

Python3实现爬虫抓取网易云音乐的热门评论分析(图)

这篇文章主要给大家介绍了关于Python3实战之爬虫抓取网易云音乐热评的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。
前言
之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了。于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫。我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步。
废话就不多说了~下面来一起看看详细的介绍吧。
我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论。
这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论。
实现分析
首先,我们打开网易云网页版,如图:
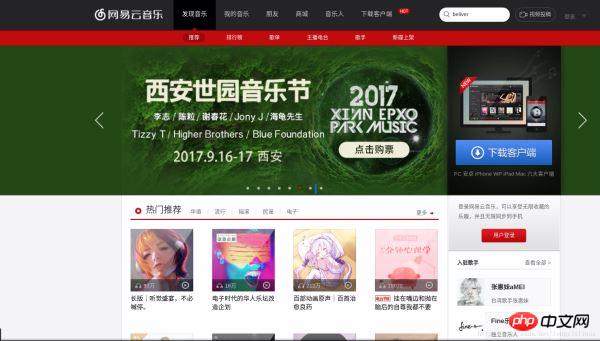
点击排行榜,然后点击左侧云音乐热歌榜,如图:
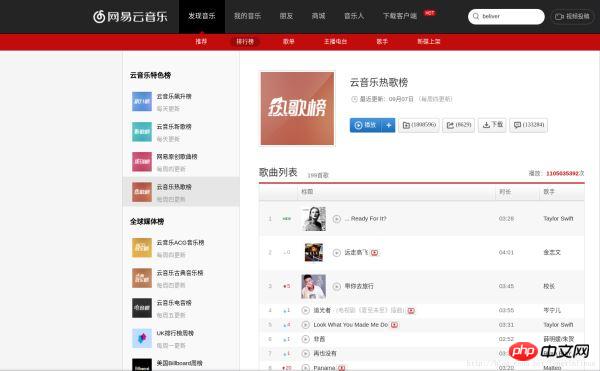
我们先随便打开一个歌曲,找到如何抓取指定的歌曲的热门歌评的方法,如图,我选了一个最近我比较喜欢的歌曲为例:
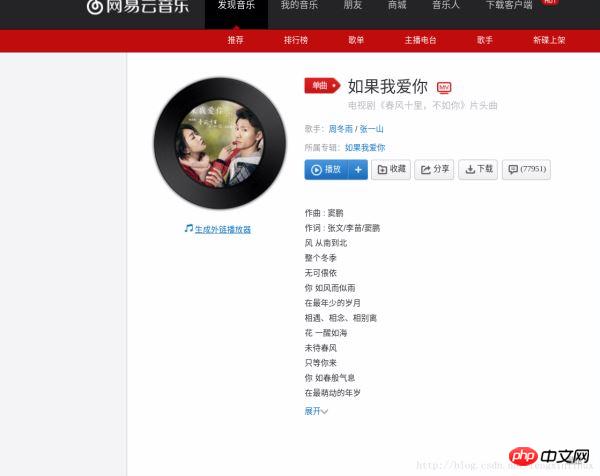
进去后我们会看到歌评就在这个页面的下面,接下来我们就要想办法获取这些评论。
接下来打开web控制台(chrom的话打开开发者工具,如果是其他浏览器应该也是类似),chrom下按F12,如图:
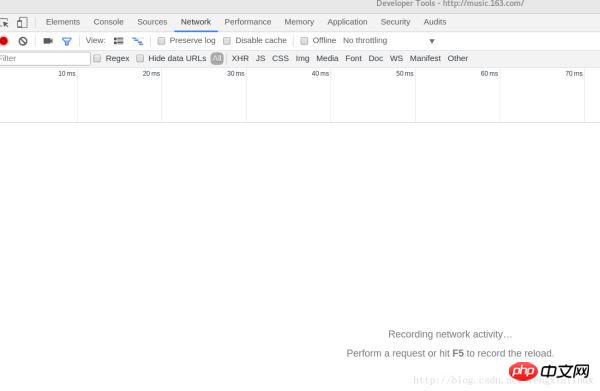
选则Network,然后我们按F5刷新一下,刷新之后得到的数据如下图所示:
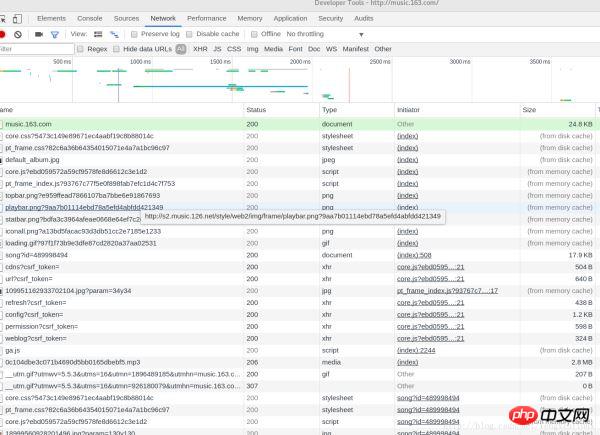
可以看到浏览器发送了非常多的信息,那么哪一个才是我们想要的呢?这里我们可以通过状态码做一个初步的判断,status code(状态码)标志了服务器请求的状态,这里状态码为200即表示请求正常,而304则表示不正常(状态码种类非常多,如果要想详细了解可以自行搜索,这里不说304具体的含义了)。所以我们一般只用看状态码为200的请求就可以了,还有就是,我们可以通过右边栏的预览来粗略观察服务器返回了什么信息(或者查看响应)。通过这两种方法结合一般我们就可以快速找到我们想要分析的请求。通过反复的查找,终于找到了含有歌评的请求,如图:
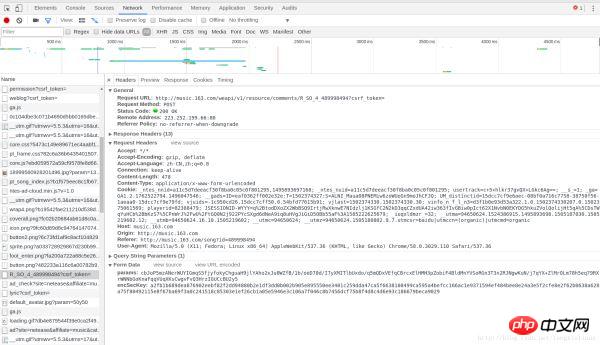
可能截图在CSDN上不是很清楚,我们在一个Name为R_SO_4_489998494?csrf_token=的POST请求中找到了包含这首歌的歌评。我们把这个分块截图发出来,这样可以看的清楚一些:
