

详解神经网络理论基础及Python实现方法

人工神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的,并具有自学习和自适应的能力。本文主要介绍了神经网络理论基础及Python实现详解,具有一定借鉴价值,需要的朋友可以参考下,希望能帮助到大家。
一、多层前向神经网络
多层前向神经网络由三部分组成:输出层、隐藏层、输出层,每层由单元组成;
输入层由训练集的实例特征向量传入,经过连接结点的权重传入下一层,前一层的输出是下一层的输入;隐藏层的个数是任意的,输入层只有一层,输出层也只有一层;
除去输入层之外,隐藏层和输出层的层数和为n,则该神经网络称为n层神经网络,如下图为2层的神经网络;
一层中加权求和,根据非线性方程进行转化输出;理论上,如果有足够多的隐藏层和足够大的训练集,可以模拟出任何方程;
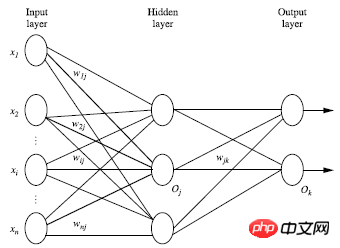
二、设计神经网络结构
使用神经网络之前,必须要确定神经网络的层数,以及每层单元的个数;
为了加速学习过程,特征向量在传入输入层前,通常需要标准化到0和1之间;
离散型变量可以被编码成每一个输入单元对应一个特征值可能赋的值
比如:特征值A可能去三个值(a0,a1,a2),那么可以使用3个输入单元来代表A
如果A=a0,则代表a0的单元值取1,其余取0;
如果A=a1,则代表a1的单元值取1,其余取0;
如果A=a2,则代表a2的单元值取1,其余取0;

神经网络既解决分类(classification)问题,也可以解决回归(regression)问题。对于分类问题,如果是两类,则可以用一个输出单元(0和1)分别表示两类;如果多余两类,则每一个类别用一个输出单元表示,所以输出层的单元数量通常等一类别的数量。
没有明确的规则来设计最佳个数的隐藏层,一般根据实验测试误差和准确率来改进实验。
三、交叉验证方法
如何计算准确率?最简单的方法是通过一组训练集和测试集,训练集通过训练得到模型,将测试集输入模型得到测试结果,将测试结果和测试集的真实标签进行比较,得到准确率。
在机器学习领域一个常用的方法是交叉验证方法。一组数据不分成2份,可能分为10份,
第1次:第1份作为测试集,剩余9份作为训练集;
第2次:第2份作为测试集,剩余9份作为训练集;
……
这样经过10次训练,得到10组准确率,将这10组数据求平均值得到平均准确率的结果。这里10是特例。一般意义上将数据分为k份,称该算法为K-foldcrossvalidation,即每一次选择k份中的一份作为测试集,剩余k-1份作为训练集,重复k次,最终得到平均准确率,是一种比较科学准确的方法。

四、BP算法
通过迭代来处理训练集中的实例;
对比经过神经网络后预测值与真实值之间的差;
反方向(从输出层=>隐藏层=>输入层)来最小化误差,来更新每个连接的权重;
4.1、算法详细介绍
输入:数据集、学习率、一个多层神经网络构架;
输出:一个训练好的神经网络;
初始化权重和偏向:随机初始化在-1到1之间(或者其他),每个单元有一个偏向;对于每一个训练实例X,执行以下步骤:
1、由输入层向前传送:
结合神经网络示意图进行分析:

由输入层到隐藏层:

由隐藏层到输出层:

两个公式进行总结,可以得到:

Ij为当前层单元值,Oi为上一层的单元值,wij为两层之间,连接两个单元值的权重值,sitaj为每一层的偏向值。我们要对每一层的输出进行非线性的转换,示意图如下:

当前层输出为Ij,f为非线性转化函数,又称为激活函数,定义如下:

即每一层的输出为:

这样就可以通过输入值正向得到每一层的输出值。
2、根据误差反向传送对于输出层:其中Tk是真实值,Ok是预测值

对于隐藏层:

权重更新:其中l为学习率

偏向更新:

