

pandas+dataframe实现行列选择与切片操作
这次给大家带来pandas+dataframe实现行列选择与切片操作,pandas+dataframe实现行列选择与切片操作的注意事项有哪些,下面就是实战案例,一起来看一下。
SQL中的select是根据列的名称来选取;Pandas则更为灵活,不但可根据列名称选取,还可以根据列所在的position(数字,在第几行第几列,注意pandas行列的position是从0开始)选取。相关函数如下:
1)loc,基于列label,可选取特定行(根据行index);
2)iloc,基于行/列的position;
3)at,根据指定行index及列label,快速定位DataFrame的元素;
4)iat,与at类似,不同的是根据position来定位的;
5)ix,为loc与iloc的混合体,既支持label也支持position;
实例
import pandas as pd
import numpy as np
df = pd.DataFrame({'total_bill': [16.99, 10.34, 23.68, 23.68, 24.59],
'tip': [1.01, 1.66, 3.50, 3.31, 3.61],
'sex': ['Female', 'Male', 'Male', 'Male', 'Female']})
# data type of columns
print df.dtypes
# indexes
print df.index
# return pandas.Index
print df.columns
# each row, return array[array]
print df.values
print dfsex object tip float64 total_bill float64 dtype: object RangeIndex(start=0, stop=5, step=1) Index([u'sex', u'tip', u'total_bill'], dtype='object') [['Female' 1.01 16.99] ['Male' 1.66 10.34] ['Male' 3.5 23.68] ['Male' 3.31 23.68] ['Female' 3.61 24.59]] sex tip total_bill 0 Female 1.01 16.99 1 Male 1.66 10.34 2 Male 3.50 23.68 3 Male 3.31 23.68 4 Female 3.61 24.59
print df.loc[1:3, ['total_bill', 'tip']] print df.loc[1:3, 'tip': 'total_bill'] print df.iloc[1:3, [1, 2]] print df.iloc[1:3, 1: 3]
total_bill tip 1 10.34 1.66 2 23.68 3.50 3 23.68 3.31 tip total_bill 1 1.66 10.34 2 3.50 23.68 3 3.31 23.68 tip total_bill 1 1.66 10.34 2 3.50 23.68 tip total_bill 1 1.66 10.34 2 3.50 23.68
错误的表示:
print df.loc[1:3, [2, 3]]#.loc仅支持列名操作
KeyError: 'None of [[2, 3]] are in the [columns]'
print df.loc[[2, 3]]#.loc可以不加列名,则是行选择
sex tip total_bill 2 Male 3.50 23.68 3 Male 3.31 23.68
print df.iloc[1:3]#.iloc可以不加第几列,则是行选择
sex tip total_bill 1 Male 1.66 10.34 2 Male 3.50 23.68
print df.iloc[1:3, 'tip': 'total_bill']
TypeError: cannot do slice indexing on <class 'pandas.indexes.base.Index'> with these indexers [tip] of <type 'str'>
print df.at[3, 'tip'] print df.iat[3, 1] print df.ix[1:3, [1, 2]] print df.ix[1:3, ['total_bill', 'tip']]
3.31 3.31 tip total_bill 1 1.66 10.34 2 3.50 23.68 3 3.31 23.68 total_bill tip 1 10.34 1.66 2 23.68 3.50 3 23.68 3.31
print df.ix[[1, 2]]#行选择
sex tip total_bill 1 Male 1.66 10.34 2 Male 3.50 23.68
print df[1: 3] print df[['total_bill', 'tip']] # print df[1:2, ['total_bill', 'tip']] # TypeError: unhashable type
sex tip total_bill 1 Male 1.66 10.34 2 Male 3.50 23.68 total_bill tip 0 16.99 1.01 1 10.34 1.66 2 23.68 3.50 3 23.68 3.31 4 24.59 3.61
print df[1:3,1:2]
TypeError: unhashable type
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
以上是pandas+dataframe实现行列选择与切片操作的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 wallpaper engine能家庭共享吗
Mar 18, 2024 pm 07:28 PM
wallpaper engine能家庭共享吗
Mar 18, 2024 pm 07:28 PM
请问Wallpaper是否支持家庭共享呢?很遗憾,不能支持哦。尽管如此,我们仍有解决方案。比如,可以用小号购买或先由大号下载好软件和壁纸,然后再更换到小号。简单启动软件是完全没问题的。wallpaperengine能家庭共享吗答:Wallpaper暂不支持家庭共享功能。1、据了解,WallpaperEngine似乎并不适合家庭共享环境。2、为了解决这个困扰,建议您考虑购买全新账号;3、或者先在主账号下载所需软件和壁纸,再切到其他账号。4、只要轻点打开软件,便无碍。5、您可以在上述网页上查看属性“
 iBatis和MyBatis:哪个更适合你?
Feb 19, 2024 pm 04:38 PM
iBatis和MyBatis:哪个更适合你?
