

CSS选择器字段解析的实现方法

根据上面所学的CSS基础语法知识,现在来实现字段的解析。首先还是解析标题。打开网页开发者工具,找到标题所对应的源代码。本文主要介绍了CSS选择器实现字段解析的相关资料,需要的朋友可以参考下,希望能帮助到大家
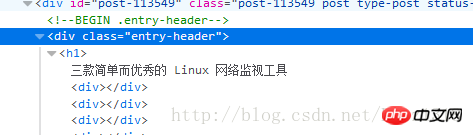
发现是在p class="entry-header"下面的h1节点中,于是打开scrapy shell 进行调试

但是我不想要
这种标签该咋办,这时候就要使用CSS选择器中的伪类方法。如下所示。

注意的是两个冒号。使用CSS选择器真的很方便。同理我用CSS实现字段解析。代码如下
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass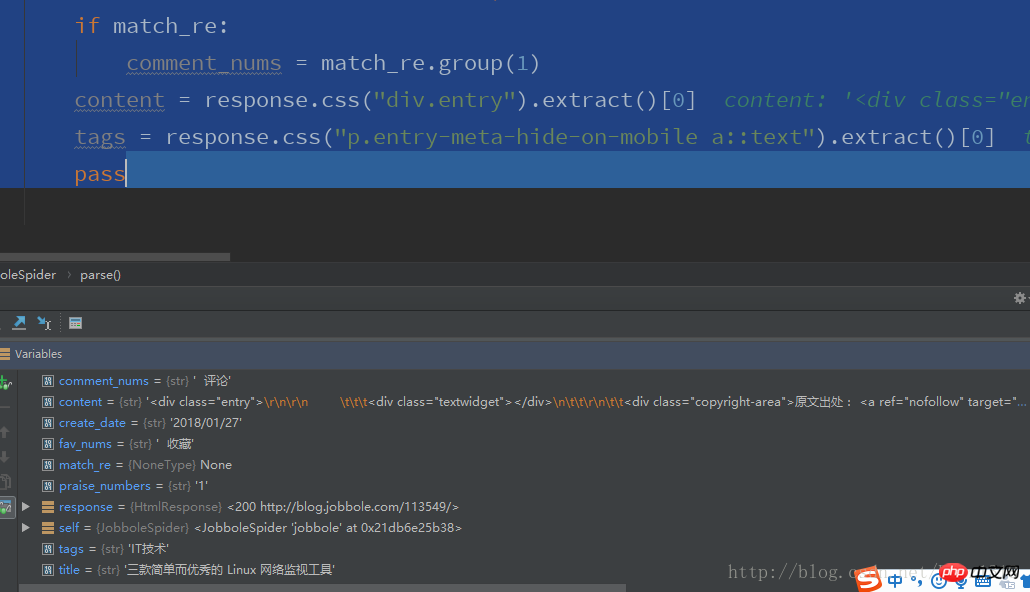
相关推荐:
以上是CSS选择器字段解析的实现方法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 bootstrap怎么写分割线
Apr 07, 2025 pm 03:12 PM
bootstrap怎么写分割线
Apr 07, 2025 pm 03:12 PM
创建 Bootstrap 分割线有两种方法:使用 标签,可创建水平分割线。使用 CSS border 属性,可创建自定义样式的分割线。
 bootstrap怎么插入图片
Apr 07, 2025 pm 03:30 PM
bootstrap怎么插入图片
Apr 07, 2025 pm 03:30 PM
在 Bootstrap 中插入图片有以下几种方法:直接插入图片,使用 HTML 的 img 标签。使用 Bootstrap 图像组件,可以提供响应式图片和更多样式。设置图片大小,使用 img-fluid 类可以使图片自适应。设置边框,使用 img-bordered 类。设置圆角,使用 img-rounded 类。设置阴影,使用 shadow 类。调整图片大小和位置,使用 CSS 样式。使用背景图片,使用 background-image CSS 属性。
 bootstrap怎么调整大小
Apr 07, 2025 pm 03:18 PM
bootstrap怎么调整大小
Apr 07, 2025 pm 03:18 PM
要调整 Bootstrap 中元素大小,可以使用尺寸类,具体包括:调整宽度:.col-、.w-、.mw-调整高度:.h-、.min-h-、.max-h-
 bootstrap怎么设置框架
Apr 07, 2025 pm 03:27 PM
bootstrap怎么设置框架
Apr 07, 2025 pm 03:27 PM
要设置 Bootstrap 框架,需要按照以下步骤:1. 通过 CDN 引用 Bootstrap 文件;2. 下载文件并将其托管在自己的服务器上;3. 在 HTML 中包含 Bootstrap 文件;4. 根据需要编译 Sass/Less;5. 导入定制文件(可选)。设置完成后,即可使用 Bootstrap 的网格系统、组件和样式创建响应式网站和应用程序。
 HTML,CSS和JavaScript的角色:核心职责
Apr 08, 2025 pm 07:05 PM
HTML,CSS和JavaScript的角色:核心职责
Apr 08, 2025 pm 07:05 PM
HTML定义网页结构,CSS负责样式和布局,JavaScript赋予动态交互。三者在网页开发中各司其职,共同构建丰富多彩的网站。
 bootstrap按钮怎么用
Apr 07, 2025 pm 03:09 PM
bootstrap按钮怎么用
Apr 07, 2025 pm 03:09 PM
如何使用 Bootstrap 按钮?引入 Bootstrap CSS创建按钮元素并添加 Bootstrap 按钮类添加按钮文本
 vue中怎么用bootstrap
Apr 07, 2025 pm 11:33 PM
vue中怎么用bootstrap
Apr 07, 2025 pm 11:33 PM
在 Vue.js 中使用 Bootstrap 分为五个步骤:安装 Bootstrap。在 main.js 中导入 Bootstrap。直接在模板中使用 Bootstrap 组件。可选:自定义样式。可选:使用插件。
 bootstrap怎么看日期
Apr 07, 2025 pm 03:03 PM
bootstrap怎么看日期
Apr 07, 2025 pm 03:03 PM
答案:可以使用 Bootstrap 的日期选择器组件在页面中查看日期。步骤:引入 Bootstrap 框架。在 HTML 中创建日期选择器输入框。Bootstrap 将自动为选择器添加样式。使用 JavaScript 获取选定的日期。
