

node如何爬取网页中的图片(附代码)

本篇文章给大家带来的内容是关于node如何爬取网页中的图片(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
目录
安装node,并下载依赖
搭建服务
请求我们要爬取的页面,返回json
安装node
我们开始安装node,可以去node官网下载https://nodejs.org/zh-cn/,下载完成后运行node使用,
node -v
安装成功后会出现你所安装的版本号。
接下来我们使用node, 打印出hello world,新建一个名为index.js文件输入
console.log('hello world')
运行这个文件
node index.js
就会在控制面板上输出hello world
搭建服务器
新建一个·名为node的文件夹。
首先你需要下载express依赖
npm install express
再新建一个名为demo.js的文件 目录结构如图:

在demo.js引入下载的express
const express = require('express');
const app = express();
app.get('/index', function(req, res) {
res.end('111')
})
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})运行node demo.js简单的服务就搭起来了,如图:
请求我们要爬取的页面
请求我们要爬取的页面
npm install superagent npm install superagent-charset npm install cheerio
superagent 是用来发起请求的,是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于nodejs环境下.,也可以使用http发起请求
superagent-charset防止爬取下来的数据乱码,更改字符格式
cheerio为服务器特别定制的,快速、灵活、实施的jQuery核心实现.。 安装完依赖就可以引入了
var superagent = require('superagent'); var charset = require('superagent-charset'); charset(superagent); const cheerio = require('cheerio');
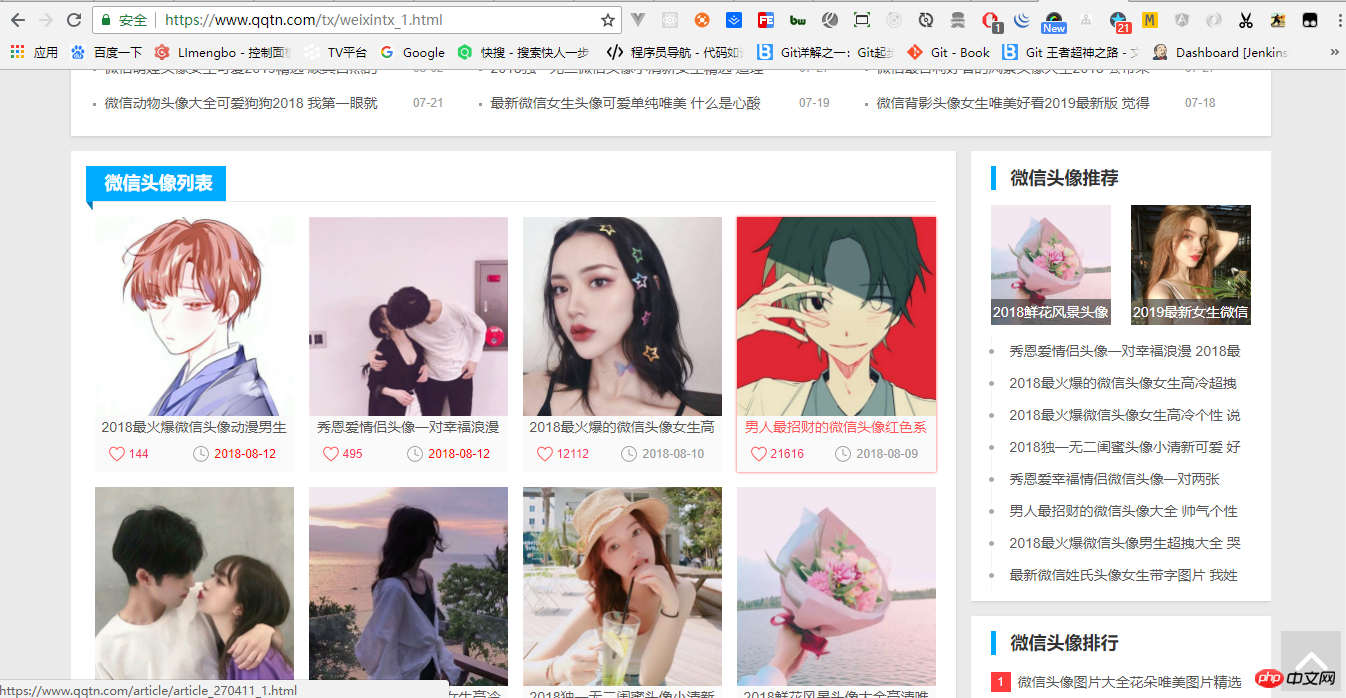
引入之后就请求我们的地址,https://www.qqtn.com/tx/weixintx_1.html,如图:
声明地址变量:
const baseUrl = 'https://www.qqtn.com/'
这些设置完之后就是发请求了,接下来请看完整代码demo.js
var superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
var express = require('express');
var baseUrl = 'https://www.qqtn.com/'; //输入任何网址都可以
const cheerio = require('cheerio');
var app = express();
app.get('/index', function(req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//类型
var type = req.query.type;
//页码
var page = req.query.page;
type = type || 'weixin';
page = page || '1';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.end(function(err, sres) {
var items = [];
if (err) {
console.log('ERR: ' + err);
res.json({ code: 400, msg: err, sets: items });
return;
}
var $ = cheerio.load(sres.text);
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
res.json({ code: 200, msg: "", data: items });
});
});
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})运行demo.js就会返回我们拿到的数据,如图:
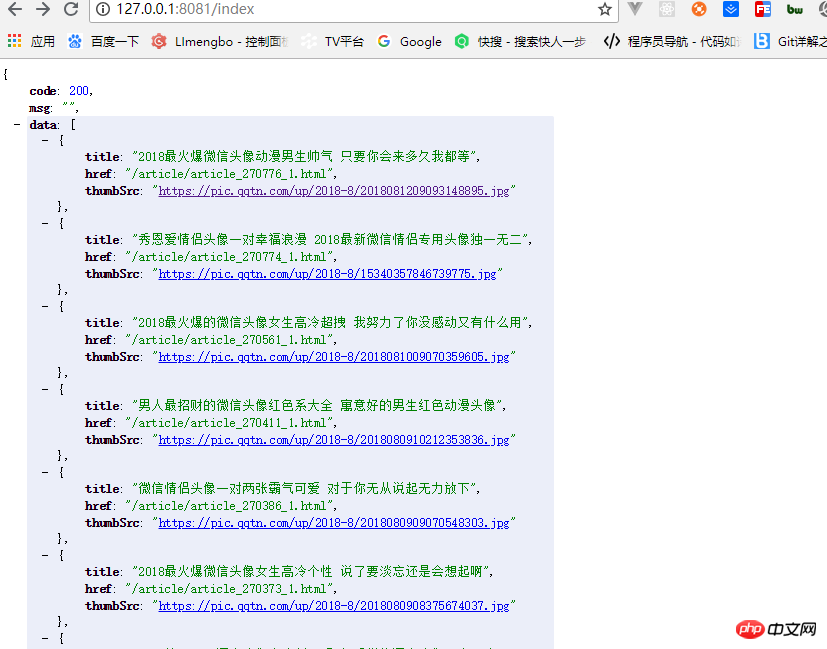
一个简单的node爬虫就完成了。
相关推荐:
node爬虫之gbk网页中文乱码解决方案_html/css_WEB-ITnose
以上是node如何爬取网页中的图片(附代码)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题




