

单表查询是什么

单表查询指的是在一张表中进行数据的查询,它的执行顺序是“from->where->group by->having->distinct->order by->limit->select”。

在数据库操作中,单表查询就是在一张表中进行数据的查询,详细它的语法是:
select distinct 字段1,字段2... from 表名 where 分组之前的过滤条件 group by 分组字段 having 分组之后的过滤条件 order by 排序字段 limit 显示的条数;
语法是样的一个顺序,但是它的执行顺序就不是从语法的顺序来执行了,而是这样的一个顺序。
from--->where--->group by--->having-->distinct--->order by--->limit--->select
至于为什么这样的一个执行顺序,我就不说了,也没这个自信说清楚。如果小白只要记得是这个执行顺序就可以了,如果非要刨根问底,可以去google一下。
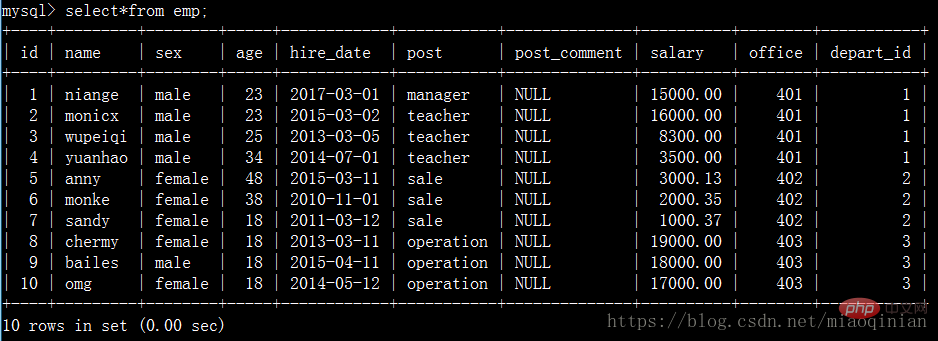
在了解单表查询前,我们首先来建一张雇员表:
emp表: 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
建表:
create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, depart_id int );
插入数据:
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('niange','male',23,'20170301','manager',15000,401,1), ('monicx','male',23,'20150302','teacher',16000,401,1), ('wupeiqi','male',25,'20130305','teacher',8300,401,1), ('yuanhao','male',34,'20140701','teacher',3500,401,1), ('anny','female',48,'20150311','sale',3000.13,402,2), ('monke','female',38,'20101101','sale',2000.35,402,2), ('sandy','female',18,'20110312','sale',1000.37,402,2), ('chermy','female',18,'20130311','operation',19000,403,3), ('bailes','male',18,'20150411','operation',18000,403,3), ('omg','female',18,'20140512','operation',17000,403,3);
where条件过滤
where字句中可以使用:
1. 比较运算符:>、<、>=、 <=、 <>、!=。
2. between 1 and 5 值在1到5之间。
3. in(1,3,8) 值是1或3或8。
4. like 'monicx%'
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and、or、not。
6、正则表达式
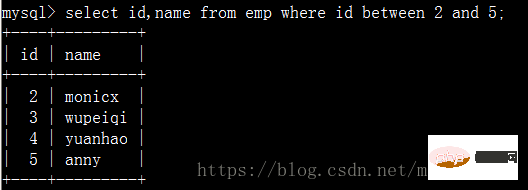
查找员工id在2到5之间的名字:
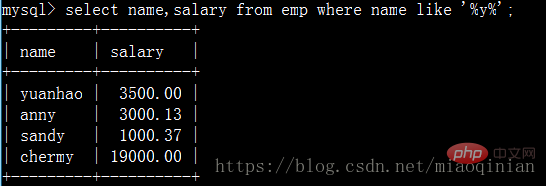
查询员工姓名中包含y字母的员工姓名与其薪资:
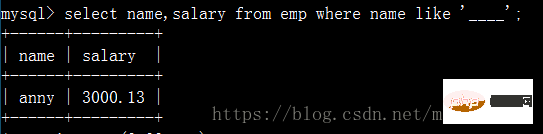
查询员工姓名是由四个字符组成的的员工姓名与其薪资:
查询岗位描述为空的员工名与岗位名:
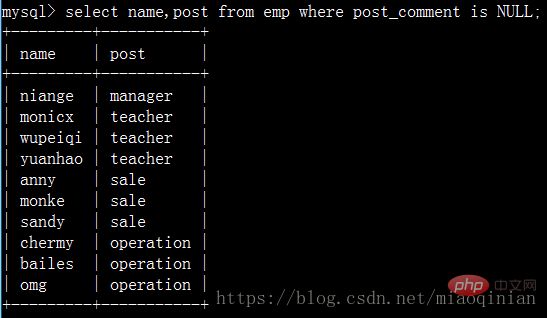
查询名字是字母m开头,以字母e或x结尾的员工!些时就可以用到正则表达示了,mysql里提供了regexp来现正则。

