

用TensorFlow实现戴明回归算法的示例

这篇文章主要介绍了关于用TensorFlow实现戴明回归算法的示例,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下
如果最小二乘线性回归算法最小化到回归直线的竖直距离(即,平行于y轴方向),则戴明回归最小化到回归直线的总距离(即,垂直于回归直线)。其最小化x值和y值两个方向的误差,具体的对比图如下图。
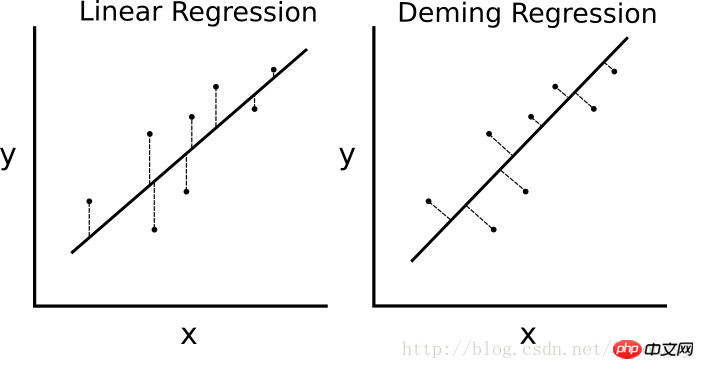
线性回归算法和戴明回归算法的区别。左边的线性回归最小化到回归直线的竖直距离;右边的戴明回归最小化到回归直线的总距离。
线性回归算法的损失函数最小化竖直距离;而这里需要最小化总距离。给定直线的斜率和截距,则求解一个点到直线的垂直距离有已知的几何公式。代入几何公式并使TensorFlow最小化距离。
损失函数是由分子和分母组成的几何公式。给定直线y=mx+b,点(x0,y0),则求两者间的距离的公式为:
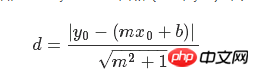
# 戴明回归
#----------------------------------
#
# This function shows how to use TensorFlow to
# solve linear Deming regression.
# y = Ax + b
#
# We will use the iris data, specifically:
# y = Sepal Length
# x = Petal Width
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn import datasets
from tensorflow.python.framework import ops
ops.reset_default_graph()
# Create graph
sess = tf.Session()
# Load the data
# iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)]
iris = datasets.load_iris()
x_vals = np.array([x[3] for x in iris.data])
y_vals = np.array([y[0] for y in iris.data])
# Declare batch size
batch_size = 50
# Initialize placeholders
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# Create variables for linear regression
A = tf.Variable(tf.random_normal(shape=[1,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Declare model operations
model_output = tf.add(tf.matmul(x_data, A), b)
# Declare Demming loss function
demming_numerator = tf.abs(tf.subtract(y_target, tf.add(tf.matmul(x_data, A), b)))
demming_denominator = tf.sqrt(tf.add(tf.square(A),1))
loss = tf.reduce_mean(tf.truep(demming_numerator, demming_denominator))
# Declare optimizer
my_opt = tf.train.GradientDescentOptimizer(0.1)
train_step = my_opt.minimize(loss)
# Initialize variables
init = tf.global_variables_initializer()
sess.run(init)
# Training loop
loss_vec = []
for i in range(250):
rand_index = np.random.choice(len(x_vals), size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec.append(temp_loss)
if (i+1)%50==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b)))
print('Loss = ' + str(temp_loss))
# Get the optimal coefficients
[slope] = sess.run(A)
[y_intercept] = sess.run(b)
# Get best fit line
best_fit = []
for i in x_vals:
best_fit.append(slope*i+y_intercept)
# Plot the result
plt.plot(x_vals, y_vals, 'o', label='Data Points')
plt.plot(x_vals, best_fit, 'r-', label='Best fit line', linewidth=3)
plt.legend(loc='upper left')