 谁得到更多的Python或JavaScript?
Apr 04, 2025 am 12:09 AM
谁得到更多的Python或JavaScript?
Apr 04, 2025 am 12:09 AM
Python和JavaScript开发者的薪资没有绝对的高低,具体取决于技能和行业需求。1.Python在数据科学和机器学习领域可能薪资更高。2.JavaScript在前端和全栈开发中需求大,薪资也可观。3.影响因素包括经验、地理位置、公司规模和特定技能。
 如何使用JavaScript将具有相同ID的数组元素合并到一个对象中?
Apr 04, 2025 pm 05:09 PM
如何使用JavaScript将具有相同ID的数组元素合并到一个对象中?
Apr 04, 2025 pm 05:09 PM
如何在JavaScript中将具有相同ID的数组元素合并到一个对象中?在处理数据时,我们常常会遇到需要将具有相同ID�...
 神秘的JavaScript:它的作用以及为什么重要
Apr 09, 2025 am 12:07 AM
神秘的JavaScript:它的作用以及为什么重要
Apr 09, 2025 am 12:07 AM
JavaScript是现代Web开发的基石,它的主要功能包括事件驱动编程、动态内容生成和异步编程。1)事件驱动编程允许网页根据用户操作动态变化。2)动态内容生成使得页面内容可以根据条件调整。3)异步编程确保用户界面不被阻塞。JavaScript广泛应用于网页交互、单页面应用和服务器端开发,极大地提升了用户体验和跨平台开发的灵活性。
 console.log输出结果差异:两次调用为何不同?
Apr 04, 2025 pm 05:12 PM
console.log输出结果差异:两次调用为何不同?
Apr 04, 2025 pm 05:12 PM
深入探讨console.log输出差异的根源本文将分析一段代码中console.log函数输出结果的差异,并解释其背后的原因。�...
 初学者的打字稿,第2部分:基本数据类型
Mar 19, 2025 am 09:10 AM
初学者的打字稿,第2部分:基本数据类型
Mar 19, 2025 am 09:10 AM
掌握了入门级TypeScript教程后,您应该能够在支持TypeScript的IDE中编写自己的代码,并将其编译成JavaScript。本教程将深入探讨TypeScript中各种数据类型。 JavaScript拥有七种数据类型:Null、Undefined、Boolean、Number、String、Symbol(ES6引入)和Object。TypeScript在此基础上定义了更多类型,本教程将详细介绍所有这些类型。 Null数据类型 与JavaScript一样,TypeScript中的null
 如何实现视差滚动和元素动画效果,像资生堂官网那样?
或者:
怎样才能像资生堂官网一样,实现页面滚动伴随的动画效果?
Apr 04, 2025 pm 05:36 PM
如何实现视差滚动和元素动画效果,像资生堂官网那样?
或者:
怎样才能像资生堂官网一样,实现页面滚动伴随的动画效果?
Apr 04, 2025 pm 05:36 PM
实现视差滚动和元素动画效果的探讨本文将探讨如何实现类似资生堂官网(https://www.shiseido.co.jp/sb/wonderland/)中�...
 PowerPoint可以运行JavaScript吗?
Apr 01, 2025 pm 05:17 PM
PowerPoint可以运行JavaScript吗?
Apr 01, 2025 pm 05:17 PM
在PowerPoint中可以运行JavaScript,通过VBA调用外部JavaScript文件或嵌入HTML文件来实现。1.使用VBA调用JavaScript文件,需启用宏并具备VBA编程知识。2.嵌入包含JavaScript的HTML文件,简单易行但受安全限制。优点包括扩展功能和灵活性,劣势涉及安全性、兼容性和复杂性,实际应用需注意安全性、兼容性、性能和用户体验。
