

NodeJS爬虫详解

一、爬虫流程
我们最终的目标是实现爬取立马理财每日的销售额,并知道卖了哪些产品,每个产品又被哪些用户在什么时间点买的。首先,介绍下爬虫爬取的主要步骤:
1. 结构分析
我们要爬取页面的数据,第一步当然是要先分析清楚页面结构,要爬哪些页面,页面的结构是怎样的,需不需要登录;有没有ajax接口,返回什么样的数据等。
2. 数据抓取
分析清楚要爬取哪些页面和ajax,就要去抓取数据了。如今的网页的数据,大体分为同步页面和ajax接口。同步页面数据的抓取就需要我们先分析网页的结构,python抓取数据一般是通过正则表达式匹配来获取需要的数据;node有一个cheerio的工具,可以将获取的页面内容转换成jquery对象,然后就可以用jquery强大的dom API来获取节点相关数据, 其实大家看源码,这些API本质也就是正则匹配。ajax接口数据一般都是json格式的,处理起来还是比较简单的。
3. 数据存储
抓取的数据后,会做简单的筛选,然后将需要的数据先保存起来,以便后续的分析处理。当然我们可以用MySQL和Mongodb等数据库存储数据。这里,我们为了方便,直接采用文件存储。
4. 数据分析
因为我们最终是要展示数据的,所以我们要将原始的数据按照一定维度去处理分析,然后返回给客户端。这个过程可以在存储的时候去处理,也可以在展示的时候,前端发送请求,后台取出存储的数据再处理。这个看我们要怎么展示数据了。
5. 结果展示
做了这么多工作,一点展示输出都没有,怎么甘心呢?这又回到了我们的老本行,前端展示页面大家应该都很熟悉了。将数据展示出来才更直观,方便我们分析统计。
二、爬虫常用库介绍
1. Superagent
Superagent是个轻量的的http方面的库,是nodejs里一个非常方便的客户端请求代理模块,当我们需要进行get、post、head等网络请求时,尝试下它吧。
2. Cheerio
Cheerio大家可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一模一样。
3. Async
Async是一个流程控制工具包,提供了直接而强大的异步功能mapLimit(arr, limit, iterator, callback),我们主要用到这个方法,大家可以去看看官网的API。
4. arr-del
arr-del是我自己写的一个删除数组元素方法的工具。可以通过传入待删除数组元素index组成的数组进行一次性删除。
5. arr-sort
arr-sort是我自己写的一个数组排序方法的工具。可以根据一个或者多个属性进行排序,支持嵌套的属性。而且可以再每个条件中指定排序的方向,并支持传入比较函数。
三、页面结构分析
先屡一下我们爬取的思路。立马理财线上的产品主要是定期和立马金库(最新上线的光大银行理财产品因为手续比较麻烦,而且起投金额高,基本没人买,这里不统计)。定期我们可以爬取理财页的ajax接口:https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=0。(update: 定期近期没货,可能看不到数据)数据如下图所示:
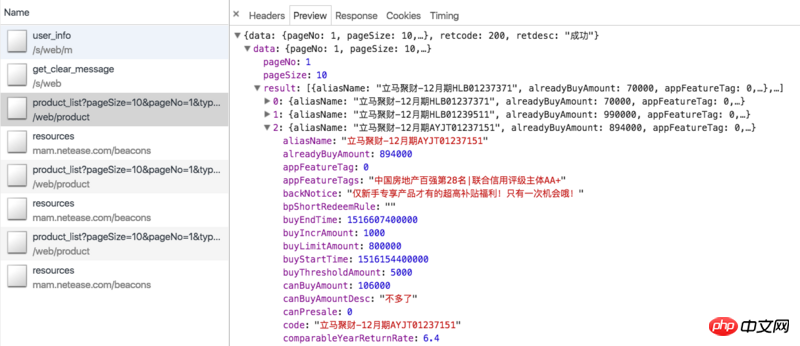
这里包含了所有线上正在销售的定期产品,ajax数据只有产品本身相关的信息,比如产品id、筹集金额、当前销售额、年化收益率、投资天数等,并没有产品被哪些用户购买的信息。所以我们需要带着id参数去它的产品详情页爬取,比如立马聚财-12月期HLB01239511。详情页有一栏投资记录,里边包含了我们需要的信息,如下图所示:
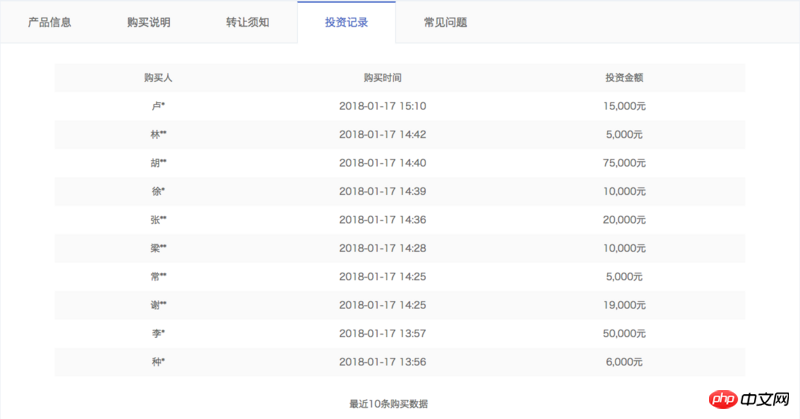
但是,详情页需要我们在登录的状态下才可以查看,这就需要我们带着cookie去访问,而且cookie是有有效期限制的,如何保持我们cookie一直在登录态呢?请看后文。
其实立马金库也有类似的ajax接口:https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1,但是里边的相关数据都是写死的,没有意义。而且金库的详情页也没有投资记录信息。这就需要我们爬取一开始说的首页的ajax接口:https://www.lmlc.com/s/web/home/user_buying。但是后来才发现这个接口是三分钟更新一次,就是说后台每隔三分钟向服务器请求一次数据。而一次是10条数据,所以如果在三分钟内,购买产品的记录数超过10条,数据就会有遗漏。这是没有办法的,所以立马金库的统计数据会比真实的偏少。
四、爬虫代码分析
1. 获取登录cookie
因为产品详情页需要登录,所以我们要先拿到登录的cookie才行。getCookie方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}phone和password参数是从命令行里传进来的,就是立马理财用手机号登录的账号和密码。我们用superagent去模拟请求立马理财登录接口:https://www.lmlc.com/user/s/web/logon。传入相应的参数,在回调中,我们拿到header的set-cookie信息,并发出一个setCookeie事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),所以一旦获取cookie,我们就会去执行requestData方法。
2. 理财页ajax的爬取
requestData方法的代码如下:
function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i<len; i++){
if(+new Date() < addData.result[i].buyStartTime){
if(preIds.indexOf(addData.result[i].id) == -1){
preIds.push(addData.result[i].id);
setPreId(addData.result[i].buyStartTime, addData.result[i].id);
}
}else{
pageUrls.push('https://www.lmlc.com/web/product/product_detail.html?id=' + addData.result[i].id);
