

分布式实时日志分析解决方案 ELK 部署架构

ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats、Logstash、Elasticsearch、Kibana等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本篇文章主要给大家介绍了关于分布式实时日志分析解决方案 ELK 部署架构 ,有需要的朋友可以看一下
课程推荐→:《elasticsearch全文搜索实战》(实战视频)
一、概述
ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats、Logstash、Elasticsearch、Kibana等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本文将会介绍ELK常见的架构以及相关问题解决。
Filebeat:Filebeat是一款轻量级,占用服务资源非常少的数据收集引擎,它是ELK家族的新成员,可以代替Logstash作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到Kafka,Redis等队列。
Logstash:数据收集引擎,相较于Filebeat比较重量级,但它集成了大量的插件,支持丰富的数据源收集,对收集的数据可以过滤,分析,格式化日志格式。
Elasticsearch:分布式数据搜索引擎,基于Apache
Lucene实现,可集群,提供数据的集中式存储,分析,以及强大的数据搜索和聚合功能。Kibana:数据的可视化平台,通过该web平台可以实时的查看 Elasticsearch 中的相关数据,并提供了丰富的图表统计功能。
二、ELK常见部署架构
2.1、Logstash作为日志收集器
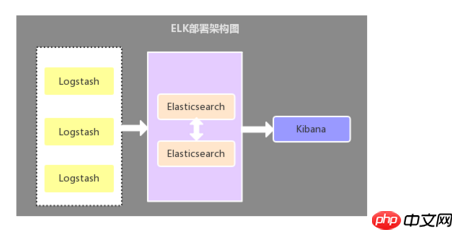
这种架构是比较原始的部署架构,在各应用服务器端分别部署一个Logstash组件,作为日志收集器,然后将Logstash收集到的数据过滤、分析、格式化处理后发送至Elasticsearch存储,最后使用Kibana进行可视化展示,这种架构不足的是:Logstash比较耗服务器资源,所以会增加应用服务器端的负载压力。
2.2、Filebeat作为日志收集器
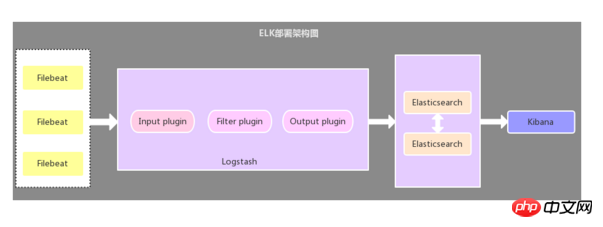
该架构与第一种架构唯一不同的是:应用端日志收集器换成了Filebeat,Filebeat轻量,占用服务器资源少,所以使用Filebeat作为应用服务器端的日志收集器,一般Filebeat会配合Logstash一起使用,这种部署方式也是目前最常用的架构。
2.3、引入缓存队列的部署架构
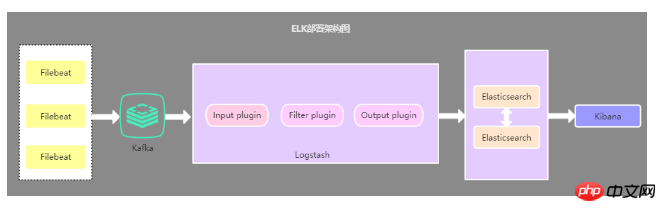
该架构在第二种架构的基础上引入了Kafka消息队列(还可以是其他消息队列),将Filebeat收集到的数据发送至Kafka,然后在通过Logstasth读取Kafka中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队列主要是解决数据安全与均衡Logstash与Elasticsearch负载压力。
2.4、以上三种架构的总结
第一种部署架构由于资源占用问题,现已很少使用,目前使用最多的是第二种部署架构,至于第三种部署架构个人觉得没有必要引入消息队列,除非有其他需求,因为在数据量较大的情况下,Filebeat 使用压力敏感协议向 Logstash 或 Elasticsearch 发送数据。如果 Logstash 正在繁忙地处理数据,它会告知 Filebeat 减慢读取速度。拥塞解决后,Filebeat 将恢复初始速度并继续发送数据。
推荐一个交流学习群:478030634 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多:

三、问题及解决方案
问题:如何实现日志的多行合并功能?
系统应用中的日志一般都是以特定格式进行打印的,属于同一条日志的数据可能分多行进行打印,那么在使用ELK收集日志的时候就需要将属于同一条日志的多行数据进行合并。
解决方案:使用Filebeat或Logstash中的multiline多行合并插件来实现
在使用multiline多行合并插件的时候需要注意,不同的ELK部署架构可能multiline的使用方式也不同,如果是本文的第一种部署架构,那么multiline需要在Logstash中配置使用,如果是第二种部署架构,那么multiline需要在Filebeat中配置使用,无需再在Logstash中配置multiline。
1、multiline在Filebeat中的配置方式:
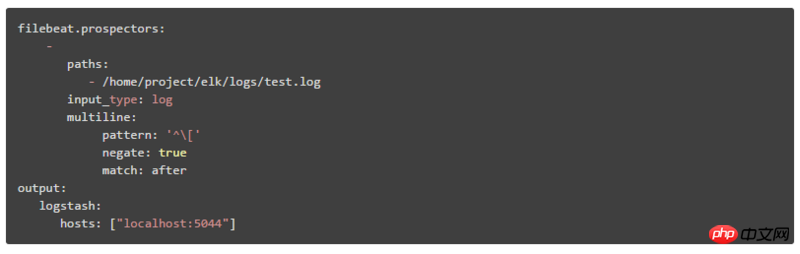
pattern:正则表达式
negate:默认为false,表示匹配pattern的行合并到上一行;true表示不匹配pattern的行合并到上一行
match:after表示合并到上一行的末尾,before表示合并到上一行的行首
如:
pattern: '['
negate: true
match: after
该配置表示将不匹配pattern模式的行合并到上一行的末尾
2、multiline在Logstash中的配置方式

(1)Logstash中配置的what属性值为previous,相当于Filebeat中的after,Logstash中配置的what属性值为next,相当于Filebeat中的before。
(2)pattern => "%{LOGLEVEL}s*]" 中的LOGLEVEL是Logstash预制的正则匹配模式,预制的还有好多常用的正则匹配模式,详细请看:https://github.com/logstash-p...
问题:如何将Kibana中显示日志的时间字段替换为日志信息中的时间?
默认情况下,我们在Kibana中查看的时间字段与日志信息中的时间不一致,因为默认的时间字段值是日志收集时的当前时间,所以需要将该字段的时间替换为日志信息中的时间。
解决方案:使用grok分词插件与date时间格式化插件来实现
在Logstash的配置文件的过滤器中配置grok分词插件与date时间格式化插件,如:

如要匹配的日志格式为:“DEBUG[DefaultBeanDefinitionDocumentReader:106] Loading bean definitions”,解析出该日志的时间字段的方式有:
① 通过引入写好的表达式文件,如表达式文件为customer_patterns,内容为:
CUSTOMER_TIME %{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME}
注:内容格式为:[自定义表达式名称] [正则表达式]
然后logstash中就可以这样引用:

② 以配置项的方式,规则为:(?<自定义表达式名称>正则匹配规则),如:

问题:如何在Kibana中通过选择不同的系统日志模块来查看数据
一般在Kibana中显示的日志数据混合了来自不同系统模块的数据,那么如何来选择或者过滤只查看指定的系统模块的日志数据?
解决方案:新增标识不同系统模块的字段或根据不同系统模块建ES索引
1、新增标识不同系统模块的字段,然后在Kibana中可以根据该字段来过滤查询不同模块的数据
这里以第二种部署架构讲解,在Filebeat中的配置内容为:
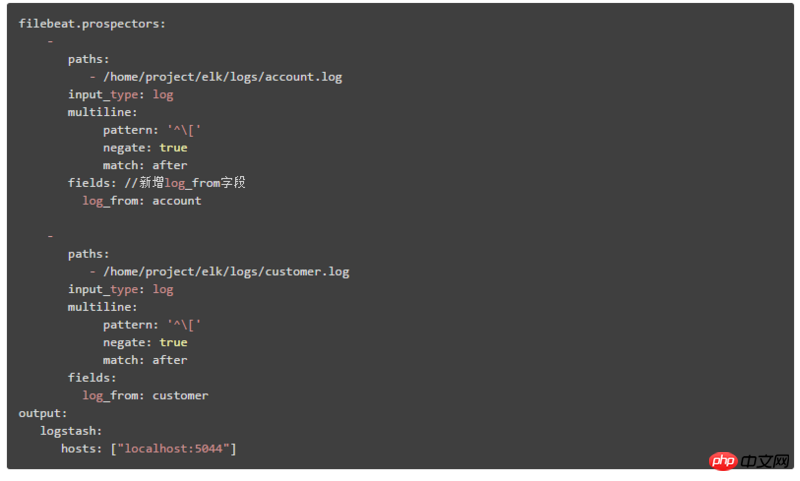
通过新增:log_from字段来标识不同的系统模块日志
2、根据不同的系统模块配置对应的ES索引,然后在Kibana中创建对应的索引模式匹配,即可在页面通过索引模式下拉框选择不同的系统模块数据。
这里以第二种部署架构讲解,分为两步:
① 在Filebeat中的配置内容为:
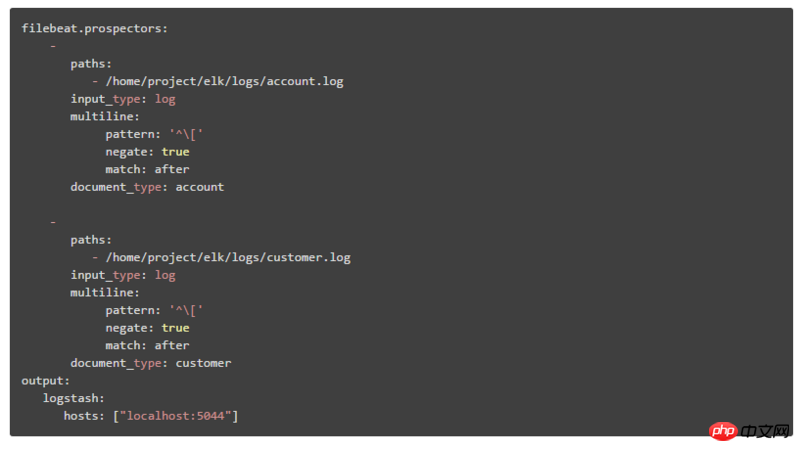
通过document_type来标识不同系统模块
② 修改Logstash中output的配置内容为:
在output中增加index属性,%{type}表示按不同的document_type值建ES索引
四、总结
本文主要介绍了ELK实时日志分析的三种部署架构,以及不同架构所能解决的问题,这三种架构中第二种部署方式是时下最流行也是最常用的部署方式,最后介绍了ELK作在日志分析中的一些问题与解决方案,说在最后,ELK不仅仅可以用来作为分布式日志数据集中式查询和管理,还可以用来作为项目应用以及服务器资源监控等场景。
以上是分布式实时日志分析解决方案 ELK 部署架构的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 针对Win11无法安装中文语言包的解决方案
Mar 09, 2024 am 09:15 AM
针对Win11无法安装中文语言包的解决方案
Mar 09, 2024 am 09:15 AM
Win11是微软推出的最新操作系统,相比于之前的版本,Win11在界面设计和用户体验上有了很大的提升。然而,一些用户反映他们在安装Win11后遇到了无法安装中文语言包的问题,这就给他们在系统中使用中文带来了困扰。本文将针对Win11无法安装中文语言包的问题提供一些解决方案,帮助用户顺利使用中文。首先,我们需要明白为什么无法安装中文语言包。一般来说,Win11
 解决Oracle字符集修改引起乱码问题的有效方案
Mar 03, 2024 am 09:57 AM
解决Oracle字符集修改引起乱码问题的有效方案
Mar 03, 2024 am 09:57 AM
标题:解决Oracle字符集修改引起乱码问题的有效方案在Oracle数据库中,当字符集被修改后,往往会因为数据中存在不兼容的字符而导致乱码问题的出现。为了解决这一问题,我们需要采取一些有效的方案来处理。本文将介绍一些解决Oracle字符集修改引起乱码问题的具体方案和代码示例。一、导出数据并重新设置字符集首先,我们可以通过使用expdp命令将数据库中的数据导出
 Oracle NVL函数常见问题及解决方案
Mar 10, 2024 am 08:42 AM
Oracle NVL函数常见问题及解决方案
Mar 10, 2024 am 08:42 AM