请求基本信息:

请求头部:
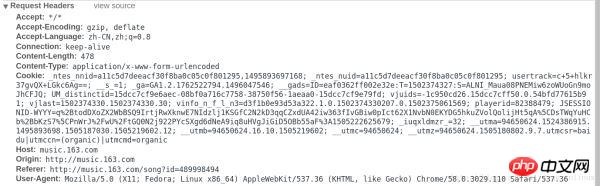
请求中的表单数据:

我们可以看到,包含这首歌歌评的请求url为http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= ,我们换了几首歌后发现,这个请求的前部分都是一样的,只是R_SO_4_后面紧跟的一串数字不一样。我们可以推测出,每一首歌都有一个指定的id,R_SO_4_后面紧跟的就是这首歌的id。
我们再看一下提交的表单数据,我们会发现表单中需要填两个数据,名称为params和encSecKey。后面紧跟的是一大串字符,换几首歌会发现,每首歌的params和encSecKey都是不一样的,因此,这两个数据可能经过一个特定的算法进行加密过的。
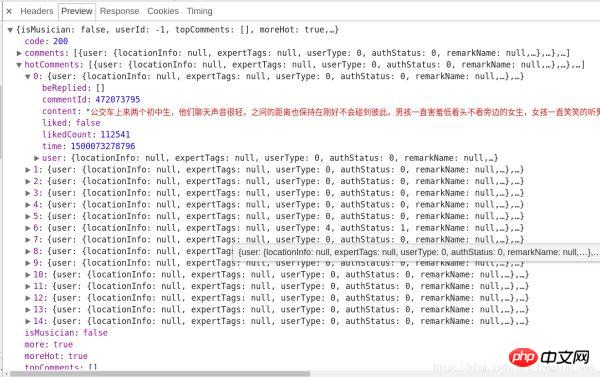
服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),其中hotComments就是我们要找的热门评论,总共15条,如图所示:
至此,我们已经确定了方向了,即只需要确定params和encSecKey这两个参数值即可。但是这两个参数是经过特定的算法进行加密的,怎么办呢?我发现了一个规律,http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= 中 R_SO_4_后面的数字就是这首歌的id值,而对于不同的歌曲的param和encSecKey值,如果把一首歌比如A的这两个参数值传给B这首歌,那么对于相同的页数,这种参数是通用的,即A的第一页的两个参数值传给其他任何一首歌的两个参数,都可以获得相应歌曲的第一页的评论,对于第二页,第三页等也是类似。
而我们其实只需要获取第一页的15条热门评论,所以我们只需要随便找一首歌,将这首歌第一页中的该请求中的params和encSecKey这两个参数值复制下来,就可以使用了。
关于这两个参数如何解密,强大的知乎上其实已经有答案的了,感兴趣的朋友可以进去看一下(https://www.zhihu.com/question/36081767),我们在这里就只需要用我们这种偷懒的办法就可以完成需求了,xixi。
到此为止,我们如何抓取网易云音乐的热门评论已经分析完了,我们再分析一下如何获取云音乐热歌榜中所有歌曲的信息。
我们需要获取云音乐热歌榜中的所有歌曲的歌曲名和对应的id值。
跟上面的分析步骤类似,我们先进入热歌榜的网址,如图:
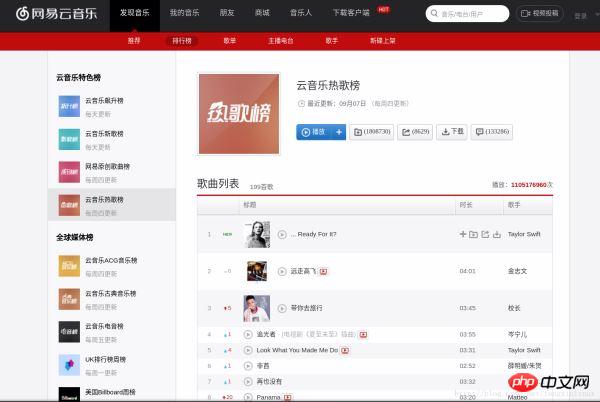
按F12,进入WEB工作台,如图:
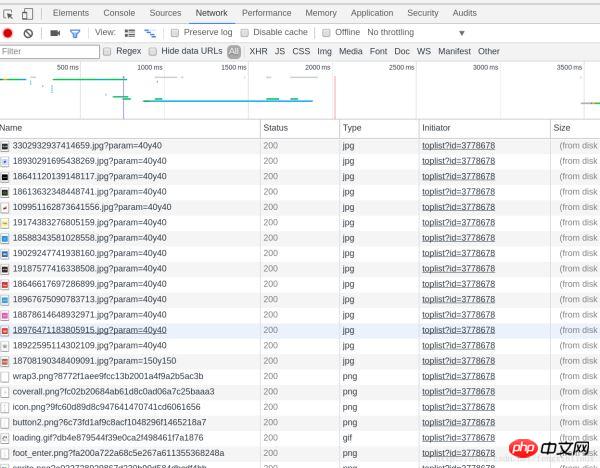
我们在一个名为toplist?id=3778678的GET请求中,找到了该榜单的所有歌曲信息。
请求对应的信息如图:
