

学习PHP7的革新与性能优化


PHP已经走过了20年的历史,PHP7对于上一个系列的PHP5,可以说是一个大规模的革新,尤其是在性能方面实现跨越式的大幅提升。PHP是一种在全球范围内被广泛使用的Web开发语言,PHP7的革新也当然会给这些Web服务带来更深刻的变化。
这里引用鸟哥PPT中的一个图表(82%的Web站点有使用PHP作为开发语言):
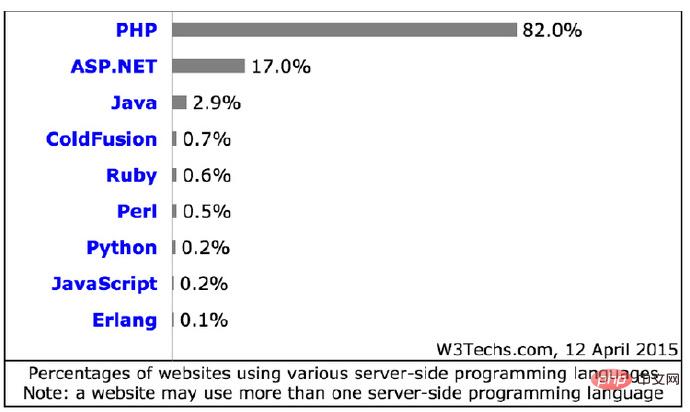
(注:一个web站点可以会使用多种语言作为它的开发语言)
(注:本文含有不少从鸟哥PPT里的截图,图片版权归鸟哥所有)
我们先看看两张激动人心的性能测试结果图
PHP7的性能测试结果,性能压测结果,耗时从2.991下降到1.186,大幅度下降60%。
WordPress的QPS压测(图片来自于PPT):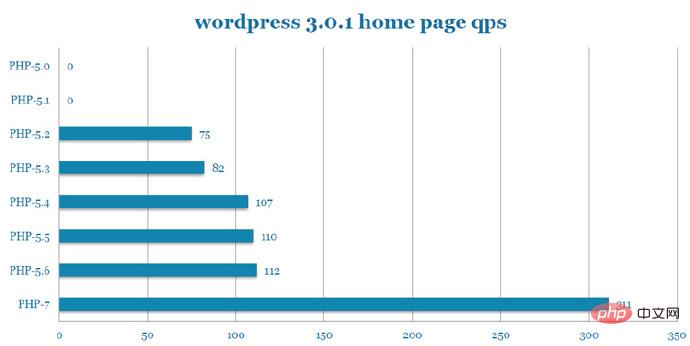
而在WordPress项目中,PHP7对比PHP5.6,QPS提升2.77倍。
看完令人激动的性能测试结果对比,我们就进入正题哈。PHP7的新增特性很多,不过,我们会更聚焦于那些主要的变化。
一、新增特性和改变
1. 标量类型和返回类型声明(Scalar Type Declarations & Scalar Type Declarations)
PHP语言一个非常重要的特点就是“弱类型”,它让PHP的程序变得非常容易编写,新手接触PHP能够快速上手,不过,它也伴随着一些争议。支持变量类型的定义,可以说是革新性质的变化,PHP开始以可选的方式支持类型定义。除此之外,还引入了一个开关指令declare(strict_type=1);,当这个指令一旦开启,将会强制当前文件下的程序遵循严格的函数传参类型和返回类型。
例如一个add函数加上类型定义,可以写成这样:
如果配合强制类型开关指令,则可以变为这样:
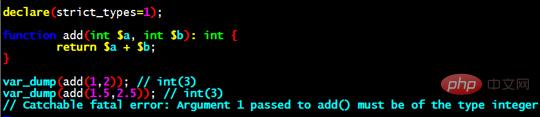
如果不开启strict_type,PHP将会尝试帮你转换成要求的类型,而开启之后,会改变PHP就不再做类型转换,类型不匹配就会抛出错误。对于喜欢“强类型”语言的同学来说,这是一大福音。
更为详细的介绍:PHP7标量类型声明RFC[翻译]
2. 更多的Error变为可捕获的Exception
PHP7实现了一个全局的throwable接口,原来的Exception和部分Error都实现了这个接口(interface), 以接口的方式定义了异常的继承结构。于是,PHP7中更多的Error变为可捕获的Exception返回给开发者,如果不进行捕获则为Error,如果捕获就变为一个可在程序内处理的Exception。这些可被捕获的Error通常都是不会对程序造成致命伤害的Error,例如函数不存。PHP7进一步方便开发者处理,让开发者对程序的掌控能力更强。因为在默认情况下,Error会直接导致程序中断,而PHP7则提供捕获并且处理的能力,让程序继续执行下去,为程序员提供更灵活的选择。
