

网易云音乐评论爬取
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
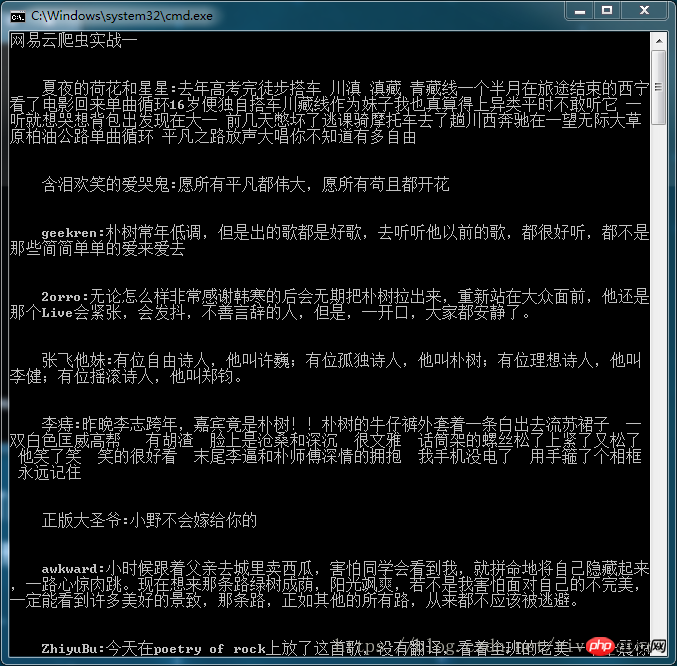
print('\n\n'+c.replace('\n',''))
总结:
1、第一行的“# coding=gbk”表示的是可以在文本编辑器中输入文字字符串。
2、"id = music_url.split('=')[1]"中split()函数表示对元素进行分组,例中为“https://music.163.com/#/song?id=”,“28815250”
3、由requests模块获取的HTML文本需要用json.loads()方法进行转化为Python可读的文本,否则会报错。在jupyter notebook中则不会出现这种情况。
4、replace()函数可以去除字符串中的元素,例中将换行符变为空。
最终显示结果如下图:
本文介绍了网易云音乐评论爬取 的相关内容,请关注php中文网。
相关推荐:
以上是网易云音乐评论爬取的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 利用纽约时报API进行元数据爬取
Sep 02, 2023 pm 10:13 PM
利用纽约时报API进行元数据爬取
Sep 02, 2023 pm 10:13 PM
简介上周,我写了一篇关于抓取网页以收集元数据的介绍,并提到不可能抓取《纽约时报》网站。《纽约时报》付费墙会阻止您收集基本元数据的尝试。但有一种方法可以使用纽约时报API来解决这个问题。最近我开始在Yii平台上构建一个社区网站,我将在以后的教程中发布该网站。我希望能够轻松添加与网站内容相关的链接。虽然人们可以轻松地将URL粘贴到表单中,但提供标题和来源信息却非常耗时。因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加《纽约时报》链接时利用《纽约时报》API来收集头条新闻。请记住,我参与了
 如何在PHP项目中通过调用API接口来实现数据的爬取和处理?
Sep 05, 2023 am 08:41 AM
如何在PHP项目中通过调用API接口来实现数据的爬取和处理?
Sep 05, 2023 am 08:41 AM
如何在PHP项目中通过调用API接口来实现数据的爬取和处理?一、介绍在PHP项目中,我们经常需要爬取其他网站的数据,并对这些数据进行处理。而许多网站提供了API接口,我们可以通过调用这些接口来获取数据。本文将介绍如何使用PHP来调用API接口,实现数据的爬取和处理。二、获取API接口的URL和参数在开始之前,我们需要先获取目标API接口的URL以及所需的
 Vue开发经验总结:优化SEO和搜索引擎爬取的技巧
Nov 22, 2023 am 10:56 AM
Vue开发经验总结:优化SEO和搜索引擎爬取的技巧
Nov 22, 2023 am 10:56 AM
Vue开发经验总结:优化SEO和搜索引擎爬取的技巧随着互联网的快速发展,网站的SEO(SearchEngineOptimization,搜索引擎优化)变得越来越重要。对于使用Vue进行开发的网站来说,优化SEO和搜索引擎爬取是至关重要的。本文将总结一些Vue开发经验,分享一些优化SEO和搜索引擎爬取的技巧。使用预渲染(Prerendering)技术Vue
 如何使用Scrapy爬取豆瓣图书及其评分和评论?
