

K-means算法在Python中的实现

K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低。
K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法。k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。本文将和大家介绍K-means算法在Python中的实现。
核心思想
通过迭代寻找k个类簇的一种划分方案,使得用这k个类簇的均值来代表相应各类样本时所得的总体误差最小。
k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
k-means算法的基础是最小误差平方和准则,K-menas的优缺点:
优点:
原理简单
速度快
对大数据集有比较好的伸缩性
缺点:
需要指定聚类 数量K
对异常值敏感
对初始值敏感
K-means的聚类过程
其聚类过程类似于梯度下降算法,建立代价函数并通过迭代使得代价函数值越来越小
适当选择c个类的初始中心;
在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
利用均值等方法更新该类的中心值;
对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
K-means 实例展示
python中km的一些参数:
sklearn.cluster.KMeans( n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto' ) n_clusters: 簇的个数,即你想聚成几类 init: 初始簇中心的获取方法 n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。 max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代) tol: 容忍度,即kmeans运行准则收敛的条件 precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的 verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值) random_state: 随机生成簇中心的状态条件。 copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。 n_jobs: 并行设置 algorithm: kmeans的实现算法,有:'auto', ‘full', ‘elkan', 其中 ‘full'表示用EM方式实现 虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
下面展示一个代码例子
from sklearn.cluster import KMeans from sklearn.externals import joblib from sklearn import cluster import numpy as np # 生成10*3的矩阵 data = np.random.rand(10,3) print data # 聚类为4类 estimator=KMeans(n_clusters=4) # fit_predict表示拟合+预测,也可以分开写 res=estimator.fit_predict(data) # 预测类别标签结果 lable_pred=estimator.labels_ # 各个类别的聚类中心值 centroids=estimator.cluster_centers_ # 聚类中心均值向量的总和 inertia=estimator.inertia_ print lable_pred print centroids print inertia 代码执行结果 [0 2 1 0 2 2 0 3 2 0] [[ 0.3028348 0.25183096 0.62493622] [ 0.88481287 0.70891813 0.79463764] [ 0.66821961 0.54817207 0.30197415] [ 0.11629904 0.85684903 0.7088385 ]] 0.570794546829
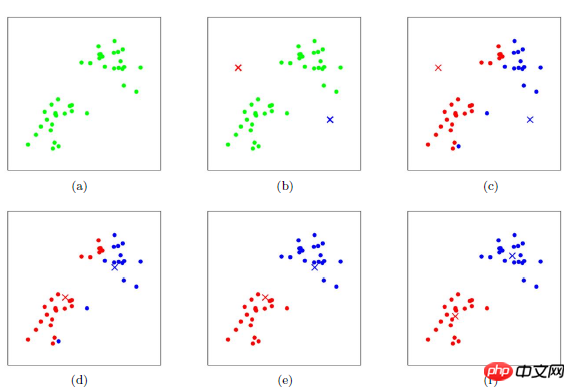
为了更直观的描述,这次在图上做一个展示,由于图像上绘制二维比较直观,所以数据调整到了二维,选取100个点绘制,聚类类别为3类
from sklearn.cluster import KMeans
from sklearn.externals import joblib
from sklearn import cluster
import numpy as np
import matplotlib.pyplot as plt
data = np.random.rand(100,2)
estimator=KMeans(n_clusters=3)
res=estimator.fit_predict(data)
lable_pred=estimator.labels_
centroids=estimator.cluster_centers_
inertia=estimator.inertia_
#print res
print lable_pred
print centroids
