

利用python将pdf输出为txt的实例

下面为大家分享一篇利用python将pdf输出为txt的实例讲解,具有很好的参考价值,希望对大家有所帮助。一起过来看看吧
一个礼拜前一个同学问我这个事情,由于之前在参加华为的比赛,所以赛后看了一下,据说需要用到pdfminer这个包。于是安装了一下,安装过程很简单:
sudo pip install pdfminer;
中间也没有任何的报错。至于如何调用,本人也没有很好的研究过pdfminer这个库,于是开始了百度……
官方文档:http://www.unixuser.org/~euske/python/pdfminer/index.html
完全使用python编写。 (适用于2.4或更新版本)
解析,分析,并转换成PDF文档。
PDF-1.7规范的支持。 (几乎)
中日韩语言和垂直书写脚本支持。
各种字体类型(Type1、TrueType、Type3,和CID)的支持。
基本加密(RC4)的支持。
PDF与HTML转换。
纲要(TOC)的提取。
标签内容提取。
通过分组文本块重建原始的布局。
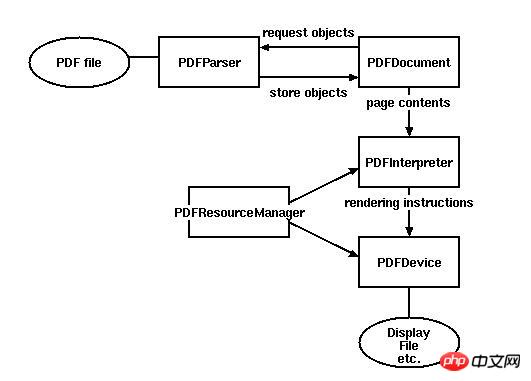
一些基本的类
PDFParser:从一个文件中获取数据
PDFDocument:保存获取的数据,和PDFParser是相互关联的
PDFPageInterpreter处理页面内容
PDFDevice将其翻译成你需要的格式
PDFResourceManager用于存储共享资源,如字体或图像。
简单的实现
读取test.pdf输出为output.txt:
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')相关推荐:
以上是利用python将pdf输出为txt的实例的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Python:游戏,Guis等
Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等
Apr 13, 2025 am 12:14 AM
Python在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。
 PHP和Python:比较两种流行的编程语言
Apr 14, 2025 am 12:13 AM
PHP和Python:比较两种流行的编程语言
Apr 14, 2025 am 12:13 AM
PHP和Python各有优势,选择依据项目需求。1.PHP适合web开发,尤其快速开发和维护网站。2.Python适用于数据科学、机器学习和人工智能,语法简洁,适合初学者。
 debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系统中的readdir函数是用于读取目录内容的系统调用,常用于C语言编程。本文将介绍如何将readdir与其他工具集成,以增强其功能。方法一:C语言程序与管道结合首先,编写一个C程序调用readdir函数并输出结果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Nginx SSL证书更新Debian教程
Apr 13, 2025 am 07:21 AM
Nginx SSL证书更新Debian教程
Apr 13, 2025 am 07:21 AM
本文将指导您如何在Debian系统上更新NginxSSL证书。第一步:安装Certbot首先,请确保您的系统已安装certbot和python3-certbot-nginx包。若未安装,请执行以下命令:sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx第二步:获取并配置证书使用certbot命令获取Let'sEncrypt证书并配置Nginx:sudocertbot--nginx按照提示选
 Debian OpenSSL如何配置HTTPS服务器
Apr 13, 2025 am 11:03 AM
Debian OpenSSL如何配置HTTPS服务器
Apr 13, 2025 am 11:03 AM
在Debian系统上配置HTTPS服务器涉及几个步骤,包括安装必要的软件、生成SSL证书、配置Web服务器(如Apache或Nginx)以使用SSL证书。以下是一个基本的指南,假设你使用的是ApacheWeb服务器。1.安装必要的软件首先,确保你的系统是最新的,并安装Apache和OpenSSL:sudoaptupdatesudoaptupgradesudoaptinsta
 Debian上GitLab的插件开发指南
Apr 13, 2025 am 08:24 AM
Debian上GitLab的插件开发指南
Apr 13, 2025 am 08:24 AM
在Debian上开发GitLab插件需要一些特定的步骤和知识。以下是一个基本的指南,帮助你开始这个过程。安装GitLab首先,你需要在Debian系统上安装GitLab。可以参考GitLab的官方安装手册。获取API访问令牌在进行API集成之前,首先需要获取GitLab的API访问令牌。打开GitLab仪表盘,在用户设置中找到“AccessTokens”选项,生成一个新的访问令牌。将生成的
 apache属于什么服务
Apr 13, 2025 pm 12:06 PM
apache属于什么服务
Apr 13, 2025 pm 12:06 PM
Apache是互联网幕后的英雄,不仅是Web服务器,更是一个支持巨大流量、提供动态内容的强大平台。它通过模块化设计提供极高的灵活性,可根据需要扩展各种功能。然而,模块化也带来配置和性能方面的挑战,需要谨慎管理。Apache适合需要高度可定制、满足复杂需求的服务器场景。