例如,执行一个我们不确定是否存在的函数,PHP5兼容的做法是在函数被调用之前追加的判断function_exist,而PHP7则支持捕获Exception的处理方式。
如下图中的例子(截图来源于PPT内):
3. AST(Abstract Syntax Tree,抽象语法树)
AST在PHP编译过程作为一个中间件的角色,替换原来直接从解释器吐出opcode的方式,让解释器(parser)和编译器(compliler)解耦,可以减少一些Hack代码,同时,让实现更容易理解和可维护。
PHP5: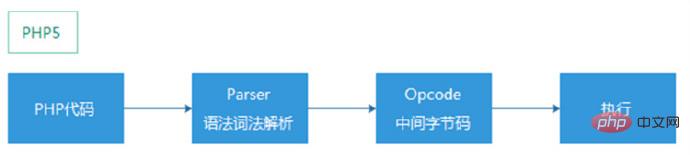
PHP7:
更多AST信息:https://wiki.php.net/rfc/abstract_syntax_tree
4. Native TLS(Native Thread local storage,原生线程本地存储)
PHP在多线程模式下(例如,Web服务器Apache的woker和event模式,就是多线程),需要解决“线程安全”(TS,Thread Safe)的问题,因为线程是共享进程的内存空间的,所以每个线程本身需要通过某种方式,构建私有的空间来保存自己的私有数据,避免和其他线程相互污染。而PHP5采用的方式,就是维护一个全局大数组,为每一个线程分配一份独立的存储空间,线程通过各自拥有的key值来访问这个全局数据组。
而这个独有的key值在PHP5中需要传递给每一个需要用到全局变量的函数,PHP7认为这种传递的方式并不友好,并且存在一些问题。因而,尝试采用一个全局的线程特定变量来保存这个key值。
相关的Native TLS问题:
https://wiki.php.net/rfc/native-tls
5. 其他新特性
PHP7新特性和变化不少,我们这里并不全部展开来细说哈。
(1) Int64支持,统一不同平台下的整型长度,字符串和文件上传都支持大于2GB。
(2) 统一变量语法(Uniform variable syntax)。
(3) foreach表现行为一致(Consistently foreach behaviors)
(4) 新的操作符 <=>, ??
(5) Unicode字符格式支持(\u{xxxxx})
(6) 匿名类支持(Anonymous Class)
… …
二、跨越式的性能突破:全速前进
1. JIT与性能
Just In Time(即时编译)是一种软件优化技术,指在运行时才会去编译字节码为机器码。从直觉出发,我们都很容易认为,机器码是计算机能够直接识别和执行的,比起Zend读取opcode逐条执行效率会更高。其中,HHVM(HipHop Virtual Machine,HHVM是一个Facebook开源的PHP虚拟机)就采用JIT,让他们的PHP性能测试提升了一个数量级,放出一个令人震惊的测试结果,也让我们直观地认为JIT是一项点石成金的强大技术。