group by分组
先设置mysq的sql_mode为only_full_group_by,意味着以后但凡分组,只能取到分组的依据。
set global sql_mode="strict_trans_tables,only_full_group_by";
分组发生在where之后,即分组是基于where之后得到的记录而进行的。
分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
怎么要分组呢?
如:取每个部门的最高工资。
如:取每个部门的员工数。
每’这个字后面的字段,就是我们分组的依据。
注意:我们可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段。
但如果想查看组内信息,需要借助于聚合(聚在一起合成一个内容)函数
每个部门的最高工资 select post,max(salary) from emp group by post; 每个部门的最底工资 select post,min(salary) from emp group by post; 每个部门的平均工资 select post,avg(salary) from emp group by post; 每个部门的工资总合 select post,sum(salary) from emp group by post; 每个部门的总人数 select post,count(id) from emp group by post;
group_concat(分组之后用来用它获得组内字段的内容。)
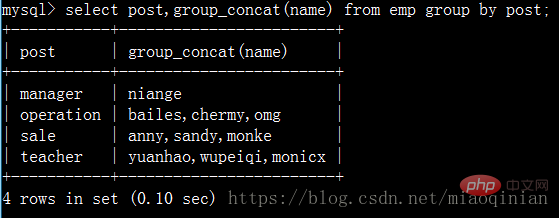
而且它还可以这样子使用:
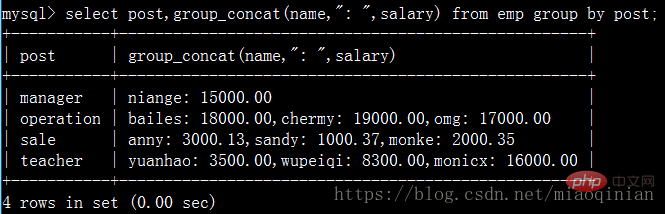
可以用下面的代码自己试一下吧:
select post,group_concat(name) from emp group by post; select post,group_concat(name,"_NB") from emp group by post; select post,group_concat(name,": ",salary) from emp group by post; select post,group_concat(salary) from emp group by post;
机智的同学会说那么不分组的情况下也能用它吗?不行!但是mysql提拱了另外的方式来操作。它就是concat。
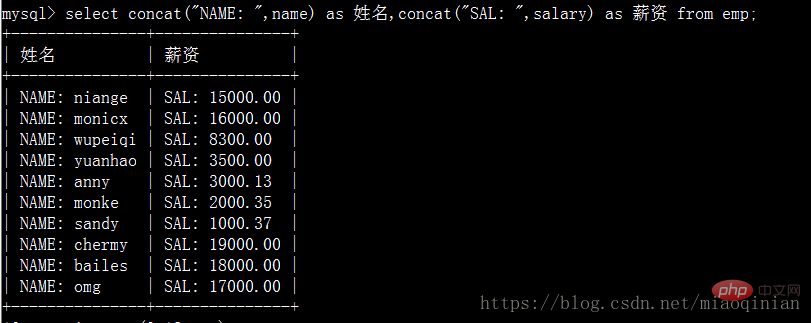
# 补充as语法
mysql> select emp.id,emp.name from emp as t1; # 报错
mysql> select t1.id,t1.name from emp as t1;group by 就说这些了,如果还不懂,可以作一下面的小练习。
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
8、统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age >= 30 group by post;having过滤
having的语法格式与where一模一样,只不过having是在分组之后进行的进一步过滤。
where不能用聚合函数,但having是可以用聚合函数,这也是它们最大的区别。
统计各部门年龄在24岁以上的员工平均工资,并且保留平均工资大于4000的部门。
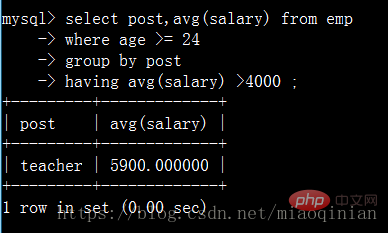
注意:having只能与 select 语句一起使用。
having通常在 group by 子句中使用。
如果不使用 group by子句,不会报错,但会出现以下的情况。