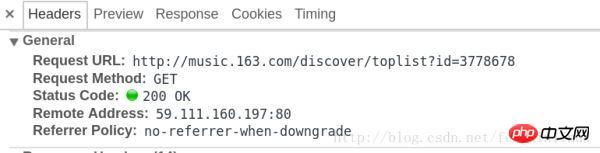
我们预览一下该请求返回的结果,如图:
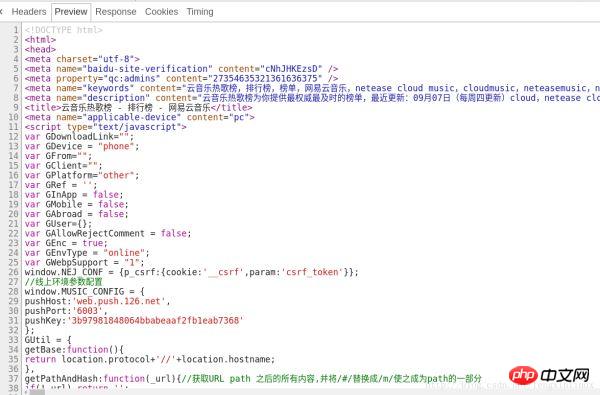
我们在代码的第524行我们找到了包含歌曲信息的代码,如图:
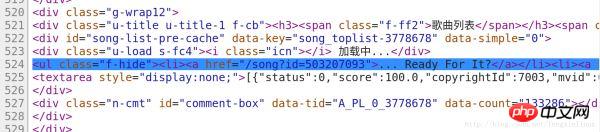
因此,我们只需要将该请求的代码中,将包含信息的代码筛选出来。
我们在这里使用正则表达式进行数据筛选。
通过观察特点,我们可以通过两次正则表达式的筛选,将我们需要的歌曲信息提取出来。
第一次正则表达式我们将该请求返回的所有代码中,提取出第525行代码。
第一次正则表达式如下:
<ul class="f-hide"> <li> <a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >.*</a> </li> </ul>
第二次正则表达式我们将该第524行中我们需要的歌曲信息提取出来,我们需要歌曲的歌名和id,对应的正则表达式如下:
获取歌名:
<li><a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>
获取歌曲的id:
<li><a href="/song\?id=(\d*?)" rel="external nofollow" rel="external nofollow" >.*?</a></li>
到此,我们整个过程已经分析完了,上代码看具体细节~~
代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import urllib.request
import urllib.error
import urllib.parse
import json
def get_all_hotSong(): #获取热歌榜所有歌曲名称和id
url='http://music.163.com/discover/toplist?id=3778678' #网易云云音乐热歌榜url
html=urllib.request.urlopen(url).read().decode('utf8') #打开url
html=str(html) #转换成str
pat1=r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' #进行第一次筛选的正则表达式
result=re.compile(pat1).findall(html) #用正则表达式进行筛选
result=result[0] #获取tuple的第一个元素
pat2=r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' #进行歌名筛选的正则表达式
pat3=r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' #进行歌ID筛选的正则表达式