而实际上,在2013年的时候,鸟哥和Dmitry(PHP语言内核开发者之一)就曾经在PHP5.5的版本上做过一个JIT的尝试(并没有发布)。PHP5.5的原来的执行流程,是将PHP代码通过词法和语法分析,编译成opcode字节码(格式和汇编有点像),然后,Zend引擎读取这些opcode指令,逐条解析执行。

而他们在opcode环节后引入了类型推断(TypeInf),然后通过JIT生成ByteCodes,然后再执行。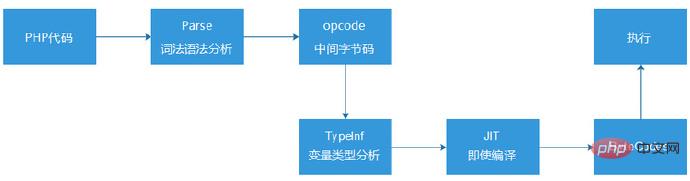
于是,在benchmark(测试程序)中得到令人兴奋的结果,实现JIT后性能比PHP5.5提升了8倍。然而,当他们把这个优化放入到实际的项目WordPress(一个开源博客项目)中,却几乎看不见性能的提升,得到了一个令人费解的测试结果。
于是,他们使用Linux下的profile类型工具,对程序执行进行CPU耗时占用分析。
执行100次WordPress的CPU消耗的分布(截图来自PPT):
注解:
21%CPU时间花费在内存管理。
12%CPU时间花费在hash table操作,主要是PHP数组的增删改查。
30%CPU时间花费在内置函数,例如strlen。
25%CPU时间花费在VM(Zend引擎)。
经过分析之后,得到了两个结论:
(1)JIT生成的ByteCodes如果太大,会引起CPU缓存命中率下降(CPU Cache Miss)
在PHP5.5的代码里,因为并没有明显类型定义,只能靠类型推断。尽可能将可以推断出来的变量类型,定义出来,然后,结合类型推断,将非该类型的分支代码去掉,生成直接可执行的机器码。然而,类型推断不能推断出全部类型,在WordPress中,能够推断出来的类型信息只有不到30%,能够减少的分支代码有限。导致JIT以后,直接生成机器码,生成的ByteCodes太大,最终引起CPU缓存命中大幅度下降(CPU Cache Miss)。
CPU缓存命中是指,CPU在读取并执行指令的过程中,如果需要的数据在CPU一级缓存(L1)中读取不到,就不得不往下继续寻找,一直到二级缓存(L2)和三级缓存(L3),最终会尝试到内存区域里寻找所需要的指令数据,而内存和CPU缓存之间的读取耗时差距可以达到100倍级别。所以,ByteCodes如果过大,执行指令数量过多,导致多级缓存无法容纳如此之多的数据,部分指令将不得不被存放到内存区域。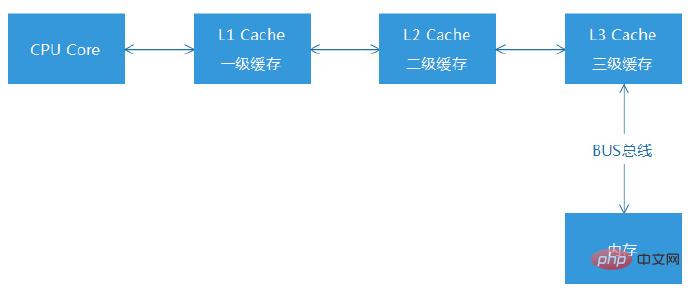
CPU的各级缓存的大小也是有限的,下图是Intel i7 920的配置信息: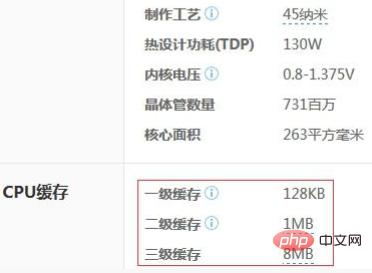
因此,CPU缓存命中率下降会带来严重的耗时增加,另一方面,JIT带来的性能提升,也被它所抵消掉了。