distinct去重
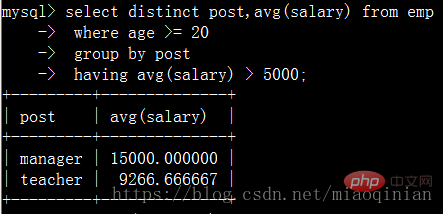
order by 排序
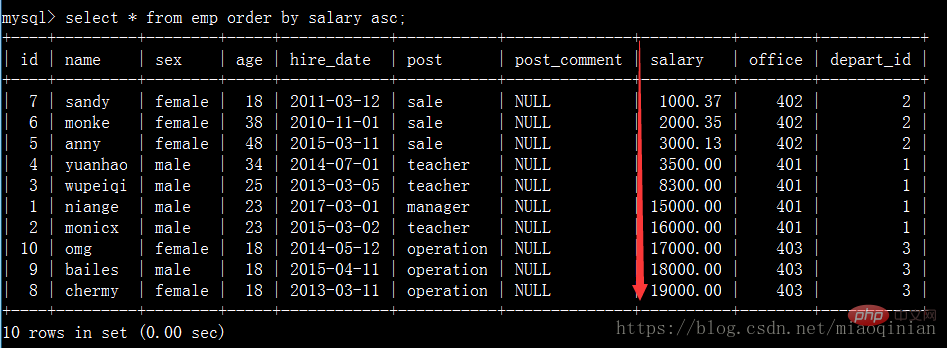
select * from emp order by salary asc; #默认升序排 select * from emp order by salary desc; #降序排 select * from emp order by age desc; #降序排 select * from emp order by age desc,salary asc; #先按照age降序排,再按照薪资升序排
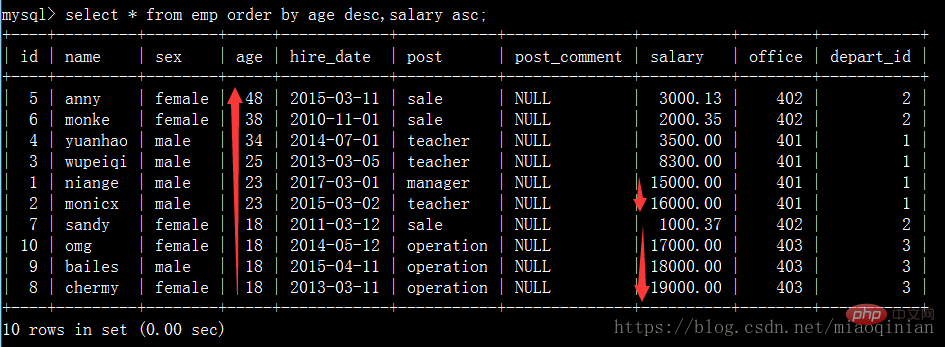
limit 限制显示条数