plt.title('Sepal Length vs Pedal Width')
plt.xlabel('Pedal Width')
plt.ylabel('Sepal Length')
plt.show()
# Plot loss over time
plt.plot(loss_vec, 'k-')
plt.title('L2 Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('L2 Loss')
plt.show()结果:
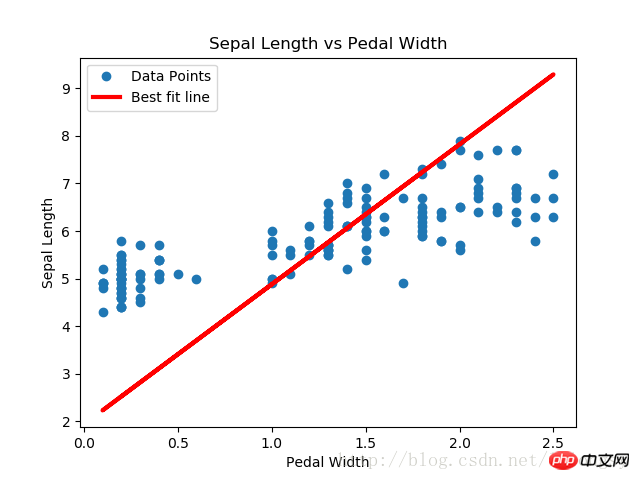
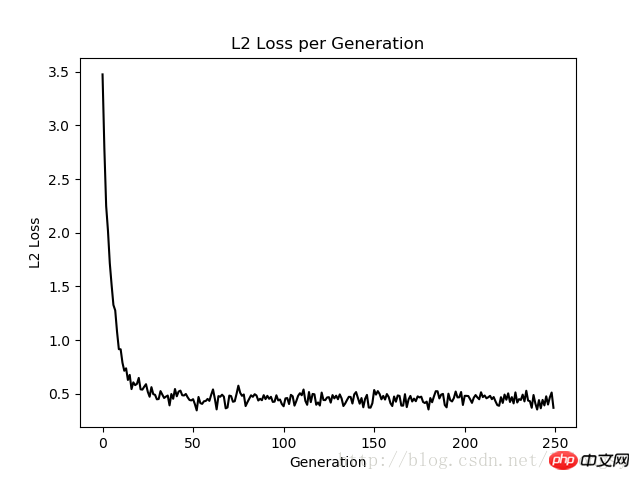
本文的戴明回归算法与线性回归算法得到的结果基本一致。两者之间的关键不同点在于预测值与数据点间的损失函数度量:线性回归算法的损失函数是竖直距离损失;而戴明回归算法是垂直距离损失(到x轴和y轴的总距离损失)。
注意,这里戴明回归算法的实现类型是总体回归(总的最小二乘法误差)。总体回归算法是假设x值和y值的误差是相似的。我们也可以根据不同的理念使用不同的误差来扩展x轴和y轴的距离计算。
相关推荐:
以上是用TensorFlow实现戴明回归算法的示例的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
C++中机器学习算法面临的常见挑战包括内存管理、多线程、性能优化和可维护性。解决方案包括使用智能指针、现代线程库、SIMD指令和第三方库,并遵循代码风格指南和使用自动化工具。实践案例展示了如何利用Eigen库实现线性回归算法,有效地管理内存和使用高性能矩阵操作。
 探究C++sort函数的底层原理与算法选择
Apr 02, 2024 pm 05:36 PM
探究C++sort函数的底层原理与算法选择
Apr 02, 2024 pm 05:36 PM
C++sort函数底层采用归并排序,其复杂度为O(nlogn),并提供不同的排序算法选择,包括快速排序、堆排序和稳定排序。
 Go语言的缩进规范及示例
Mar 22, 2024 pm 09:33 PM
Go语言的缩进规范及示例
Mar 22, 2024 pm 09:33 PM
Go语言的缩进规范及示例Go语言是一种由Google开发的编程语言,它以简洁、清晰的语法着称,其中缩进规范在代码的可读性和美观性方面起着至关重要的作用。本文将介绍Go语言的缩进规范,并通过具体的代码示例进行详细说明。缩进规范在Go语言中,缩进使用制表符(tab)而非空格。每级缩进为一个制表符,通常设置为4个空格的宽度。这样的规范统一了代码风格,使得团队合作编
 改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
01前景概要目前,难以在检测效率和检测结果之间取得适当的平衡。我们就研究出了一种用于高分辨率光学遥感图像中目标检测的增强YOLOv5算法,利用多层特征金字塔、多检测头策略和混合注意力模块来提高光学遥感图像的目标检测网络的效果。根据SIMD数据集,新算法的mAP比YOLOv5好2.2%,比YOLOX好8.48%,在检测结果和速度之间实现了更好的平衡。02背景&动机随着远感技术的快速发展,高分辨率光学远感图像已被用于描述地球表面的许多物体,包括飞机、汽车、建筑物等。目标检测在远感图像的解释中
 人工智能可以预测犯罪吗?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智能可以预测犯罪吗?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智能(AI)与执法领域的融合为犯罪预防和侦查开辟了新的可能性。人工智能的预测能力被广泛应用于CrimeGPT(犯罪预测技术)等系统,用于预测犯罪活动。本文探讨了人工智能在犯罪预测领域的潜力、目前的应用情况、所面临的挑战以及相关技术可能带来的道德影响。人工智能和犯罪预测:基础知识CrimeGPT利用机器学习算法来分析大量数据集,识别可以预测犯罪可能发生的地点和时间的模式。这些数据集包括历史犯罪统计数据、人口统计信息、经济指标、天气模式等。通过识别人类分析师可能忽视的趋势,人工智能可以为执法机构
 Oracle DECODE函数详解及用法示例
Mar 08, 2024 pm 03:51 PM
Oracle DECODE函数详解及用法示例
Mar 08, 2024 pm 03:51 PM
Oracle中的DECODE函数是一种条件表达式,常用于在查询语句中根据不同的条件返回不同的结果。本文将详细介绍DECODE函数的语法、用法和示例代码。一、DECODE函数语法DECODE(expr,search1,result1[,search2,result2,...,default])expr:要进行比较的表达式或字段。search1,
 算法在 58 画像平台建设中的应用
May 09, 2024 am 09:01 AM
算法在 58 画像平台建设中的应用
May 09, 2024 am 09:01 AM
一、58画像平台建设背景首先和大家分享下58画像平台的建设背景。1.传统的画像平台传统的思路已经不够,建设用户画像平台依赖数据仓库建模能力,整合多业务线数据,构建准确的用户画像;还需要数据挖掘,理解用户行为、兴趣和需求,提供算法侧的能力;最后,还需要具备数据平台能力,高效存储、查询和共享用户画像数据,提供画像服务。业务自建画像平台和中台类型画像平台主要区别在于,业务自建画像平台服务单条业务线,按需定制;中台平台服务多条业务线,建模复杂,提供更为通用的能力。2.58中台画像建设的背景58的用户画像