通过JIT,可以降低VM的开销,同时,通过指令优化,可以间接降低内存管理的开发,因为可以减少内存分配的次数。然而,对于真实的WordPress项目来说,CPU耗时只有25%在VM上,主要的问题和瓶颈实际上并不在VM上。因此,JIT的优化计划,最后没有被列入该版本的PHP7特性中。不过,它很可能会在更后面的版本中实现,这点也非常值得我们期待哈。
(2)JIT性能的提升效果取决于项目的实际瓶颈
JIT在benchmark中有大幅度的提升,是因为代码量比较少,最终生成的ByteCodes也比较小,同时主要的开销是在VM中。而应用在WordPress实际项目中并没有明显的性能提升,原因WordPress的代码量要比benchmark大得多,虽然JIT降低了VM的开销,但是因为ByteCodes太大而又引起CPU缓存命中下降和额外的内存开销,最终变成没有提升。
不同类型的项目会有不同的CPU开销比例,也会得到不同的结果,脱离实际项目的性能测试,并不具有很好的代表性。
2. Zval的改变
PHP的各种类型的变量,其实,真正存储的载体就是Zval,它特点是海纳百川,有容乃大。从本质上看,它是C语言实现的一个结构体(struct)。对于写PHP的同学,可以将它粗略理解为是一个类似array数组的东西。
PHP5的Zval,内存占据24个字节(截图来自PPT):
PHP7的Zval,内存占据16个字节(截图来自PPT):
Zval从24个字节下降到16个字节,为什么会下降呢,这里需要补一点点的C语言基础,辅助不熟悉C的同学理解。struct和union(联合体)有点不同,Struct的每一个成员变量要各自占据一块独立的内存空间,而union里的成员变量是共用一块内存空间(也就是说修改其中一个成员变量,公有空间就被修改了,其他成员变量的记录也就没有了)。因此,虽然成员变量看起来多了不少,但是实际占据的内存空间却下降了。
除此之外,还有被明显改变的特性,部分简单类型不再使用引用。
Zval结构图(来源于PPT中):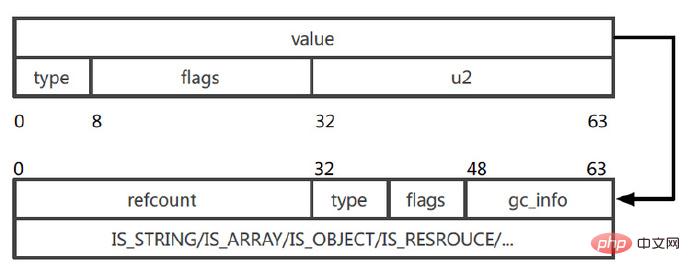
图中Zval的由2个64bits(1字节=8bit,bit是“位”)组成,如果变量类型是long、bealoon这些长度不超过64bit的,则直接存储到value中,就没有下面的引用了。当变量类型是array、objec、string等超过64bit的,value存储的就是一个指针,指向真实的存储结构地址。
对于简单的变量类型来说,Zval的存储变得非常简单和高效。
不需要引用的类型:NULL、Boolean、Long、Double
需要引用的类型:String、Array、Object、Resource、Reference
3. 内部类型zend_string
Zend_string是实际存储字符串的结构体,实际的内容会存储在val(char,字符型)中,而val是一个char数组,长度为1(方便成员变量占位)。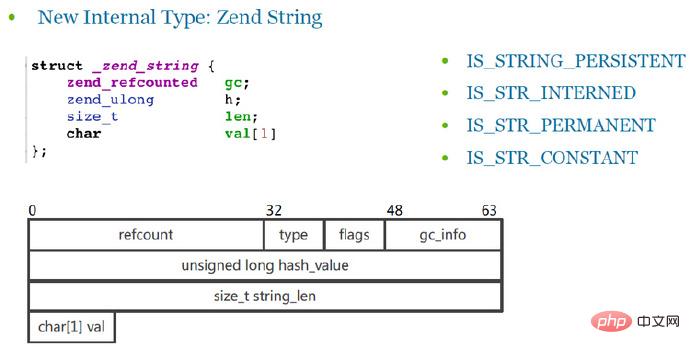
