

分布式的系统核心日志的详细介绍(图文)

本篇文章给大家带来的内容是关于分布式的系统核心日志的详细介绍(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
什么是日志?
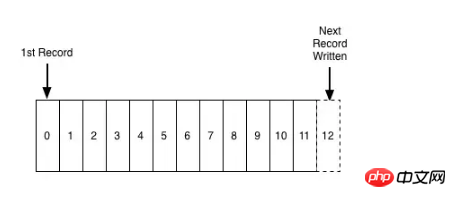
日志就是按照时间顺序追加的、完全有序的记录序列,其实就是一种特殊的文件格式,文件是一个字节数组,而这里日志是一个记录数据,只是相对于文件来说,这里每条记录都是按照时间的相对顺序排列的,可以说日志是最简单的一种存储模型,读取一般都是从左到右,例如消息队列,一般是线性写入log文件,消费者顺序从offset开始读取。
由于日志本身固有的特性,记录从左向右开始顺序插入,也就意味着左边的记录相较于右边的记录“更老”, 也就是说我们可以不用依赖于系统时钟,这个特性对于分布式系统来说相当重要。
日志的应用
日志在数据库中的应用
日志是什么时候出现已经无从得知,可能是概念上来讲太简单。在数据库领域中日志更多的是用于在系统crash的时候同步数据以及索引等,例如MySQL中的redo log,redo log是一种基于磁盘的数据结构,用于在系统挂掉的时候保证数据的正确性、完整性,也叫预写日志,例如在一个事物的执行过程中,首先会写redo log,然后才会应用实际的更改,这样当系统crash后恢复时就能够根据redo log进行重放从而恢复数据(在初始化的过程中,这个时候不会还没有客户端的连接)。日志也可以用于数据库主从之间的同步,因为本质上,数据库所有的操作记录都已经写入到了日志中,我们只要将日志同步到slave,并在slave重放就能够实现主从同步,这里也可以实现很多其他需要的组件,我们可以通过订阅redo log 从而拿到数据库所有的变更,从而实现个性化的业务逻辑,例如审计、缓存同步等等。
日志在分布式系统中的应用
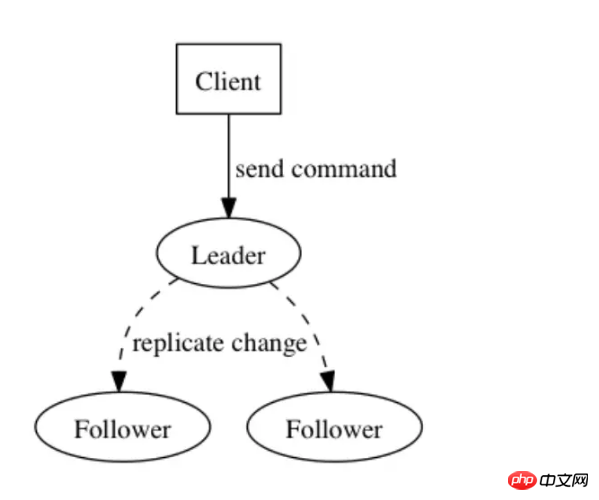
分布式系统服务本质上就是关于状态的变更,这里可以理解为状态机,两个独立的进程(不依赖于外部环境,例如系统时钟、外部接口等)给定一致的输入将会产生一致的输出并最终保持一致的状态,而日志由于其固有的顺序性并不依赖系统时钟,正好可以用来解决变更有序性的问题。
我们利用这个特性实现解决分布式系统中遇到的很多问题。例如RocketMQ中的备节点,主broker接收客户端的请求,并记录日志,然后实时同步到salve中,slave在本地重放,当master挂掉的时候,slave可以继续处理请求,例如拒绝写请求并继续处理读请求。日志中不仅仅可以记录数据,也可以直接记录操作,例如SQL语句。
日志是解决一致性问题的关键数据结构,日志就像是操作序列,每一条记录代表一条指令,例如应用广泛的Paxos、Raft协议,都是基于日志构建起来的一致性协议。
日志在Message Queue中的应用
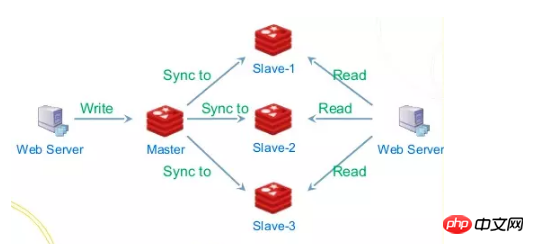
日志可以很方便的用于处理数据之间的流入流出,每一个数据源都可以产生自己的日志,这里数据源可以来自各个方面,例如某个事件流(页面点击、缓存刷新提醒、数据库binlog变更),我们可以将日志集中存储到一个集群中,订阅者可以根据offset来读取日志的每条记录,根据每条记录中的数据、操作应用自己的变更。