}
}
function setPreId(time, id){
cache[id] = setInterval(function(){
if(time - (+new Date()) < 1000){
// 预售产品开始抢购,直接修改爬取频次为1s,防止丢失数据
clearInterval(cache[id]);
clearInterval(timer);
delay = 1000;
timer = setInterval(function(){
requestData();
}, delay);
// 同时删除id记录
let index = preIds.indexOf(id);
sort.delArrByIndex(preIds, [index]);
}
}, 1000)
}
// 处理售卖金额信息
let oldData = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
for(let i=0, len=formatedAddData.length; i<len; i++){
let isNewProduct = true;
for(let j=0, len2=oldData.length; j<len2; j++){
if(formatedAddData[i].productId === oldData[j].productId){
isNewProduct = false;
}
}
if(isNewProduct){
oldData.push(formatedAddData[i]);
}
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`理财列表ajax接口爬取完毕,时间:${time}`).warn);
if(!pageUrls.length){
delay = 32*1000;
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
return
}
getDetailData();
});
}代码很长,getDetailData函数代码后面分析。
请求的ajax接口是个分页接口,因为一般在售的总产品数不会超过10条,我们这里设置参数pageSize为100,这样就可以一次性获取所有产品。
clearProd是全局reset信号,每天0点整的时候,会清空prod(定期产品)和user(首页用户)数据。
因为有时候产品较少会采用抢购的方式,比如每天10点,这样在每天10点的时候数据会更新很快,我们必须要增加爬取的频次,以防丢失数据。所以针对预售产品即buyStartTime大于当前时间,我们要记录下,并设定计时器,当开售时,调整爬取频次为1次/秒,见setPreId方法。
如果没有正在售卖的产品,即pageUrls为空,我们将爬取的频次设置为最大32s。
requestData函数的这部分代码主要记录下是否有新产品,如果有的话,新建一个对象,记录产品信息,push到prod数组里。prod.json数据结构如下:
[{
"productName": "立马聚财-12月期HLB01230901",
"financeTotalAmount": 1000000,
"productId": "201801151830PD84123120",
"yearReturnRate": 6.4,
"investementDays": 364,
"interestStartTime": "2018年01月23日",
"interestEndTime": "2019年01月22日",
"getDataTime": 1516118401299,
"alreadyBuyAmount": 875000,
"records": [
{
"username": "刘**",
"buyTime": 1516117093472,
"buyAmount": 30000,
"uniqueId": "刘**151611709347230,000元"
},
{
"username": "刘**",
"buyTime": 1516116780799,
"buyAmount": 50000,
"uniqueId": "刘**151611678079950,000元"
}]
}]是一个对象数组,每个对象表示一个新产品,records属性记录着售卖信息。
3. 产品详情页的爬取
我们再看下getDetailData的代码:
function getDetailData(){
// 请求用户信息接口,来判断登录是否还有效,在产品详情页判断麻烦还要造成五次登录请求
superagent
.post('https://www.lmlc.com/s/web/m/user_info')
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let retcode = JSON.parse(pres.text).retcode;
if(retcode === 410){
handleErr('登陆cookie已失效,尝试重新登陆...');
getCookie();
return;
}
var reptileLink = function(url,callback){
// 如果爬取页面有限制爬取次数,这里可设置延迟
console.log( '正在爬取产品详情页面:' + url);
superagent
.get(url)
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var $ = cheerio.load(pres.text);
var records = [];
var $table = $('.buy-records table');
if(!$table.length){
$table = $('.tabcontent table');
}
var $tr = $table.find('tr').slice(1);
$tr.each(function(){
records.push({
username: $('td', $(this)).eq(0).text(),