Jun 22, 2023 am 10:21 AM
如何使用Scrapy爬取豆瓣图书及其评分和评论?
Jun 22, 2023 am 10:21 AM
随着互联网的发展,人们越来越依赖于网络来获取信息。而对于图书爱好者而言,豆瓣图书已经成为了一个不可或缺的平台。并且,豆瓣图书也提供了丰富的图书评分和评论,使读者能够更加全面地了解一本图书。但是,手动获取这些信息无异于大海捞针,这时候,我们可以借助Scrapy工具进行数据爬取。Scrapy是一个基于Python的开源网络爬虫框架,它可以帮助我们高效地
 Scrapy实战:爬取百度新闻数据
Jun 23, 2023 am 08:50 AM
Scrapy实战:爬取百度新闻数据
Jun 23, 2023 am 08:50 AM
Scrapy实战:爬取百度新闻数据随着互联网的发展,人们获取信息的主要途径已经从传统媒体向互联网转移,人们越来越依赖网络获取新闻信息。而对于研究者或分析师来说,需要大量的数据来进行分析和研究。因此,本文将介绍如何用Scrapy爬取百度新闻数据。Scrapy是一个开源的Python爬虫框架,它可以快速高效地爬取网站数据。Scrapy提供了强大的网页解析和抓取功
 如何使用PHP Goutte类库进行网页爬取与数据提取?
Aug 09, 2023 pm 02:16 PM
如何使用PHP Goutte类库进行网页爬取与数据提取?
Aug 09, 2023 pm 02:16 PM
如何使用PHPGoutte类库进行网页爬取与数据提取?概述:在日常的开发过程中,我们经常需要从互联网上获取各种数据,例如电影排名、天气预报等等。而网页爬取则是获取这些数据的常用方法之一。在PHP开发中,我们可以利用Goutte类库来实现网页爬取与数据提取的功能。本文将介绍如何使用PHPGoutte类库进行网页爬取与数据提取,并附上代码示例。什么是Gout
 Scrapy实战:爬取豆瓣电影数据和评分热度排名
Jun 22, 2023 pm 01:49 PM
Scrapy实战:爬取豆瓣电影数据和评分热度排名
Jun 22, 2023 pm 01:49 PM
Scrapy是一个开源的Python框架,用于快速高效地爬取数据。在本文中,我们将使用Scrapy爬取豆瓣电影的数据和评分热度排名。准备工作首先,我们需要安装Scrapy。您可以在命令行中输入以下命令来安装Scrapy:pipinstallscrapy接下来,我们将创建一个Scrapy项目。在命令行中,输入以下命令:scrapystartproject
 怎样用Scrapy爬取酷狗音乐的歌曲?
Jun 22, 2023 pm 10:59 PM
怎样用Scrapy爬取酷狗音乐的歌曲?
Jun 22, 2023 pm 10:59 PM
随着互联网的发展,网络上的信息量越来越大,人们需要爬取不同网站上的信息来进行各种分析和挖掘。而Scrapy是一个功能完备的Python爬虫框架,它可以自动化爬取网站数据,并以结构化的形式输出。酷狗音乐是广受欢迎的在线音乐平台之一,下面我将介绍怎样使用Scrapy来完成对酷狗音乐的歌曲信息爬取。1.安装ScrapyScrapy是基于Python语言的框架,所
