
在python写爬虫的时候,html.getcode()会遇到403禁止访问的问题,这是网站对自动化爬虫的禁止。这篇文章主要介绍了Angular2进阶之如何解决爬虫出现403问题的办法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
要解决这个问题,需要用到python的模块urllib2模块
urllib2模块是属于一个进阶的爬虫抓取模块,有非常多的方法
比方说连接url=http://blog.csdn.net/qysh123
对于这个连接就有可能出现403禁止访问的问题
解决这个问题,需要以下几步骤:
<span style="font-size:18px;">req = urllib2.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36")
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://blog.csdn.net/")</span>其中User-Agent是浏览器特有的属性,通过浏览器查看源代码就可以查看到
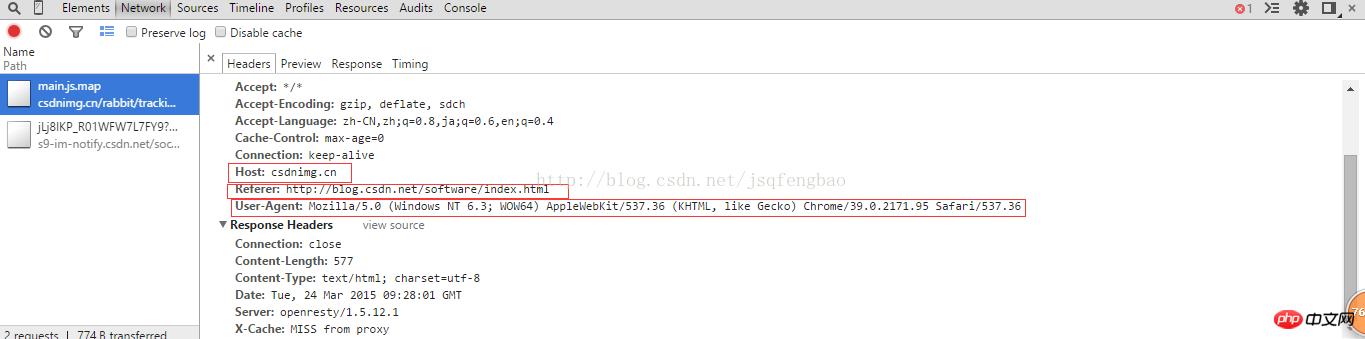
然后html=urllib2.urlopen(req)
print html.read()
就可以把网页代码全部下载下来,而没有了403禁止访问的问题。
对于以上问题,可以封装成函数,供以后调用方便使用,具体代码:
#-*-coding:utf-8-*-
import urllib2
import random
url="http://blog.csdn.net/qysh123/article/details/44564943"
my_headers=["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)"
]
def get_content(url,headers):
'''''
@获取403禁止访问的网页
'''
randdom_header=random.choice(headers)
req=urllib2.Request(url)
req.add_header("User-Agent",randdom_header)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://blog.csdn.net/")
req.add_header("GET",url)
content=urllib2.urlopen(req).read()
return content
print get_content(url,my_headers)
其中用到了random随机函数,自动获取已经写好的浏览器类型的User-Agent信息,在自定义函数中需要写出自己的Host,Referer,GET信息等,解决这几个问题,就可以顺利访问了,不再出现403访问的信息。
当然如果访问频率过快的话,有些网站还是会过滤的,解决这个需要用到代理IP的方法。。。具体的自己解决
相关推荐:
python3 HTTP Error 403:Forbidden
以上是解决爬虫出现403问题的办法的详细内容。更多信息请关注PHP中文网其他相关文章!





