OracleNVL函数常见问题及解决方案Oracle数据库是广泛使用的关系型数据库系统,在数据处理过程中经常需要处理空值的情况。为了应对空值带来的问题,Oracle提供了NVL函数来处理空值。本文将介绍NVL函数的常见问题及解决方案,并提供具体的代码示例。问题一:NVL函数用法不当NVL函数的基本语法是:NVL(expr1,default_value)其
 使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
C++中机器学习算法面临的常见挑战包括内存管理、多线程、性能优化和可维护性。解决方案包括使用智能指针、现代线程库、SIMD指令和第三方库,并遵循代码风格指南和使用自动化工具。实践案例展示了如何利用Eigen库实现线性回归算法,有效地管理内存和使用高性能矩阵操作。
 MySQL安装中文乱码的常见原因及解决方案
Mar 02, 2024 am 09:00 AM
MySQL安装中文乱码的常见原因及解决方案
Mar 02, 2024 am 09:00 AM
MySQL安装中文乱码的常见原因及解决方案MySQL是一种常用的关系型数据库管理系统,但在使用过程中可能会遇到中文乱码的问题,这给开发者和系统管理员带来了困扰。中文乱码问题的出现主要是由于字符集设置不正确、数据库服务器和客户端字符集不一致等原因导致的。本文将详细介绍MySQL安装中文乱码的常见原因及解决方案,帮助大家更好地解决这个问题。一、常见原因:字符集设
 Java框架安全漏洞分析与解决方案
Jun 04, 2024 pm 06:34 PM
Java框架安全漏洞分析与解决方案
Jun 04, 2024 pm 06:34 PM
Java框架安全漏洞分析显示,XSS、SQL注入和SSRF是常见漏洞。解决方案包括:使用安全框架版本、输入验证、输出编码、防止SQL注入、使用CSRF保护、禁用不需要的功能、设置安全标头。实战案例中,ApacheStruts2OGNL注入漏洞可以通过更新框架版本和使用OGNL表达式检查工具来解决。
 黑鲨手机充电自动关机开机的原因分析及解决方案
Mar 24, 2024 pm 02:09 PM
黑鲨手机充电自动关机开机的原因分析及解决方案
Mar 24, 2024 pm 02:09 PM
黑鲨手机是一款备受年轻人喜爱的游戏手机,其优秀的性能和独特的设计吸引了众多玩家的青睐。然而,在日常使用中,有些用户反映黑鲨手机存在充电时自动关机或者连接充电器后无法启动的问题,给用户带来了困扰。本文将从原因分析以及解决方案两个方面,探讨黑鲨手机充电自动关机开机问题,帮助用户更好地解决这一困扰。一、原因分析充电器质量问题:低质量的充电器可能会导致电压不稳定,或
 PHP中文乱码的常见原因及解决方案
Mar 16, 2024 am 11:51 AM
PHP中文乱码的常见原因及解决方案
Mar 16, 2024 am 11:51 AM
PHP中文乱码的常见原因及解决方案随着互联网的发展,中文网站在我们生活中扮演着越来越重要的角色。然而,在PHP开发中,中文乱码问题仍然是一个困扰开发者的常见问题。本文将介绍PHP中文乱码的常见原因,并提供解决方案,同时也附上具体的代码示例供读者参考。一、常见原因:字符编码不一致:PHP文件编码、数据库编码、HTML页面编码等不一致可能导致中文乱码问题。数据库