buyTime: parseInt($('td', $(this)).eq(1).attr('data-time').replace(/,/g, '')),
buyAmount: parseFloat($('td', $(this)).eq(2).text().replace(/,/g, '')),
uniqueId: $('td', $(this)).eq(0).text() + $('td', $(this)).eq(1).attr('data-time').replace(/,/g, '') + $('td', $(this)).eq(2).text()
})
});
callback(null, {
productId: url.split('?id=')[1],
records: records
});
});
};
async.mapLimit(pageUrls, 10 ,function (url, callback) {
reptileLink(url, callback);
}, function (err,result) {
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log(`所有产品详情页爬取完毕,时间:${time}`.info);
let oldRecord = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let counts = [];
for(let i=0,len=result.length; i<len; i++){
for(let j=0,len2=oldRecord.length; j<len2; j++){
if(result[i].productId === oldRecord[j].productId){
let count = 0;
let newRecords = [];
for(let k=0,len3=result[i].records.length; k<len3; k++){
let isNewRec = true;
for(let m=0,len4=oldRecord[j].records.length; m<len4; m++){
if(result[i].records[k].uniqueId === oldRecord[j].records[m].uniqueId){
isNewRec = false;
}
}
if(isNewRec){
count++;
newRecords.push(result[i].records[k]);
}
}
oldRecord[j].records = oldRecord[j].records.concat(newRecords);
counts.push(count);
}
}
}
let oldDelay = delay;
delay = getNewDelay(delay, counts);
function getNewDelay(delay, counts){
let nowDate = (new Date()).toLocaleDateString();
let time1 = Date.parse(nowDate + ' 00:00:00');
let time2 = +new Date();
// 根据这次更新情况,来动态设置爬取频次
let maxNum = Math.max(...counts);
if(maxNum >=0 && maxNum <= 2){
delay = delay + 1000;
}
if(maxNum >=8 && maxNum <= 10){
delay = delay/2;
}
// 每天0点,prod数据清空,排除这个情况
if(maxNum == 10 && (time2 - time1 >= 60*1000)){
handleErr('部分数据可能丢失!');
}
if(delay <= 1000){
delay = 1000;
}
if(delay >= 32*1000){
delay = 32*1000;
}
return delay
}
if(oldDelay != delay){
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldRecord));
})
});
}我们先去请求用户信息接口,来判断登录是否还有效,因为在产品详情页判断麻烦还要造成五次登录请求。带cookie请求很简单,在post后面set下我们之前得到的cookie即可:.set('Cookie', cookie)。如果后台返回的retcode为410表示登录的cookie已失效,需要重新执行getCookie()。这样就能保证爬虫一直在登录状态。
async的mapLimit方法,会将pageUrls进行并发请求,一次并发量为10。对于每个pageUrl会执行reptileLink方法。等所有的异步执行完毕后,再执行回调函数。回调函数的result参数是每个reptileLink函数返回数据组成的数组。
reptileLink函数是获取产品详情页的投资记录列表信息,uniqueId是由已知的username、buyTime、buyAmount参数组成的字符串,用来排重的。
async的回调主要是将最新的投资记录信息写入对应的产品对象里,同时生成了counts数组。counts数组是每个产品这次爬取新增的售卖记录个数组成的数组,和delay一起传入getNewDelay函数。getNewDelay动态调节爬取频次,counts是调节delay的唯一依据。delay过大可能产生数据丢失,过小会增加服务器负担,可能会被管理员封ip。这里设置delay最大值为32,最小值为1。
4. 首页用户ajax爬取
先上代码:
function requestData1() {
superagent.get(ajaxUrl1)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let newData = JSON.parse(pres.text).data;
let formatNewData = formatData1(newData);
// 在这里清空数据,避免一个文件被同时写入
if(clearUser){
fs.writeFileSync('data/user.json', '');