结构体最后一个成员变量采用char数组,而不是使用char*,这里有一个小优化技巧,可以降低CPU的cache miss。
如果使用char数组,当malloc申请上述结构体内存,是申请在同一片区域的,通常是长度是sizeof(_zend_string) + 实际char存储空间。但是,如果使用char*,那个这个位置存储的只是一个指针,真实的存储又在另外一片独立的内存区域内。
使用char[1]和char*的内存分配对比:
从逻辑实现的角度来看,两者其实也没有多大区别,效果很类似。而实际上,当这些内存块被载入到CPU的中,就显得非常不一样。前者因为是连续分配在一起的同一块内存,在CPU读取时,通常都可以一同获得(因为会在同一级缓存中)。而后者,因为是两块内存的数据,CPU读取第一块内存的时候,很可能第二块内存数据不在同一级缓存中,使CPU不得不往L2(二级缓存)以下寻找,甚至到内存区域查到想要的第二块内存数据。这里就会引起CPU Cache Miss,而两者的耗时最高可以相差100倍。
另外,在字符串复制的时候,采用引用赋值,zend_string可以避免的内存拷贝。
6. PHP数组的变化(HashTable和Zend Array)
在编写PHP程序过程中,使用最频繁的类型莫过于数组,PHP5的数组采用HashTable实现。如果用比较粗略的概括方式来说,它算是一个支持双向链表的HashTable,不仅支持通过数组的key来做hash映射访问元素,也能通过foreach以访问双向链表的方式遍历数组元素。
PHP5的HashTable(截图来自于PPT):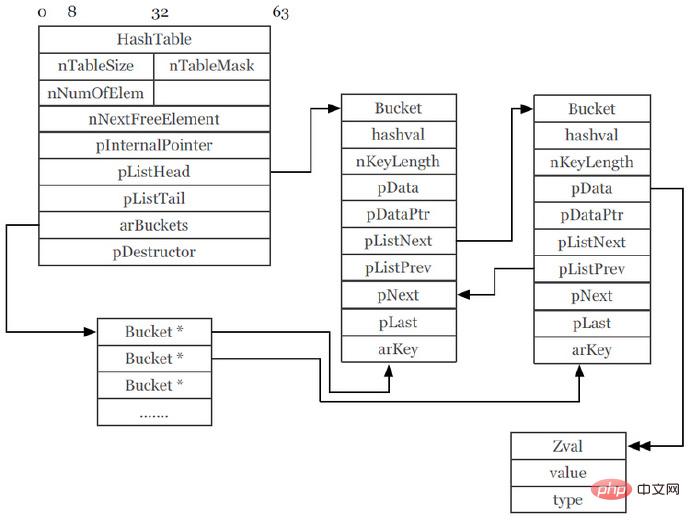
这个图看起来很复杂,各种指针跳来跳去,当我们通过key值访问一个元素内容的时候,有时需要3次的指针跳跃才能找对需要的内容。而最重要的一点,就在于这些数组元素存储,都是分散在各个不同的内存区域的。同理可得,在CPU读取的时候,因为它们就很可能不在同一级缓存中,会导致CPU不得不到下级缓存甚至内存区域查找,也就是引起CPU缓存命中下降,进而增加更多的耗时。
PHP7的Zend Array(截图来源于PPT):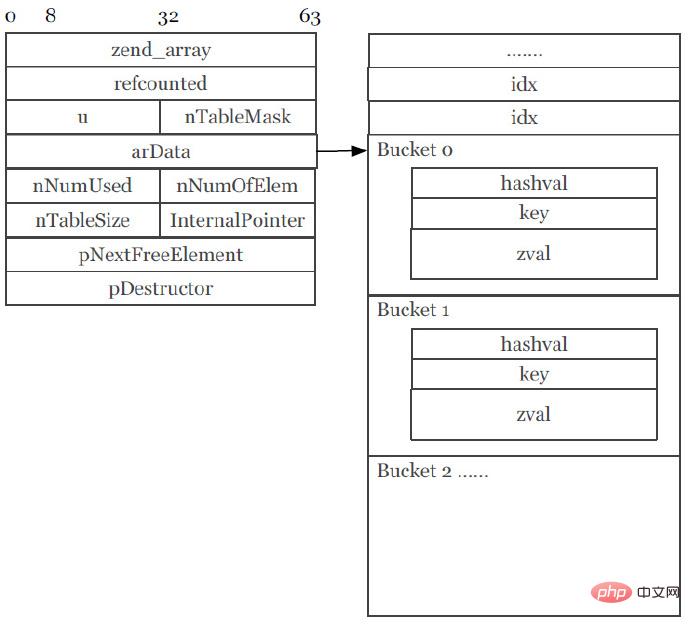
新版本的数组结构,非常简洁,让人眼前一亮。最大的特点是,整块的数组元素和hash映射表全部连接在一起,被分配在同一块内存内。如果是遍历一个整型的简单类型数组,效率会非常快,因为,数组元素(Bucket)本身是连续分配在同一块内存里,并且,数组元素的zval会把整型元素存储在内部,也不再有指针外链,全部数据都存储在当前内存区域内。当然,最重要的是,它能够避免CPU Cache Miss(CPU缓存命中率下降)。
Zend Array的变化:
(1) 数组的value默认为zval。
(2) HashTable的大小从72下降到56字节,减少22%。