这里的日志可以理解为消息队列,消息队列可以起到异步解耦、限流的作用。为什么说解耦呢?因为对于消费者、生产者来说,两个角色的职责都很清晰,就负责生产消息、消费消息,而不用关心下游、上游是谁,不管是来数据库的变更日志、某个事件也好,对于某一方来说我根本不需要关心,我只需要关注自己感兴趣的日志以及日志中的每条记录。
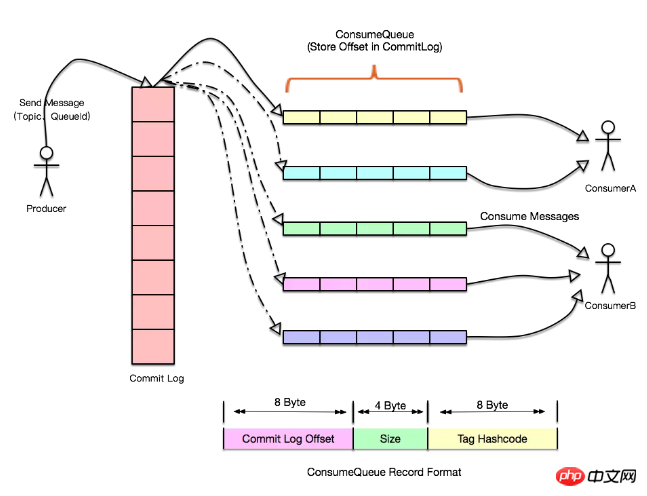
我们知道数据库的QPS是一定的,而上层应用一般可以横向扩容,这个时候如果到了双11这种请求突然的场景,数据库会吃不消,那么我们就可以引入消息队列,将每个队数据库的操作写到日志中,由另外一个应用专门负责消费这些日志记录并应用到数据库中,而且就算数据库挂了,当恢复的时候也可以从上次消息的位置继续处理(RocketMQ和Kafka都支持Exactly Once语义),这里即使生产者的速度异于消费者的速度也不会有影响,日志在这里起到了缓冲的作用,它可以将所有的记录存储到日志中,并定时同步到slave节点,这样消息的积压能力能够得到很好的提升,因为写日志都是有master节点处理,读请求这里分为两种,一种是tail-read,就是说消费速度能够跟得上写入速度的,这种读可以直接走缓存,而另一种也就是落后于写入请求的消费者,这种可以从slave节点读取,这样通过IO隔离以及操作系统自带的一些文件策略,例如pagecache、缓存预读等,性能可以得到很大的提升。
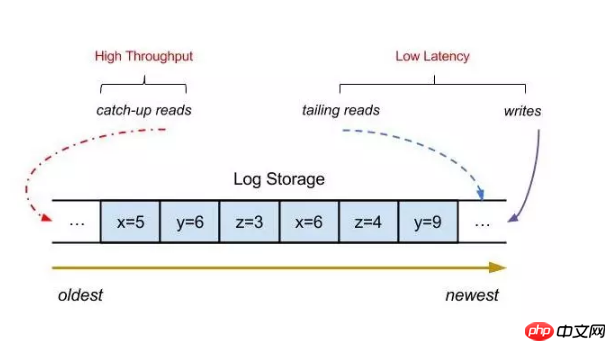
分布式系统中可横向扩展是一个相当重要的特性,加机器能解决的问题都不是问题。那么如何实现一个能够实现横向扩展的消息队列呢? 假如我们有一个单机的消息队列,随着topic数目的上升,IO、CPU、带宽等都会逐渐成为瓶颈,性能会慢慢下降,那么这里如何进行性能优化呢?
1.topic/日志分片,本质上topic写入的消息就是日志的记录,那么随着写入的数量越多,单机会慢慢的成为瓶颈,这个时候我们可以将单个topic分为多个子topic,并将每个topic分配到不同的机器上,通过这种方式,对于那些消息量极大的topic就可以通过加机器解决,而对于一些消息量较少的可以分到到同一台机器或不进行分区
2.group commit,例如Kafka的producer客户端,写入消息的时候,是先写入一个本地内存队列,然后将消息按照每个分区、节点汇总,进行批量提交,对于服务器端或者broker端,也可以利用这种方式,先写入pagecache,再定时刷盘,刷盘的方式可以根据业务决定,例如金融业务可能会采取同步刷盘的方式。
3.规避无用的数据拷贝
4.IO隔离
结语
日志在分布式系统中扮演了很重要的角色,是理解分布式系统各个组件的关键,随着理解的深入,我们发现很多分布式中间件都是基于日志进行构建的,例如Zookeeper、HDFS、Kafka、RocketMQ、Google Spanner等等,甚至于数据库,例如Redis、MySQL等等,其master-slave都是基于日志同步的方式,依赖共享的日志系统,我们可以实现很多系统: 节点间数据同步、并发更新数据顺序问题(一致性问题)、持久性(系统crash时能够通过其他节点继续提供服务)、分布式锁服务等等,相信慢慢的通过实践、以及大量的论文阅读之后,一定会有更深层次的理解。
以上是分布式的系统核心日志的详细介绍(图文)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 win10的事件ID 6013是什么?
