

Python模拟微博登陆的方法介绍(附代码)

本篇文章给大家带来的内容是关于Python模拟微博登陆的方法介绍(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
今天想做一个微博爬个人页面的工具,满足一些不可告人的秘密。那么首先就要做那件必做之事!模拟登陆……
我对代码进行了优化,重构成了Python 3.6 版本,并且加入了大量注释方便大家学习。
PC 登录新浪微博时, 在客户端用js预先对用户名、密码都进行了加密, 而且在POST之前会GET 一组参数,这也将作为POST_DATA 的一部分。 这样, 就不能用通常的那种简单方法来模拟POST 登录( 比如 人人网 )。
1、在提交POST请求之前, 需要GET 获取两个参数。
地址是:
http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.3.18)
得到的数据中有 servertime 和 nonce 的值, 是随机的,其他值貌似没什么用。
def get_servertime():
url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=dW5kZWZpbmVk&client=ssologin.js(v1.3.18)&_=1329806375939'
# 返回出来的是一个Response对象,无法直接获取,text后,可以通过正则匹配到
# 大概长这样子的:sinaSSOController.preloginCallBack({"retcode":0,"servertime":1545606770, ...})
data = requests.request('GET', url).text
p = re.compile('\((.*)\)')
try:
json_data = p.search(data).group(1)
data = json.loads(json_data)
servertime = str(data['servertime'])
nonce = data['nonce']
return servertime, nonce
except:
print('获取 severtime 失败!')
return None2、通过httpfox 观察POST 的数据, 参数较复杂,其中 “su" 是加密后的username, sp 是加密后的password。servertime 和 nonce 是上一步得到的。其他参数是不变的。
username 经过了BASE64 计算:
username = base64.encodestring( urllib.quote(username) )[:-1]
password 经过了三次SHA1 加密, 且其中加入了 servertime 和 nonce 的值来干扰。
即: 两次SHA1加密后, 将结果加上 servertime 和 nonce 的值, 再SHA1 算一次。
def get_pwd(pwd, servertime, nonce): # 第一次计算,注意Python3 的加密需要encode,使用bytes pwd1 = hashlib.sha1(pwd.encode()).hexdigest() # 使用pwd1的结果在计算第二次 pwd2 = hashlib.sha1(pwd1.encode()).hexdigest() # 使用第二次的结果再加上之前计算好的servertime和nonce值,hash一次 pwd3_ = pwd2 + servertime + nonce pwd3 = hashlib.sha1(pwd3_.encode()).hexdigest() return pwd3 def get_user(username): # 将@符号转换成url中能够识别的字符 _username = urllib.request.quote(username) # Python3中的base64计算也是要字节 # base64出来后,最后有一个换行符,所以用了切片去了最后一个字符 username = base64.encodebytes(_username.encode())[:-1] return username