(3) Buckets的大小从72下降到32字节,减少50%。
(4) 数组元素的Buckets的内存空间是一同分配的。
(5) 数组元素的key(Bucket.key)指向zend_string。
(6) 数组元素的value被嵌入到Bucket中。
(7) 降低CPU Cache Miss。
7. 函数调用机制(Function Calling Convention)
PHP7改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率。
PHP5的函数调用机制(截图来自于PPT):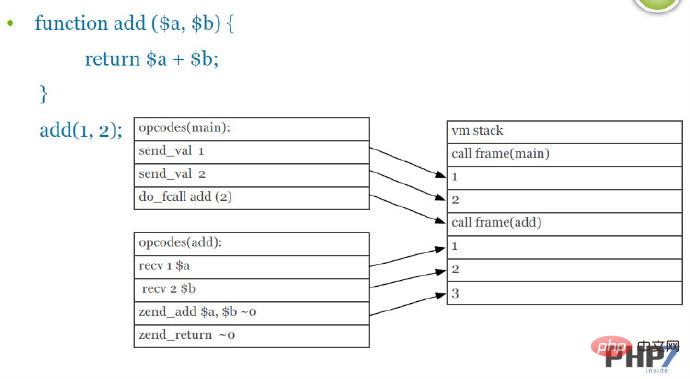
图中,在vm栈中的指令send_val和recv参数的指令是相同,PHP7通过减少这两条重复,来达到对函数调用机制的底层优化。
PHP7的函数调用机制(截图来自于PPT):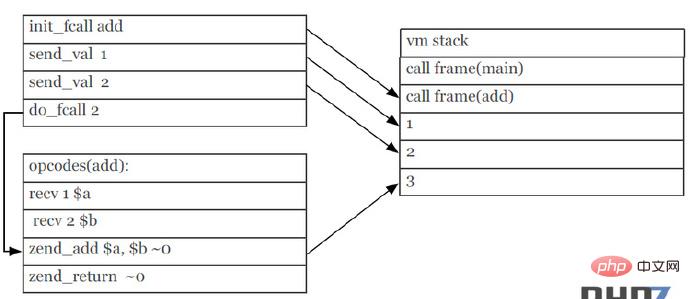
8. 通过宏定义和内联函数(inline),让编译器提前完成部分工作
C语言的宏定义会被在预处理阶段(编译阶段)执行,提前将部分工作完成,无需在程序运行时分配内存,能够实现类似函数的功能,却没有函数调用的压栈、弹栈开销,效率会比较高。内联函数也类似,在预处理阶段,将程序中的函数替换为函数体,真实运行的程序执行到这里,就不会产生函数调用的开销。
PHP7在这方面做了不少的优化,将不少需要在运行阶段要执行的工作,放到了编译阶段。例如参数类型的判断(Parameters Parsing),因为这里涉及的都是固定的字符常量,因此,可以放到到编译阶段来完成,进而提升后续的执行效率。
例如处理传递参数类型的方式,从左边的写法,优化为右边宏的写法。
三、小结
鸟哥的PPT里放出过一组对比数据,就是WordPress在PHP5.6执行100次会产生70亿次的CPU指令执行数目,而在PHP7中只需要25亿次,减少64.2%,这是一个令人震撼的数据。
在鸟哥的整个分享中,给我最深刻的一个观点是:要注意细节,很多个细小的优化,一点点持续地积累,积少成多,最终汇聚为惊艳的成果。为山九仞,岂一日之功,我想大概也是这个道理。
毫无疑问,PHP7在性能方面实现跨越式的提升,如果能够将这些成果应用在PHP的Web系统中,也许我们只需要更少的机器,就可以支撑起更高请求量的服务。PHP7正式版的发布,令人充满无限憧憬。
推荐教程:《php视频教程》
以上是学习PHP7的革新与性能优化的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。
热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Go 框架的性能优化与横向扩展技术?
Jun 03, 2024 pm 07:27 PM
Go 框架的性能优化与横向扩展技术?
