingAnalyzer()改为analyzer=ChineseAnalyzer()
7. 最后一步就是建初始化索引数据
python manage.py rebuild_index
8. 创建搜索模板 在templates/indexes/ 创建search.html模板
搜索结果进行分页,视图向模板中传递的上下文如下
query:搜索关键字
page:当前页的page对象
paginator:分页paginator对象
9. 在自己的应用视图中导入模块
from haystack.generic_views import SearchView
定义一个类重写get_context_data 方法,这样就可以往模板中传递自定义的上下文。
class GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
应用的urls文件中添加这条url 将类当一个视图的方法使用 .as_view()
url('^search/$', views.BlogSearchView.as_view())
以上是python中如何django使用haystack:全文检索的框架的实例讲解的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Linux系统自带Python解释器能删除吗?
Apr 02, 2025 am 07:00 AM
Linux系统自带Python解释器能删除吗?
Apr 02, 2025 am 07:00 AM
关于Linux系统自带Python解释器的删除问题许多Linux发行版在安装时会预装Python解释器,它并非通过软件包管理器�...
 如何解决Python中自定义装饰器的Pylance类型检测问题?
Apr 02, 2025 am 06:42 AM
如何解决Python中自定义装饰器的Pylance类型检测问题?
Apr 02, 2025 am 06:42 AM
使用自定义装饰器时的Pylance类型检测问题解决方法在Python编程中,装饰器是一种强大的工具,可以用于添加行�...
 Python 3.6加载Pickle文件报错"__builtin__"模块未找到怎么办?
Apr 02, 2025 am 07:12 AM
Python 3.6加载Pickle文件报错"__builtin__"模块未找到怎么办?
Apr 02, 2025 am 07:12 AM
Python3.6环境下加载Pickle文件报错:ModuleNotFoundError:Nomodulenamed...
 Debian Strings能否兼容多种浏览器
Apr 02, 2025 am 08:30 AM
Debian Strings能否兼容多种浏览器
Apr 02, 2025 am 08:30 AM
“DebianStrings”并非标准术语,其具体含义尚不明确。本文无法直接评论其浏览器兼容性。然而,如果“DebianStrings”指的是在Debian系统上运行的Web应用,则其浏览器兼容性取决于应用本身的技术架构。大多数现代Web应用都致力于跨浏览器兼容性。这依赖于遵循Web标准,并使用兼容性良好的前端技术(如HTML、CSS、JavaScript)以及后端技术(如PHP、Python、Node.js等)。为了确保应用与多种浏览器兼容,开发者通常需要进行跨浏览器测试,并使用响应式
 XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
修改XML内容需要编程,因为它需要精准找到目标节点才能增删改查。编程语言有相应库来处理XML,提供API像操作数据库一样进行安全、高效、可控的操作。
 手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF的速度取决于以下因素:XML结构的复杂性手机硬件配置转换方法(库、算法)代码质量优化手段(选择高效库、优化算法、缓存数据、利用多线程)总体而言,没有绝对的答案,需要根据具体情况进行优化。
 XML如何修改注释内容
Apr 02, 2025 pm 06:15 PM
XML如何修改注释内容
Apr 02, 2025 pm 06:15 PM
对于小型XML文件,可直接用文本编辑器替换注释内容;对于大型文件,建议借助XML解析器进行修改,确保效率和准确性。删除XML注释时需谨慎,保留注释通常有助于代码理解和维护。进阶技巧中提供了使用XML解析器修改注释的Python示例代码,但具体实现需根据使用的XML库进行调整。修改XML文件时注意编码问题,建议使用UTF-8编码并指定编码格式。
 有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
无法找到一款将 XML 直接转换为 PDF 的应用程序,因为它们是两种根本不同的格式。XML 用于存储数据,而 PDF 用于显示文档。要完成转换,可以使用编程语言和库,例如 Python 和 ReportLab,来解析 XML 数据并生成 PDF 文档。