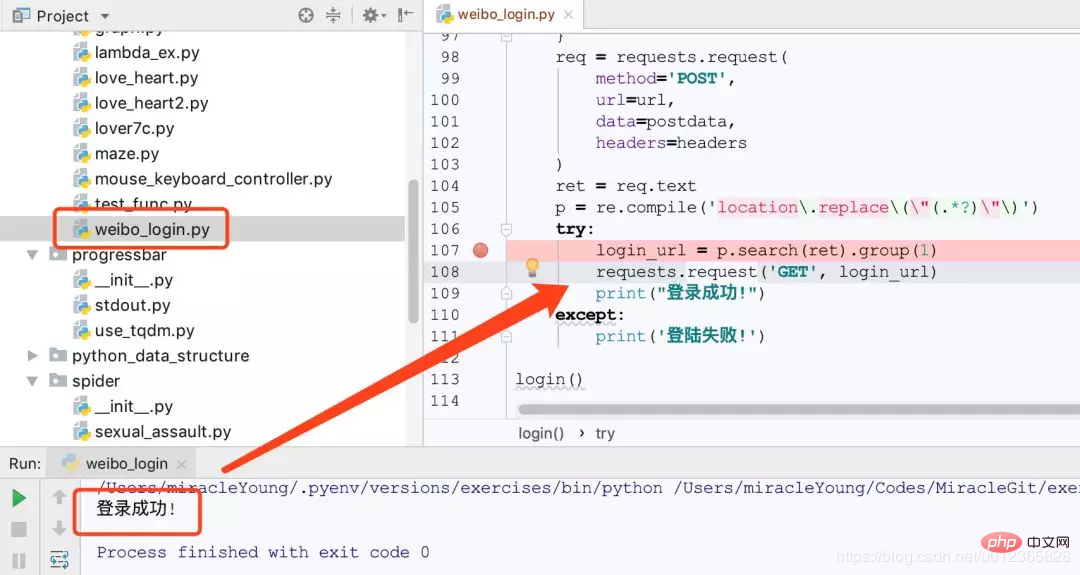
3、将参数组织好, POST请求。 这之后还没有登录成功。
POST后得到的内容中包含一句:
location.replace("http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3%DC%C2%EB%B4%ED%CE%F3")这是登录失败时的结果, 登录成功后结果与之类似, 不过retcode 的值是0 。
接下来再请求这个URL,这样就成功登录到微博了。
记得要提前build 缓存。
以上是Python模拟微博登陆的方法介绍(附代码)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 xml格式怎么打开
Apr 02, 2025 pm 09:00 PM
xml格式怎么打开
Apr 02, 2025 pm 09:00 PM
用大多数文本编辑器即可打开XML文件;若需更直观的树状展示,可使用 XML 编辑器,如 Oxygen XML Editor 或 XMLSpy;在程序中处理 XML 数据则需使用编程语言(如 Python)与 XML 库(如 xml.etree.ElementTree)来解析。
 有没有免费的手机XML转PDF工具?
Apr 02, 2025 pm 09:12 PM
有没有免费的手机XML转PDF工具?
Apr 02, 2025 pm 09:12 PM
没有简单、直接的免费手机端XML转PDF工具。需要的数据可视化过程涉及复杂的数据理解和渲染,市面上所谓的“免费”工具大多体验较差。推荐使用电脑端的工具或借助云服务,或自行开发App以获得更靠谱的转换效果。
 有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
无法找到一款将 XML 直接转换为 PDF 的应用程序,因为它们是两种根本不同的格式。XML 用于存储数据,而 PDF 用于显示文档。要完成转换,可以使用编程语言和库,例如 Python 和 ReportLab,来解析 XML 数据并生成 PDF 文档。
 手机上如何将XML转换成PDF?
Apr 02, 2025 pm 10:18 PM
手机上如何将XML转换成PDF?
Apr 02, 2025 pm 10:18 PM
直接在手机上将XML转换为PDF并不容易,但可以借助云端服务实现。推荐使用轻量级手机App上传XML文件并接收生成的PDF,配合云端API进行转换。云端API使用无服务器计算服务,选择合适的平台至关重要。处理XML解析和PDF生成时需要考虑复杂性、错误处理、安全性和优化策略。整个过程需要前端App与后端API协同工作,需要对多种技术有所了解。
 XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
修改XML内容需要编程,因为它需要精准找到目标节点才能增删改查。编程语言有相应库来处理XML,提供API像操作数据库一样进行安全、高效、可控的操作。
 xml格式化工具推荐
Apr 02, 2025 pm 09:03 PM
xml格式化工具推荐
Apr 02, 2025 pm 09:03 PM
XML格式化工具可以将代码按照规则排版,提高可读性和理解性。选择工具时,要注意自定义能力、对特殊情况的处理、性能和易用性。常用的工具类型包括在线工具、IDE插件和命令行工具。
 xml格式如何美化
Apr 02, 2025 pm 09:57 PM
xml格式如何美化
Apr 02, 2025 pm 09:57 PM
XML 美化本质上是提高其可读性,包括合理的缩进、换行和标签组织。其原理是通过遍历 XML 树,根据层级增加缩进,并处理空标签和包含文本的标签。Python 的 xml.etree.ElementTree 库提供了方便的 pretty_xml() 函数,可以实现上述美化过程。
 怎么在手机上把XML文件转换为PDF?
Apr 02, 2025 pm 10:12 PM
怎么在手机上把XML文件转换为PDF?
Apr 02, 2025 pm 10:12 PM
不可能直接在手机上用单一应用完成 XML 到 PDF 的转换。需要使用云端服务,通过两步走的方式实现:1. 在云端转换 XML 为 PDF,2. 在手机端访问或下载转换后的 PDF 文件。