hot_song_name=re.compile(pat2).findall(result) #获取所有热门歌曲名称
hot_song_id=re.compile(pat3).findall(result) #获取所有热门歌曲对应的Id
return hot_song_name,hot_song_id
def get_hotComments(hot_song_name,hot_song_id):
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' #歌评url
header={ #请求头部
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#post请求表单数据
data={'params':'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ','encSecKey':'4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
postdata=urllib.parse.urlencode(data).encode('utf8') #进行编码
request=urllib.request.Request(url,headers=header,data=postdata)
reponse=urllib.request.urlopen(request).read().decode('utf8')
json_dict=json.loads(reponse) #获取json
hot_commit=json_dict['hotComments'] #获取json中的热门评论
num=0
fhandle=open('./song_comments','a') #写入文件
fhandle.write(hot_song_name+':'+'\n')
for item in hot_commit:
num+=1
fhandle.write(str(num)+'.'+item['content']+'\n')
fhandle.write('\n==============================================\n\n')
fhandle.close()
hot_song_name,hot_song_id=get_all_hotSong() #获取热歌榜所有歌曲名称和id
num=0
while num < len(hot_song_name): #保存所有热歌榜中的热评
print('正在抓取第%d首歌曲热评...'%(num+1))
get_hotComments(hot_song_name[num],hot_song_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1码运行结果如下:
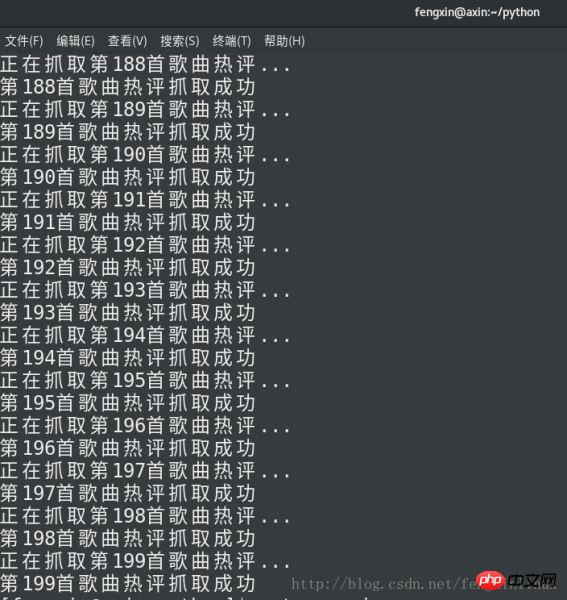
对比一下网页上《如果我爱你》这首歌的歌评和我们保存下的歌评:
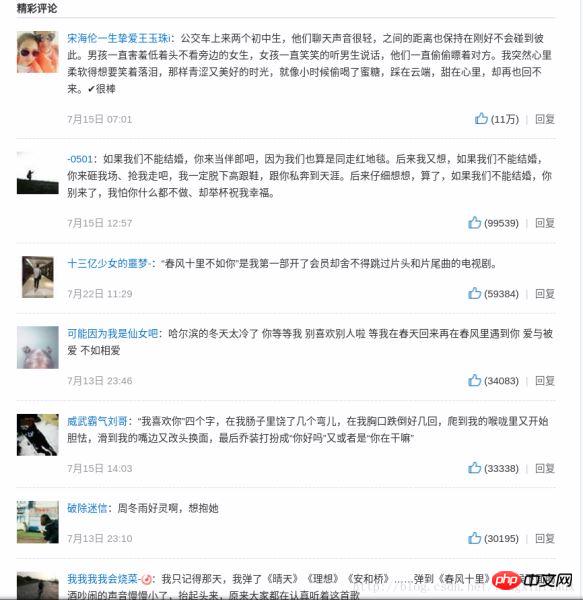

信息无误~
总结
以上是Python3实现爬虫抓取网易云音乐的热门评论分析(图)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 网易首款!5V5多英雄技能射击手游《天启行动》预约开启!
Mar 16, 2024 am 08:01 AM
网易首款!5V5多英雄技能射击手游《天启行动》预约开启!
Mar 16, 2024 am 08:01 AM
自2月国产游戏版号发布以来,网易的神秘射击游戏《天启行动》就吸引了不少玩家的好奇心。众所周知,网易早年虽然也有一些射击游戏,但好像除了《明日之后》与《荒野行动》之外,没有太多能打的作品。近几年,网易旗下推出的作品势头很猛,在众多小众赛道上都取得不菲的成绩。此前从未曝光过的《天启行动》被放在网易开年第一炮就足以让人侧目,这是网易要向射击赛道发起进攻的信号?在玩家对射击手游新品的翘首以盼中,3月13日,这款由网易自研的5V5多英雄技能射击手游《天启行动》,终于揭开了神秘面纱,正式发布了它的首个实机演
 网易X漫威官宣《漫威争锋》:全新超级英雄PVP团队射击游戏面世
Mar 28, 2024 pm 12:50 PM
网易X漫威官宣《漫威争锋》:全新超级英雄PVP团队射击游戏面世
Mar 28, 2024 pm 12:50 PM
北京时间2024年3月27日,网易游戏与漫威游戏正式官宣游戏新作:超级英雄PVP团队射击游戏《漫威争锋(MarvelRivals)》。玩家可以从丰富多样的超级英雄和超级反派阵容中,挑选心仪的角色组成全明星队伍,在漫威多元宇宙各种可破碎的地图上,利用独特的超能力进行精彩激战。“我们非常高兴将《漫威争锋》带给全世界的玩家。我们一直都很喜爱漫威宇宙及其角色,能够开发这款游戏让我们感到兴奋不已。”《漫威争锋》主创团队表示,“这正是我们梦寐以求想要打造的游戏,能够将它从梦想变为现实,我们无比骄傲。”“网易
 网易《漫威超级战争》宣布停运 曾是漫威首款MOBA游戏!
Apr 18, 2024 am 10:50 AM
网易《漫威超级战争》宣布停运 曾是漫威首款MOBA游戏!
Apr 18, 2024 am 10:50 AM
网易《漫威超级战争》宣布将于2024年6月17日15时终止运营并关闭游戏服务器。现在已关闭全平台下载入口,停止游戏充值、新用户注册。作为漫威的首款MOBA手游,这款游戏原汁原味地展现了超级英雄的战斗特色,还原了漫威宇宙宏大的世界观。在游戏中,您将能够与复仇者联盟、X战警、神奇四侠以及众多超级英雄和超级反派一起集结于平行宇宙,与钢铁侠、美国队长、蜘蛛侠、洛基、灭霸、死侍等超过60位经典漫威角色共同战斗!