Jun 03, 2024 pm 07:27 PM
为了提高Go应用程序的性能,我们可以采取以下优化措施:缓存:使用缓存减少对底层存储的访问次数,提高性能。并发:使用goroutine和channel并行执行冗长的任务。内存管理:手动管理内存(使用unsafe包)以进一步优化性能。为了横向扩展应用程序,我们可以实施以下技术:水平扩展(横向扩展):在多个服务器或节点上部署应用程序实例。负载均衡:使用负载均衡器将请求分配到多个应用程序实例。数据分片:将大型数据集分布在多个数据库或存储节点上,提高查询性能和可扩展性。
 利用 C++ 优化火箭发动机性能
Jun 01, 2024 pm 04:14 PM
利用 C++ 优化火箭发动机性能
Jun 01, 2024 pm 04:14 PM
通过建立数学模型、进行模拟和优化参数,C++可显着提高火箭发动机性能:建立火箭发动机的数学模型,描述其行为。模拟发动机性能,计算关键参数(如推力和比冲)。识别关键参数并使用优化算法(如遗传算法)搜索最佳值。根据优化后的参数重新计算发动机性能,提高其整体效率。
 C++ 性能优化指南:探索提高代码执行效率的秘诀
Jun 01, 2024 pm 05:13 PM
C++ 性能优化指南:探索提高代码执行效率的秘诀
Jun 01, 2024 pm 05:13 PM
C++性能优化涉及多种技术,包括:1.避免动态分配;2.使用编译器优化标志;3.选择优化数据结构;4.应用缓存;5.并行编程。优化实战案例展示了如何在整数数组中查找最长上升子序列时应用这些技术,将算法效率从O(n^2)提升至O(nlogn)。
 优化之道:探寻java框架的性能提升之旅
Jun 01, 2024 pm 07:07 PM
优化之道:探寻java框架的性能提升之旅
Jun 01, 2024 pm 07:07 PM
通过实施缓存机制、并行处理、数据库优化和减少内存消耗,可以提升Java框架的性能。缓存机制:减少数据库或API请求次数,提高性能。并行处理:利用多核CPU同时执行任务,提高吞吐量。数据库优化:优化查询、使用索引、配置连接池,提升数据库性能。减少内存消耗:使用轻量级框架、避免泄漏、使用分析工具,减少内存消耗。
 Java 中如何使用轮廓分析来优化性能?
Jun 01, 2024 pm 02:08 PM
Java 中如何使用轮廓分析来优化性能?
Jun 01, 2024 pm 02:08 PM
Java中的轮廓分析用于确定应用程序执行中的时间和资源消耗。使用JavaVisualVM实施轮廓分析:连接到JVM开启轮廓分析,设置采样间隔运行应用程序停止轮廓分析分析结果显示执行时间的树形视图。优化性能的方法包括:识别热点减少方法调用优化算法
 Java微服务架构中的性能优化
Jun 04, 2024 pm 12:43 PM
Java微服务架构中的性能优化
Jun 04, 2024 pm 12:43 PM
针对Java微服务架构的性能优化包含以下技巧:使用JVM调优工具来识别和调整性能瓶颈。优化垃圾回收器,选择并配置与应用程序需求相匹配的GC策略。使用缓存服务(如Memcached或Redis)来提升响应时间并降低数据库负载。采用异步编程,以提高并发性和响应能力。拆分微服务,将大型单体应用程序分解成更小的服务,以提升可伸缩性和性能。
 如何使用C++优化Web应用程序的性能?
Jun 02, 2024 pm 05:58 PM
如何使用C++优化Web应用程序的性能?
Jun 02, 2024 pm 05:58 PM
优化Web应用程序性能的C++技术:使用现代编译器和优化标志避免动态内存分配最小化函数调用利用多线程使用高效的数据结构实战案例显示:优化技术可显着提升性能:执行时间减少20%内存开销减少15%函数调用开销减少10%吞吐量提高30%
 如何快速诊断 PHP 性能问题
Jun 03, 2024 am 10:56 AM
如何快速诊断 PHP 性能问题
Jun 03, 2024 am 10:56 AM
快速诊断PHP性能问题的有效技术包括:使用Xdebug获取性能数据,然后分析Cachegrind输出。使用Blackfire查看请求跟踪,生成性能报告。检查数据库查询,识别低效查询。分析内存使用情况,查看内存分配和峰值使用。