clearUser = false;
}
let data = fs.readFileSync('data/user.json', 'utf-8');
if(!data){
fs.writeFileSync('data/user.json', JSON.stringify(formatNewData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}else{
let oldData = JSON.parse(data);
let addData = [];
// 排重算法,如果uniqueId不一样那肯定是新生成的,否则看时间差如果是0(三分钟内请求多次)或者三分钟则是旧数据
for(let i=0, len=formatNewData.length; i<len; i++){
let matchArr = [];
for(let len2=oldData.length, j=Math.max(0,len2 - 20); j<len2; j++){
if(formatNewData[i].uniqueId === oldData[j].uniqueId){
matchArr.push(j);
}
}
if(matchArr.length === 0){
addData.push(formatNewData[i]);
}else{
let isNewBuy = true;
for(let k=0, len3=matchArr.length; k<len3; k++){
let delta = formatNewData[i].time - oldData[matchArr[k]].time;
if(delta == 0 || (Math.abs(delta - 3*60*1000) < 1000)){
isNewBuy = false;
// 更新时间,这样下一次判断还是三分钟
oldData[matchArr[k]].time = formatNewData[i].time;
}
}
if(isNewBuy){
addData.push(formatNewData[i]);
}
}
}
fs.writeFileSync('data/user.json', JSON.stringify(oldData.concat(addData)));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}
});
}user.js的爬取和prod.js类似,这里主要想说一下如何排重的。user.json数据格式如下:
[
{
"payAmount": 5067.31,
"productId": "jsfund",
"productName": "立马金库",
"productType": 6,
"time": 1548489,
"username": "郑**",
"buyTime": 1516118397758,
"uniqueId": "5067.31jsfund郑**"
}, {
"payAmount": 30000,
"productId": "201801151830PD84123120",
"productName": "立马聚财-12月期HLB01230901",
"productType": 0,
"time": 1306573,
"username": "刘**",
"buyTime": 1516117199684,
"uniqueId": "30000201801151830PD84123120刘**"
}]和产品详情页类似,我们也生成一个uniqueId参数用来排除,它是payAmount、productId、username参数的拼成的字符串。如果uniqueId不一样,那肯定是一条新的记录。如果相同那一定是一条新记录吗?答案是否定的。因为这个接口数据是三分钟更新一次,而且给出的时间是相对时间,即数据更新时的时间减去购买的时间。所以每次更新后,即使是同一条记录,时间也会不一样。那如何排重呢?其实很简单,如果uniqueId一样,我们就判断这个buyTime,如果buyTime的差正好接近180s,那么几乎可以肯定是旧数据。如果同一个人正好在三分钟后购买同一个产品相同的金额那我也没辙了,哈哈。
5. 零点整合数据
每天零点我们需要整理user.json和prod.json数据,生成最终的数据。代码:
let globalTimer = setInterval(function(){
let nowTime = +new Date();
let nowStr = (new Date()).format("hh:mm:ss");
let max = nowTime;
let min = nowTime - 24*60*60*1000;
// 每天00:00分的时候写入当天的数据
if(nowStr === "00:00:00"){
// 先保存数据
let prod = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let user = JSON.parse(fs.readFileSync('data/user.json', 'utf-8'));
let lmlc = JSON.parse(JSON.stringify(prod));
// 清空缓存数据
clearProd = true;
clearUser = true;
// 不足一天的不统计
// if(nowTime - initialTime < 24*60*60*1000) return
// 筛选prod.records数据
for(let i=0, len=prod.length; i<len; i++){
let delArr1 = [];
for(let j=0, len2=prod[i].records.length; j<len2; j++){
if(prod[i].records[j].buyTime < min || prod[i].records[j].buyTime >= max){
delArr1.push(j);
}
}
sort.delArrByIndex(lmlc[i].records, delArr1);
}
// 删掉prod.records为空的数据