 游戏版Sora?逆水寒手游发布AI影片生成工具,支持打字输入
Feb 26, 2024 pm 08:55 PM
游戏版Sora?逆水寒手游发布AI影片生成工具,支持打字输入
Feb 26, 2024 pm 08:55 PM
近日,逆水寒手游官方发布了全新的AI影片生成工具,玩家通过该工具“打打字就能出大片”。根据官方介绍,功能基于逆水寒游戏本体实现,由AI高度参与。不需要任何设备、演员、特效,只需要打字输入任意角色形象、动作、台词,就可以通过AI在游戏内实时生成相应内容,拍摄成片。同时,支持玩家对细节进行调整,包括角色的服装、妆造、发型、性格、声音等。该功能还支持上传图片/视频,通过AI进行动捕,在游戏内实时生成“游戏内没有”的动作与表情。官方表示,该功能和Sora有相同的愿景,即“让创作空间无穷无尽,让创作门槛接
 暴雪国服回归现场直击,瓦莉娜秀雪肤大长腿,粉裙Dva太可爱!
Apr 11, 2024 pm 04:04 PM
暴雪国服回归现场直击,瓦莉娜秀雪肤大长腿,粉裙Dva太可爱!
Apr 11, 2024 pm 04:04 PM
网易和微软暴雪已经正式宣布暴雪国服回归,网易还在总部大楼下搞了一个庆祝仪式,现场也非常精彩,让我们一起来直击现场!一大早现场就布置好了,暴雪全家桶的游戏全部在列,包括魔兽世界、炉石传说、暗黑破坏神3、风暴英雄、守望先锋、星际争霸2等,注意暴雪和网易的官方通告中并没有提风暴英雄,但是没有可以看到现场的海报是有这个游戏的,因此喜欢风暴英雄的玩家不用担心,暴雪全家桶整整齐齐都会回来。魔兽世界也要特别注意一下,展示的海报是魔兽世界11.0的地心之战,很显然这个梅森亲自抄刀的经典版本将会在今年夏天跟国服玩
 腾讯光子H工作室在杭州招人 计划做3A开放世界RPG
Feb 05, 2024 pm 01:45 PM
腾讯光子H工作室在杭州招人 计划做3A开放世界RPG
Feb 05, 2024 pm 01:45 PM
近期,腾讯互娱招聘公布了一则招聘信息,表明光子H工作室正致力于研发一款内容丰富、3A级别的开放世界RPG项目。此次热招岗位涵盖了UE5工程师、后台、关卡设计、动作场景设计、角色建模、特效及发行等多个领域,而这些岗位的目标工作地点位于网易总部所在地的杭州。
 网易大神注销之后还可以重新注册吗
Mar 07, 2024 pm 03:25 PM
网易大神注销之后还可以重新注册吗
Mar 07, 2024 pm 03:25 PM
网易大神APP是一个游戏玩家社交平台,用户可以在这里获得游戏咨询,有很多用户想知道网易大神注销之后可不可以重新注册,网易大神注销之后是可以重新注册的。网易大神注销之后还可以重新注册吗答:可以。1、网易大神注销之后是可以重新注册的。2、但是至少要注册了一星期之后才可以选择这个号码注册。3、账号是无法指定的,而以前的数据也都会被清除掉。4、用户注销后之前的所有信息和相关的余额等相关都已经清空了。相关文章:网易大神怎么改绑定手机号
 魔兽世界国服重开之际,4大版本选择指南,最后1个更适合休闲玩家
Apr 13, 2024 am 09:16 AM
魔兽世界国服重开之际,4大版本选择指南,最后1个更适合休闲玩家
Apr 13, 2024 am 09:16 AM
魔兽世界目前存在4个版本,国服关闭这一年多,估计很多玩家都不知道各版本发展到哪一步了,下面胖哥就给大家梳理一下各版本的现状。1,正式服10.0版本末期国服关闭前是10.0版本刚刚开始,目前已经处于10.26版本了,后面还有一个10.27版本,巨龙时代资料片就结束了。虽然10.0版本在外服的评价不错,并且为暴雪挽回了一些人气,但是10.0版本的游戏内核是没有任何变化的,依然是大秘境和团本为主,PVP玩家人数少之又少。随着正式服版本的不断更新,玩家们的游戏倾向也从PVE和PVP变成了收集,每月商栈上