Jan 09, 2024 am 10:09 AM
win10的事件ID 6013是什么?
Jan 09, 2024 am 10:09 AM
win10的日志可以帮助用户详细的了解系统使用情况,很多的用户在寻找自己的管理日志的时候,肯定都遇到过日志6013吧,那么这个代码的意思是什么呢,下面就来介绍一下。win10日志6013是什么:1、这个是正常的日志。这个日志的信息并不是表示你的计算机重启了,而是说明自从上次启动以来,系统运行了多长的时间了。该日志会每天12点整出现一次。如何查看系统运行多长时间了,可以在cmd中输入systeminfo。其中有一行就是。
 日志记录器缓冲区大小日志有什么用
Mar 13, 2023 pm 04:27 PM
日志记录器缓冲区大小日志有什么用
Mar 13, 2023 pm 04:27 PM
作用是:给工程师们反馈使用信息与记录便于分析问题(开发时使用的);由于用户本身不是经常产生上传日志,所以对用户无用。日志记录缓冲区是小型的、用于短期存储将写入到磁盘上的重做日志的变更向量的临时区域。日志缓冲区对磁盘的一次写入是来自多个事务的一批变更向量。即使如此,日志缓冲区中的变更向量也是接近实时地写入磁盘,当会话发出COMMIT语句时,会实时执行日志缓冲区写操作。
 解决Win10中的事件7034错误日志问题
Jan 11, 2024 pm 02:06 PM
解决Win10中的事件7034错误日志问题
Jan 11, 2024 pm 02:06 PM
win10的日志可以帮助用户详细的了解系统使用情况,很多的用户在寻找自己的管理日志的时候,肯定都看到过很多的错误日志吧,那么该怎么解决他们呢,下面就一起来看看吧。win10日志事件7034怎么解决:1、点击“开始”打开“控制面板”2、找到“管理工具”3、点击“服务”4、找到HDZBCommServiceForV2.0右击“停止服务”,并改为“手动启动”
 如何在ThinkPHP6中使用日志
Jun 20, 2023 am 08:37 AM
如何在ThinkPHP6中使用日志
Jun 20, 2023 am 08:37 AM
随着互联网和Web应用的迅猛发展,日志管理越来越重要。在开发Web应用时,如何查找和定位问题是一个非常关键的问题。日志系统是一种非常有效的工具,可以帮助我们实现这些任务。ThinkPHP6提供了一个强大的日志系统,可以帮助应用程序开发人员更好地管理和跟踪应用程序中发生的事件。本文将介绍如何在ThinkPHP6中使用日志系统,以及如何利用日志系统
 如何在iPhone上的健康应用程序中查看您的用药日志历史记录
Nov 29, 2023 pm 08:46 PM
如何在iPhone上的健康应用程序中查看您的用药日志历史记录
Nov 29, 2023 pm 08:46 PM
iPhone可让您在“健康”App中添加药物,以便跟踪和管理您每天服用的药物、维生素和补充剂。然后,您可以在设备上收到通知时记录已服用或跳过的药物。记录用药后,您可以查看您服用或跳过用药的频率,以帮助您跟踪自己的健康状况。在这篇文章中,我们将指导您在iPhone上的健康应用程序中查看所选药物的日志历史记录。如何在“健康”App中查看用药日志历史记录简短指南:前往“健康”App>浏览“>用药”>用药“>选择一种用药>”选项“&a
 Linux系统查看log日志命令详解!
Mar 06, 2024 pm 03:55 PM
Linux系统查看log日志命令详解!
Mar 06, 2024 pm 03:55 PM
在Linux系统中,可以使用以下命令来查看日志文件的内容:tail命令:tail命令用于显示日志文件的末尾内容。它是查看最新日志信息的常用命令。tail[选项][文件名]常用的选项包括:-n:指定要显示的行数,默认为10行。-f:实时监视文件内容,并在文件更新时自动显示新的内容。示例:tail-n20logfile.txt#显示logfile.txt文件的最后20行内容tail-flogfile.txt#实时监视logfile.txt文件的更新内容head命令:head命令用于显示日志文件的开头
 了解win10日志中事件ID455的含义
Jan 12, 2024 pm 09:45 PM
了解win10日志中事件ID455的含义
Jan 12, 2024 pm 09:45 PM
win10的日志有着很多丰富的内容,很多的用户在寻找自己的管理日志的时候,肯定都见到过事件ID455显示错误,那么它到底是什么意思呢,下面就一起来看看。win10日志中事件ID455是什么:1、ID455是信息存储打开日志文件时<文件>发生的错误<错误>
 linux查看日志的三种命令
Jan 04, 2023 pm 02:00 PM
linux查看日志的三种命令
Jan 04, 2023 pm 02:00 PM
linux查看日志的三种命令分别是:1、tail命令,该命令可以实时查看文件内容的变以及日志文件;2、multitail命令,该命令可以同时监视多个日志文件;3、less命令,该命令可以快速查看日志的更改,并且不会使屏幕混乱。