3、终止条件
偏重的更新低于某个阈值;
预测的错误率低于某个阈值;
达到预设一定的循环次数;
4、非线性转化函数
上面提到的非线性转化函数f,一般情况下可以用两种函数:
(1)tanh(x)函数:
tanh(x)=sinh(x)/cosh(x)
sinh(x)=(exp(x)-exp(-x))/2
cosh(x)=(exp(x)+exp(-x))/2
(2)逻辑函数,本文上面用的就是逻辑函数
五、BP神经网络的python实现
需要先导入numpy模块
import numpy as np
定义非线性转化函数,由于还需要用到给函数的导数形式,因此一起定义
def tanh(x): return np.tanh(x) def tanh_deriv(x): return 1.0 - np.tanh(x)*np.tanh(x) def logistic(x): return 1/(1 + np.exp(-x)) def logistic_derivative(x): return logistic(x)*(1-logistic(x))
设计BP神经网络的形式(几层,每层多少单元个数),用到了面向对象,主要是选择哪种非线性函数,以及初始化权重。layers是一个list,里面包含每一层的单元个数。
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25)实现算法
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X)
temp = np.ones([X.shape[0], X.shape[1]+1])
temp[:, 0:-1] = X
X = temp
y = np.array(y)
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)):
a.append(self.activation(np.dot(a[l], self.weights[l])))
error = y[i] - a[-1]
deltas = [error * self.activation_deriv(a[-1])]
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)实现预测
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0]+1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a我们给出一组数进行预测,我们上面的程序文件保存名称为BP
from BP import NeuralNetwork import numpy as np nn = NeuralNetwork([2,2,1], 'tanh') x = np.array([[0,0], [0,1], [1,0], [1,1]]) y = np.array([1,0,0,1]) nn.fit(x,y,0.1,10000) for i in [[0,0], [0,1], [1,0], [1,1]]: print(i, nn.predict(i))
结果如下:
([0, 0], array([ 0.99738862])) ([0, 1], array([ 0.00091329])) ([1, 0], array([ 0.00086846])) ([1, 1], array([ 0.99751259]))
相关推荐:
以上是详解神经网络理论基础及Python实现方法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 xml格式怎么打开
Apr 02, 2025 pm 09:00 PM
xml格式怎么打开
Apr 02, 2025 pm 09:00 PM
用大多数文本编辑器即可打开XML文件;若需更直观的树状展示,可使用 XML 编辑器,如 Oxygen XML Editor 或 XMLSpy;在程序中处理 XML 数据则需使用编程语言(如 Python)与 XML 库(如 xml.etree.ElementTree)来解析。
 xml格式如何美化
Apr 02, 2025 pm 09:57 PM
xml格式如何美化
Apr 02, 2025 pm 09:57 PM
XML 美化本质上是提高其可读性,包括合理的缩进、换行和标签组织。其原理是通过遍历 XML 树,根据层级增加缩进,并处理空标签和包含文本的标签。Python 的 xml.etree.ElementTree 库提供了方便的 pretty_xml() 函数,可以实现上述美化过程。
 XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
修改XML内容需要编程,因为它需要精准找到目标节点才能增删改查。编程语言有相应库来处理XML,提供API像操作数据库一样进行安全、高效、可控的操作。
 有没有免费的手机XML转PDF工具?
Apr 02, 2025 pm 09:12 PM
有没有免费的手机XML转PDF工具?
Apr 02, 2025 pm 09:12 PM
没有简单、直接的免费手机端XML转PDF工具。需要的数据可视化过程涉及复杂的数据理解和渲染,市面上所谓的“免费”工具大多体验较差。推荐使用电脑端的工具或借助云服务,或自行开发App以获得更靠谱的转换效果。
 手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF的速度取决于以下因素:XML结构的复杂性手机硬件配置转换方法(库、算法)代码质量优化手段(选择高效库、优化算法、缓存数据、利用多线程)总体而言,没有绝对的答案,需要根据具体情况进行优化。
 手机上如何将XML转换成PDF?
Apr 02, 2025 pm 10:18 PM
手机上如何将XML转换成PDF?
Apr 02, 2025 pm 10:18 PM
直接在手机上将XML转换为PDF并不容易,但可以借助云端服务实现。推荐使用轻量级手机App上传XML文件并接收生成的PDF,配合云端API进行转换。云端API使用无服务器计算服务,选择合适的平台至关重要。处理XML解析和PDF生成时需要考虑复杂性、错误处理、安全性和优化策略。整个过程需要前端App与后端API协同工作,需要对多种技术有所了解。
 有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
无法找到一款将 XML 直接转换为 PDF 的应用程序,因为它们是两种根本不同的格式。XML 用于存储数据,而 PDF 用于显示文档。要完成转换,可以使用编程语言和库,例如 Python 和 ReportLab,来解析 XML 数据并生成 PDF 文档。
 xml格式化工具推荐
Apr 02, 2025 pm 09:03 PM
xml格式化工具推荐
Apr 02, 2025 pm 09:03 PM
XML格式化工具可以将代码按照规则排版,提高可读性和理解性。选择工具时,要注意自定义能力、对特殊情况的处理、性能和易用性。常用的工具类型包括在线工具、IDE插件和命令行工具。