Feb 19, 2024 pm 04:38 PM
iBatis与MyBatis:你应该选择哪个?简介:随着Java语言的快速发展,许多持久化框架也应运而生。iBatis和MyBatis是两个备受欢迎的持久化框架,它们都提供了一种简单而高效的数据访问解决方案。本文将介绍iBatis和MyBatis的特点和优势,并给出一些具体的代码示例,帮助你选择合适的框架。iBatis简介:iBatis是一个开源的持久化框架
 wallpaper engine怎么设置锁屏壁纸?wallpaper engine使用方法
Mar 13, 2024 pm 08:07 PM
wallpaper engine怎么设置锁屏壁纸?wallpaper engine使用方法
Mar 13, 2024 pm 08:07 PM
wallpaperengine是常用于设置桌面壁纸的软件,用户在wallpaperengine里可以搜索自己喜欢的图片来生成桌面壁纸,还支持将电脑中的图片添加到wallpaperengine中设置成电脑壁纸。下面就来看看wallpaperengine设置锁屏壁纸的方法吧。 wallpaperengine设置锁屏壁纸教程 1、首先进入软件,然后选择已安装,点击“配置壁纸选项”。 2、单独设置选择完壁纸后需要点击右下方的确定。 3、再去点击上方的设置选和预览。 4、接下来
 wallpaper engine看片有病毒吗
Mar 18, 2024 pm 07:28 PM
wallpaper engine看片有病毒吗
Mar 18, 2024 pm 07:28 PM
用户在使用wallpaperengine可以下载各种壁纸,还可以使用动态壁纸,有很多用户不知道wallpaperengine看片有没有病毒,只是视频文件是无法作为病毒的。wallpaperengine看片有病毒吗答:不会。1、只是视频文件是无法作为病毒的。2、只要确保从可信的来源下载视频,并保持电脑的安全防护措施,就可以避免病毒感染的风险。3、应用程序类壁纸是apk格式,apk可能会携带木马病毒。4、WallpaperEngine本身没有病毒,但是创意工坊里的一些应用程序类壁纸可能有病毒。
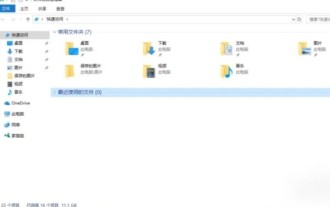 wallpaper engine的壁纸在哪个文件夹
Mar 19, 2024 am 08:16 AM
wallpaper engine的壁纸在哪个文件夹
Mar 19, 2024 am 08:16 AM
用户在使用wallpaper时可以下载各种自己喜欢的壁纸进行使用,有很多用户不知道wallpaper的壁纸在哪个文件夹,用户下载的壁纸存放在content文件夹里。wallpaper的壁纸在哪个文件夹答:content文件夹。1、打开文件资源管理器。2、点击左侧“此电脑”。3、找到“STEAM”文件夹。4、选择“steamapps”。5、点击“workshop”。6、找寻“content”文件夹。
 wallpaper engine耗电多吗
Mar 18, 2024 pm 08:30 PM
wallpaper engine耗电多吗
Mar 18, 2024 pm 08:30 PM
用户在使用wallpaperengine时可以更改自己的电脑壁纸,有很多用户不知道wallpaperengine耗电多吗,动态壁纸是会比静态壁纸更加耗电一点,但耗得不是很多。wallpaperengine耗电多吗答:不多。1、动态壁纸是会比静态壁纸更加耗电一点,但耗得不是很多。2、开启动态壁纸会增加电脑耗电量,并带走一小小部分内存占用。3、用户不需要担心动态壁纸消耗电比较严重的。
 wallpaper engine订阅记录在哪
Mar 18, 2024 pm 05:37 PM
wallpaper engine订阅记录在哪
Mar 18, 2024 pm 05:37 PM
请问怎样查看wallpaper订阅记录呢?许多用户在该软件上进行了大量的订阅,但可能不清楚如何查询这些记录。其实,您只需要在软件的浏览功能区进行操作即可。wallpaperengine订阅记录在哪答:在浏览界面。1、请先启动电脑,并进入wallpaper软件。2、找到应用程序左上方的浏览选项卡图标并点击。3、在“浏览”界面中,您将看到各类壁纸及订阅源的总览。4、在右上角的搜索框中输入您想要搜索的关键词。5、依靠搜索结果,你便能找到订阅壁纸的来源信息。6、点击对应的订阅源,即可进入其网页。7、在订
 Microsoft Edge浏览器怎么更改字体大小-Microsoft Edge浏览器更改字体大小的方法
Mar 04, 2024 pm 05:58 PM
Microsoft Edge浏览器怎么更改字体大小-Microsoft Edge浏览器更改字体大小的方法
Mar 04, 2024 pm 05:58 PM
想必大家对MicrosoftEdge浏览器并不模式,不过你们知道MicrosoftEdge浏览器怎么更改字体大小吗?下面这篇文章就讲述了MicrosoftEdge浏览器更改字体大小的方法,让我们一起去下文好好学习学习吧。首先,找到MicrosoftEdge浏览器双击打开。可以在桌面快捷键、开始菜单或任务栏找到MicrosoftEdge浏览器,并双击打开。其次,打开【设置】界面打开进入到这个浏览器界面,单击左上角【...】标识;双击【设置】,打开进入设置界面。再次,找到并打开【外观】界面鼠标滚动下
