

数据仓库需要什么技术

数据仓库技术(Data Warehousing)是基于信息系统业务发展的需要,基于数据库系统技术发展而来,并逐步独立的一系列新的应用技术。数据仓库主要有两大技术:OLTP和OLAP,下面我们来分析一下:

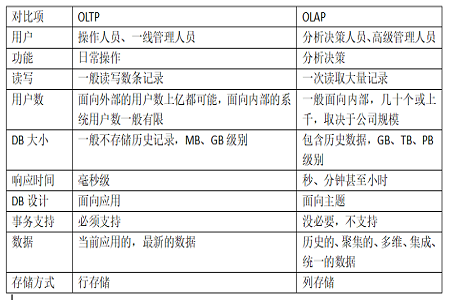
一、OLTP和OLAP
OLTP的全称是 Online Transaction Processing, OLTP主要用传统的关系型数据库来进行事务处理。OLTP最核心的需求是单条记录的高效快速处理,索引技术、分库分表等最根本的诉求就是解决此问题。
OLAP的全称是 Online Analytical Processing,OLAP能够处理和统计大量的数据,不像OLTP数据库需要考虑数据的增删改查和并发控制等,OLAP数据一般只需要处理数据查询请求,数据导入批量导入的,因此通过列存储,列压缩和位图索引等技术可以大大加快响应请求的速度。
二、OLTP和OLAP数据的简单对比
三、数据仓库逻辑架构设计
离线数据仓库通常基于维度建模理论来构建,离线数据仓库通常从逻辑上进行分层,分词主要出于以下考虑:
1、隔离性:用户使用的应该是数据团队精心加工后的数据,而不是来自于业务系统的原始数据,这样做的好处一是,用户使用的是精心准备过的、规范的、干净的、从业务视角的数据。非常容易理解和使用。二是如果上游业务系统发生变革甚至重构(比如表结构、字段、业务含义等),数据团队会负责处理所有这些变化,最小化对下游用户的影响。
2、性能和可为维护性: 专业的人做专业的事,数据分层使得数据的加工基本都在数据团队,从而相同的业务逻辑不用重复执行,节省了相应的存储和计算开销。此外数据分层也使得数据仓库的维护变得清晰和便捷,每层只负责各自的任务,某层的数据加工出现问题,只需要修改该层即可。
3、规范性:对于一个公司和组织来说,数据的口径非常重要,大家谈论一个指标的时候,必须基于一个明确的、公认i的口径,此外表、字段以及指标必须进行规范。
4、ODS层:数据仓库源头系统的数据表通常会原封不动地存储一份,这称为ODS(Operation Data Store)层, ODS层也经常会被称为准备区(Staging area),它们是后续数据仓库层(即基于Kimball维度建模生成的事实表和维度表层,以及基于这些事实表和明细表加工的汇总层数据)加工数据的来源,同时ODS层也存储着历史的增量数据或全量数据。
5、DWD和DWS层:数据仓库明细层(Data Warehouse Detail , DWD)和数据仓库汇总层(Data Warehouse Summary, DWS)是数据仓库的主题内容。DWD和DWS层的数据是ODS层经过ETL清洗、转换、加载生成的,而且它们通常都是基于Kimball的维度建模理论来构建的,并通过一致性维度和数据总线来保证各个子主题的维度一致性。
6、应用层(ADS):应用层主要是各个业务放或者部门基于DWD和DWS建立的数据集市(Data Mart,DM),数据集市DM是相对于DWD和DWS的数据仓库(Data Warehouse, DW)来说的。一般来说,应用层的数据来源于DW层,但原则上不允许直接访问ODS层。此外,相比DW层,应用层只包含部门或因为方自己关心的明细层和汇总层数据。
以上是数据仓库需要什么技术的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 通过MySQL开发实现数据加工与数据仓库的项目经验分享
Nov 03, 2023 am 09:39 AM
通过MySQL开发实现数据加工与数据仓库的项目经验分享
Nov 03, 2023 am 09:39 AM
在当今数字化时代,数据已被普遍认为是企业决策的基础与资本。但是,处理大量数据并将其转化为可靠的决策支持信息的过程并不容易。这时,数据加工和数据仓库开始发挥重要作用。本文将分享一个通过MySQL开发实现数据加工和数据仓库的项目经验。一、项目背景本项目是基于一个商业企业数据化建设的需要,旨在通过数据加工和数据仓库实现数据汇聚、一致性、清洗和可靠性。本次实施的数据
 在Go语言中使用Hive实现高效的数据仓库
Jun 15, 2023 pm 08:52 PM
在Go语言中使用Hive实现高效的数据仓库
Jun 15, 2023 pm 08:52 PM