let delArr2 = [];
for(let i=0, len=lmlc.length; i<len; i++){
if(!lmlc[i].records.length){
delArr2.push(i);
}
}
sort.delArrByIndex(lmlc, delArr2);
// 初始化lmlc里的立马金库数据
lmlc.unshift({
"productName": "立马金库",
"financeTotalAmount": 100000000,
"productId": "jsfund",
"yearReturnRate": 4.0,
"investementDays": 1,
"interestStartTime": (new Date(min)).format("yyyy年MM月dd日"),
"interestEndTime": (new Date(max)).format("yyyy年MM月dd日"),
"getDataTime": min,
"alreadyBuyAmount": 0,
"records": []
});
// 筛选user数据
for(let i=0, len=user.length; i<len; i++){
if(user[i].productId === "jsfund" && user[i].buyTime >= min && user[i].buyTime < max){
lmlc[0].records.push({
"username": user[i].username,
"buyTime": user[i].buyTime,
"buyAmount": user[i].payAmount,
});
}
}
// 删除无用属性,按照时间排序
lmlc[0].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let i=1, len=lmlc.length; i<len; i++){
lmlc[i].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let j=0, len2=lmlc[i].records.length; j<len2; j++){
delete lmlc[i].records[j].uniqueId
}
}
// 爬取金库收益,写入前一天的数据,清空user.json和prod.json
let dateStr = (new Date(nowTime - 10*60*1000)).format("yyyyMMdd");
superagent
.get('https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var data = JSON.parse(pres.text).data;
var rate = data.result[0].yearReturnRate||4.0;
lmlc[0].yearReturnRate = rate;
fs.writeFileSync(`data/${dateStr}.json`, JSON.stringify(lmlc));
})
}
}, 1000);globalTimer是个全局定时器,每隔1s执行一次,当时间为00:00:00时,clearProd和clearUser全局参数为true,这样在下次爬取过程时会清空user.json和prod.json文件。没有同步清空是因为防止多处同时修改同一文件报错。取出user.json里的所有金库记录,获取当天金库相关信息,生成一条立马金库的prod信息并unshift进prod.json里。删除一些无用属性,排序数组最终生成带有当天时间戳的json文件,如:20180101.json。
五、前端展示
1、整体思路
前端总共就两个页面,首页和详情页,首页主要展示实时销售额、某一时间段内的销售情况、具体某天的销售情况。详情页展示某天的具体某一产品销售情况。页面有两个入口,而且比较简单,这里我们采用gulp来打包压缩构建前端工程。后台用express搭建的,匹配到路由,从data文件夹里取到数据再分析处理再返回给前端。
2、前端用到的组件介绍
Echarts
Echarts是一个绘图利器,百度公司不可多得的良心之作。能方便的绘制各种图形,官网已经更新到4.0了,功能更加强大。我们这里主要用到的是直方图。
DataTables
Datatables是一款jquery表格插件。它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能。功能非常强大,有丰富的API,大家可以去官网学习。
Datepicker
Datepicker是一款基于jquery的日期选择器,需要的功能基本都有,主要样式比较好看,比jqueryUI官网的Datepicker好看太多。
3、gulp配置
gulp配置比较简单,代码如下:
var gulp = require('gulp');
var uglify = require("gulp-uglify");
var less = require("gulp-less");
var minifyCss = require("gulp-minify-css");
var livereload = require('gulp-livereload');
var connect = require('gulp-connect');
var minimist = require('minimist');
var babel = require('gulp-babel');
var knownOptions = {
string: 'env',
default: { env: process.env.NODE_ENV || 'production' }
};
var options = minimist(process.argv.slice(2), knownOptions);
// js文件压缩
gulp.task('minify-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
// js移动文件
gulp.task('move-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less编译