print inertia
for i in range(len(data)):
if int(lable_pred[i])==0:
plt.scatter(data[i][0],data[i][1],color='red')
if int(lable_pred[i])==1:
plt.scatter(data[i][0],data[i][1],color='black')
if int(lable_pred[i])==2:
plt.scatter(data[i][0],data[i][1],color='blue')
plt.show()
可以看到聚类效果还是不错的,对k-means的聚类效率进行了一个测试,将维度扩宽到50维
| 数据规模 | 消耗时间 | 数据维度 |
|---|---|---|
| 10000条 | 4s | 50维 |
| 100000条 | 30s | 50维 |
| 1000000条 | 4'13s | 50维 |
对于百万级的数据,拟合时间还是能够接受的,可见效率还是不错,对模型的保存与其它的机器学习算法模型保存类似
from sklearn.externals import joblib joblib.dump(km,"model/km_model.m")
以上内容就是K-means算法在Python中的实现,希望能帮助到大家。
相关推荐:
以上是K-means算法在Python中的实现的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
MySQL 有免费的社区版和收费的企业版。社区版可免费使用和修改,但支持有限,适合稳定性要求不高、技术能力强的应用。企业版提供全面商业支持,适合需要稳定可靠、高性能数据库且愿意为支持买单的应用。选择版本时考虑的因素包括应用关键性、预算和技术技能。没有完美的选项,只有最合适的方案,需根据具体情况谨慎选择。
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 mySQL下载完安装不了
Apr 08, 2025 am 11:24 AM
mySQL下载完安装不了
Apr 08, 2025 am 11:24 AM
MySQL安装失败的原因主要有:1.权限问题,需以管理员身份运行或使用sudo命令;2.依赖项缺失,需安装相关开发包;3.端口冲突,需关闭占用3306端口的程序或修改配置文件;4.安装包损坏,需重新下载并验证完整性;5.环境变量配置错误,需根据操作系统正确配置环境变量。解决这些问题,仔细检查每个步骤,就能顺利安装MySQL。
 mysql下载文件损坏无法安装的修复方案
Apr 08, 2025 am 11:21 AM
mysql下载文件损坏无法安装的修复方案
Apr 08, 2025 am 11:21 AM
MySQL下载文件损坏,咋整?哎,下载个MySQL都能遇到文件损坏,这年头真是不容易啊!这篇文章就来聊聊怎么解决这个问题,让大家少走弯路。读完之后,你不仅能修复损坏的MySQL安装包,还能对下载和安装过程有更深入的理解,避免以后再踩坑。先说说为啥下载文件会损坏这原因可多了去了,网络问题是罪魁祸首,下载过程中断、网络不稳定都可能导致文件损坏。还有就是下载源本身的问题,服务器文件本身就坏了,你下载下来当然也是坏的。另外,一些杀毒软件过度“热情”的扫描也可能造成文件损坏。诊断问题:确定文件是否真的损坏
 mysql 需要互联网吗
Apr 08, 2025 pm 02:18 PM
mysql 需要互联网吗
Apr 08, 2025 pm 02:18 PM
MySQL 可在无需网络连接的情况下运行,进行基本的数据存储和管理。但是,对于与其他系统交互、远程访问或使用高级功能(如复制和集群)的情况,则需要网络连接。此外,安全措施(如防火墙)、性能优化(选择合适的网络连接)和数据备份对于连接到互联网的 MySQL 数据库至关重要。
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 MySQL安装后服务无法启动的解决办法
Apr 08, 2025 am 11:18 AM
MySQL安装后服务无法启动的解决办法
Apr 08, 2025 am 11:18 AM
MySQL拒启动?别慌,咱来排查!很多朋友安装完MySQL后,发现服务死活启动不了,心里那个急啊!别急,这篇文章带你从容应对,揪出幕后黑手!读完后,你不仅能解决这个问题,还能提升对MySQL服务的理解,以及排查问题的思路,成为一名更强大的数据库管理员!MySQL服务启动失败,原因五花八门,从简单的配置错误到复杂的系统问题都有可能。咱们先从最常见的几个方面入手。基础知识:服务启动流程简述MySQL服务启动,简单来说,就是操作系统加载MySQL相关的文件,然后启动MySQL守护进程。这其中涉及到配置
 mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
MySQL性能优化需从安装配置、索引及查询优化、监控与调优三个方面入手。1.安装后需根据服务器配置调整my.cnf文件,例如innodb_buffer_pool_size参数,并关闭query_cache_size;2.创建合适的索引,避免索引过多,并优化查询语句,例如使用EXPLAIN命令分析执行计划;3.利用MySQL自带监控工具(SHOWPROCESSLIST,SHOWSTATUS)监控数据库运行状况,定期备份和整理数据库。通过这些步骤,持续优化,才能提升MySQL数据库性能。