近年来,数据仓库成为了企业数据管理中不可或缺的一部分。直接使用数据库进行数据分析可以满足简单的查询需求,但当我们需要进行大规模数据分析时,单个数据库已经无法满足需求,这时我们需要使用数据仓库来处理海量数据。而Hive则是数据仓库领域中最流行的开源组件之一,它可以将Hadoop分布式计算引擎和SQL查询集成在一起,并支持海量数据的并行处理。同时,在Go语言中使
 使用统一数据仓库打破数据孤岛:基于Apache Doris的CDP
Mar 20, 2024 pm 01:47 PM
使用统一数据仓库打破数据孤岛:基于Apache Doris的CDP
Mar 20, 2024 pm 01:47 PM
随着企业数据来源日益多样化,数据孤岛问题变得普遍。保险公司在构建客户数据平台(CDP)时,面临着数据孤岛导致的组件密集型计算层,数据存储分散的问题。为了解决这些问题,他们采用了基于 Apache Doris 的 CDP 2.0,利用 Doris 的统一数据仓库能力,打破数据孤岛,简化数据处理管道,提升数据处理效率。
 Go语言如何支持云上的数据仓库和数据分析应用?
May 17, 2023 pm 04:51 PM
Go语言如何支持云上的数据仓库和数据分析应用?
May 17, 2023 pm 04:51 PM
近年来,随着云计算技术的不断发展,云上的数据仓库和数据分析已经成为了越来越多企业所关注的领域。作为一种高效且易于学习的编程语言,Go语言如何支持云上的数据仓库和数据分析应用呢?Go语言的云上数据仓库开发应用在云上开发数据仓库应用,Go语言可以使用多种开发框架和工具,且开发过程通常非常简单。其中,重要的几个工具包括:1.1GoCloudGoCloud是一
 数据仓库相对于操作型数据库来说其突出特点是什么
Jul 19, 2022 pm 04:15 PM
数据仓库相对于操作型数据库来说其突出特点是什么
Jul 19, 2022 pm 04:15 PM
突出特点是“海量数据支持”和“快速检索技术”。数据仓库是决策支持系统和联机分析应用数据源的结构化数据环境,而数据库是整个数据仓库环境的核心,是数据存放的地方和提供对数据检索的支持;相对于操纵型数据库来说其突出的特点是对海量数据的支持和快速的检索技术。
 PHP与数据仓库的集成
May 16, 2023 pm 11:10 PM
PHP与数据仓库的集成
May 16, 2023 pm 11:10 PM
随着互联网和大数据的快速发展,越来越多的企业开始将数据仓库(datawarehouse)作为支撑业务发展的重要基础设施。而作为一种流行的编程语言,PHP也逐渐成为了许多企业和组织的首选,那么如何将PHP与数据仓库集成呢?一、数据仓库概述数据仓库是指以主题为核心,按照一定的数据模型和数据架构建立起来的大型数据存储系统。其目的是为了提高数据的访问速度和查询效率
 如何确保人工智能和分析项目不会失败?
May 08, 2023 pm 06:40 PM
如何确保人工智能和分析项目不会失败?
May 08, 2023 pm 06:40 PM
2023年是经济危机和气候风险不断升级的一年,因此需要数据驱动的见解来推动效率、弹性和其他关键举措,这将是企业在2023年的首要任务。许多企业一直在尝试采用先进的分析技术和人工智能来满足这一需求。现在,他们必须把对概念的验证转化为投资回报。很多企业正在取得巨大进步,投入了大量人才和合适的软件。然而,也有许多企业的人工智能和分析项目遭遇失败,因为他们没有采用正确的基础技术来支持人工智能和高级分析工作负载。有些企业依赖于过时的传统硬件系统,有些企业则受到利用公有云带来的成本和控制问题的阻碍。大多数企
 如何使用Java开发一个基于Hive的数据仓库应用
Sep 21, 2023 pm 04:48 PM
如何使用Java开发一个基于Hive的数据仓库应用
Sep 21, 2023 pm 04:48 PM
如何使用Java开发一个基于Hive的数据仓库应用引言:在当今大数据时代,数据仓库是企业存储和处理海量数据的重要工具。Hive作为Hadoop生态系统中的一员,提供了数据仓库解决方案。本文旨在介绍如何使用Java开发一个基于Hive的数据仓库应用,并提供详细的代码示例。一、准备工作在开始之前,我们需要确保以下几点:安装Hadoop和Hive,并确保其正常运行