gulp.task('compile-less', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less文件编译压缩
gulp.task('compile-minify-css', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(minifyCss())
.pipe(gulp.dest('dist/'));
});
// html页面自动刷新
gulp.task('html', function () {
gulp.src('views/*.html')
.pipe(connect.reload());
});
// 页面自动刷新启动
gulp.task('connect', function() {
connect.server({
livereload: true
});
});
// 监测文件的改动
gulp.task('watch', function() {
gulp.watch('src/css/*.less', ['compile-less']);
gulp.watch('src/js/*.js', ['move-js']);
gulp.watch('views/*.html', ['html']);
});
// 激活浏览器livereload友好提示
gulp.task('tip', function() {
console.log('\n<----- 请用chrome浏览器打开 http://localhost:5000 页面,并激活livereload插件 ----->\n');
});
if (options.env === 'development') {
gulp.task('default', ['move-js', 'compile-less', 'connect', 'watch', 'tip']);
}else{
gulp.task('default', ['minify-js', 'compile-minify-css']);
}开发和生产环境都是将文件打包到dist目录。不同的是:开发环境只是编译es6和less文件;生产环境会再压缩混淆。支持livereload插件,在开发环境下,文件改动会自动刷新页面。
相关推荐:
以上是NodeJS爬虫详解的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题




 nodejs怎么连接mysql数据库
Apr 21, 2024 am 06:13 AM
nodejs怎么连接mysql数据库
Apr 21, 2024 am 06:13 AM
要连接 MySQL 数据库,需要遵循以下步骤:安装 mysql2 驱动程序。使用 mysql2.createConnection() 创建连接对象,其中包含主机地址、端口、用户名、密码和数据库名称。使用 connection.query() 执行查询。最后使用 connection.end() 结束连接。
 nodejs中的全局变量有哪些
Apr 21, 2024 am 04:54 AM
nodejs中的全局变量有哪些
Apr 21, 2024 am 04:54 AM
Node.js 中存在以下全局变量:全局对象:global核心模块:process、console、require运行时环境变量:__dirname、__filename、__line、__column常量:undefined、null、NaN、Infinity、-Infinity
 nodejs安装目录里的npm与npm.cmd文件有什么区别
Apr 21, 2024 am 05:18 AM
nodejs安装目录里的npm与npm.cmd文件有什么区别
Apr 21, 2024 am 05:18 AM
Node.js 安装目录中有两个与 npm 相关的文件:npm 和 npm.cmd,区别如下:扩展名不同:npm 是可执行文件,npm.cmd 是命令窗口快捷方式。Windows 用户:npm.cmd 可以在命令提示符下使用,npm 只能从命令行运行。兼容性:npm.cmd 特定于 Windows 系统,npm 跨平台可用。使用建议:Windows 用户使用 npm.cmd,其他操作系统使用 npm。
 nodejs和java的差别大吗
Apr 21, 2024 am 06:12 AM
nodejs和java的差别大吗
Apr 21, 2024 am 06:12 AM
Node.js 和 Java 的主要差异在于设计和特性:事件驱动与线程驱动:Node.js 基于事件驱动,Java 基于线程驱动。单线程与多线程:Node.js 使用单线程事件循环,Java 使用多线程架构。运行时环境:Node.js 在 V8 JavaScript 引擎上运行,而 Java 在 JVM 上运行。语法:Node.js 使用 JavaScript 语法,而 Java 使用 Java 语法。用途:Node.js 适用于 I/O 密集型任务,而 Java 适用于大型企业应用程序。

 nodejs项目怎么部署到服务器
Apr 21, 2024 am 04:40 AM
nodejs项目怎么部署到服务器
Apr 21, 2024 am 04:40 AM
Node.js 项目的服务器部署步骤:准备部署环境:获取服务器访问权限、安装 Node.js、设置 Git 存储库。构建应用程序:使用 npm run build 生成可部署代码和依赖项。上传代码到服务器:通过 Git 或文件传输协议。安装依赖项:SSH 登录服务器并使用 npm install 安装应用程序依赖项。启动应用程序:使用 node index.js 等命令启动应用程序,或使用 pm2 等进程管理器。配置反向代理(可选):使用 Nginx 或 Apache 等反向代理路由流量到应用程
 nodejs和java选哪个
Apr 21, 2024 am 04:40 AM
nodejs和java选哪个
Apr 21, 2024 am 04:40 AM
Node.js 和 Java 在 Web 开发中各有优劣,具体选择取决于项目要求。Node.js 擅长实时应用程序、快速开发和微服务架构,而 Java 则在企业级支持、性能和安全性方面占优。
