

以Python代码实例展示kNN算法的实际运用_基础知识

邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
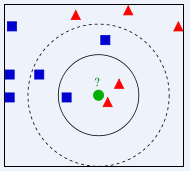
上图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。
用 kNN 算法预测豆瓣电影用户的性别
摘要
本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验。利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类型作为属性特征,以用户性别作为标签构建样本集。使用kNN算法构建豆瓣电影用户性别分类器,使用样本中的90%作为训练样本,10%作为测试样本,准确率可以达到81.48%。
实验数据
本次实验所用数据为豆瓣用户标记的看过的电影,选取了274位豆瓣用户最近看过的100部电影。对每个用户的电影类型进行统计。本次实验所用数据中共有37个电影类型,因此将这37个类型作为用户的属性特征,各特征的值即为用户100部电影中该类型电影的数量。用户的标签为其性别,由于豆瓣没有用户性别信息,因此均为人工标注。
数据格式如下所示:
X1,1,X1,2,X1,3,X1,4……X1,36,X1,37,Y1 X2,1,X2,2,X2,3,X2,4……X2,36,X2,37,Y2 ………… X274,1,X274,2,X274,3,X274,4……X274,36,X274,37,Y274
示例:
0,0,0,3,1,34,5,0,0,0,11,31,0,0,38,40,0,0,15,8,3,9,14,2,3,0,4,1,1,15,0,0,1,13,0,0,1,1 0,1,0,2,2,24,8,0,0,0,10,37,0,0,44,34,0,0,3,0,4,10,15,5,3,0,0,7,2,13,0,0,2,12,0,0,0,0
像这样的数据一共有274行,表示274个样本。每一个的前37个数据是该样本的37个特征值,最后一个数据为标签,即性别:0表示男性,1表示女性。
在此次试验中取样本的前10%作为测试样本,其余作为训练样本。
首先对所有数据归一化。对矩阵中的每一列求取最大值(max_j)、最小值(min_j),对矩阵中的数据X_j,
X_j=(X_j-min_j)/(max_j-min_j) 。
然后对于每一条测试样本,计算其与所有训练样本的欧氏距离。测试样本i与训练样本j之间的距离为:
distance_i_j=sqrt((Xi,1-Xj,1)^2+(Xi,2-Xj,2)^2+……+(Xi,37-Xj,37)^2) ,
对样本i的所有距离从小到大排序,在前k个中选择出现次数最多的标签,即为样本i的预测值。
实验结果
首先选择一个合适的k值。 对于k=1,3,5,7,均使用同一个测试样本和训练样本,测试其正确率,结果如下表所示。
选取不同k值的正确率表
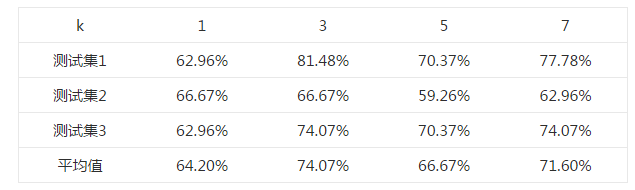
由上述结果可知,在k=3时,测试的平均正确率最高,为74.07%,最高可以达到81.48%。
上述不同的测试集均来自同一样本集中,为随机选取所得。
Python代码
这段代码并非原创,来自《机器学习实战》(Peter Harrington,2013),并有所改动。
#coding:utf-8
from numpy import *
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,37)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
returnMat[index,:] = listFromLine[0:37]
classLabelVector.append(int(listFromLine[-1]))
index += 1
fr.close()
return returnMat,classLabelVector
def genderClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('doubanMovieDataSet.txt') #load data setfrom file
normMat,ranges,minVals=autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
testMat=normMat[0:numTestVecs,:]
trainMat=normMat[numTestVecs:m,:]
trainLabels=datingLabels[numTestVecs:m]
k=3
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(testMat[i,:],trainMat,trainLabels,k)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "Total errors:%d" %errorCount
print "The total accuracy rate is %f" %(1.0-errorCount/float(numTestVecs))

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上运行,但体验可能不佳。首先确保系统已更新到最新补丁,然后下载与系统架构匹配的VS Code安装包,按照提示安装。安装后,注意某些扩展程序可能与Windows 8不兼容,需要寻找替代扩展或在虚拟机中使用更新的Windows系统。安装必要的扩展,检查是否正常工作。尽管VS Code在Windows 8上可行,但建议升级到更新的Windows系统以获得更好的开发体验和安全保障。
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
 visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
VS Code 可用于编写 Python,并提供许多功能,使其成为开发 Python 应用程序的理想工具。它允许用户:安装 Python 扩展,以获得代码补全、语法高亮和调试等功能。使用调试器逐步跟踪代码,查找和修复错误。集成 Git,进行版本控制。使用代码格式化工具,保持代码一致性。使用 Linting 工具,提前发现潜在问题。
 vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
在 VS Code 中,可以通过以下步骤在终端运行程序:准备代码和打开集成终端确保代码目录与终端工作目录一致根据编程语言选择运行命令(如 Python 的 python your_file_name.py)检查是否成功运行并解决错误利用调试器提升调试效率
 vscode 可以用于 mac 吗
Apr 15, 2025 pm 07:36 PM
vscode 可以用于 mac 吗
Apr 15, 2025 pm 07:36 PM
VS Code 可以在 Mac 上使用。它具有强大的扩展功能、Git 集成、终端和调试器,同时还提供了丰富的设置选项。但是,对于特别大型项目或专业性较强的开发,VS Code 可能会有性能或功能限制。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