如查要获取工资最高的员工的信息,我们可以用order by和limit也可以做到。

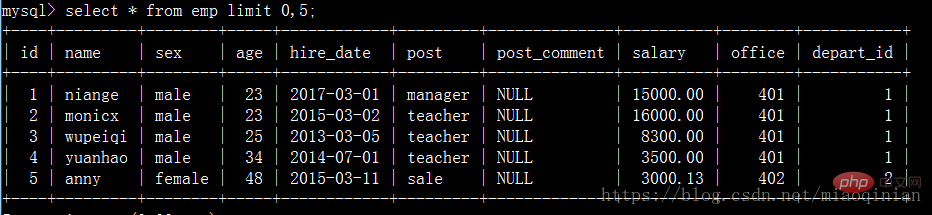
如果查一个表数据量大的话可以用limit分页显示。
select * from emp limit 0,5;
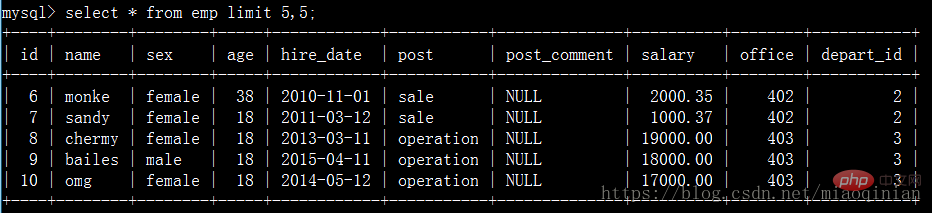
select * from emp limit 5,5;
ps:看到这里如果上面的东西你都明白的话,单表查询你基本上已经熟悉它了。
以上是单表查询是什么的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 说明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
说明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
InnoDB的全文搜索功能非常强大,能够显着提高数据库查询效率和处理大量文本数据的能力。 1)InnoDB通过倒排索引实现全文搜索,支持基本和高级搜索查询。 2)使用MATCH和AGAINST关键字进行搜索,支持布尔模式和短语搜索。 3)优化方法包括使用分词技术、定期重建索引和调整缓存大小,以提升性能和准确性。
 如何使用Alter Table语句在MySQL中更改表?
Mar 19, 2025 pm 03:51 PM
如何使用Alter Table语句在MySQL中更改表?
Mar 19, 2025 pm 03:51 PM
本文讨论了使用MySQL的Alter Table语句修改表,包括添加/删除列,重命名表/列以及更改列数据类型。
 与MySQL中使用索引相比,全表扫描何时可以更快?
Apr 09, 2025 am 12:05 AM
与MySQL中使用索引相比,全表扫描何时可以更快?
Apr 09, 2025 am 12:05 AM
全表扫描在MySQL中可能比使用索引更快,具体情况包括:1)数据量较小时;2)查询返回大量数据时;3)索引列不具备高选择性时;4)复杂查询时。通过分析查询计划、优化索引、避免过度索引和定期维护表,可以在实际应用中做出最优选择。
 可以在 Windows 7 上安装 mysql 吗
Apr 08, 2025 pm 03:21 PM
可以在 Windows 7 上安装 mysql 吗
Apr 08, 2025 pm 03:21 PM
是的,可以在 Windows 7 上安装 MySQL,虽然微软已停止支持 Windows 7,但 MySQL 仍兼容它。不过,安装过程中需要注意以下几点:下载适用于 Windows 的 MySQL 安装程序。选择合适的 MySQL 版本(社区版或企业版)。安装过程中选择适当的安装目录和字符集。设置 root 用户密码,并妥善保管。连接数据库进行测试。注意 Windows 7 上的兼容性问题和安全性问题,建议升级到受支持的操作系统。
 InnoDB中的聚类索引和非簇索引(次级索引)之间的差异。
Apr 02, 2025 pm 06:25 PM
InnoDB中的聚类索引和非簇索引(次级索引)之间的差异。
Apr 02, 2025 pm 06:25 PM
聚集索引和非聚集索引的区别在于:1.聚集索引将数据行存储在索引结构中,适合按主键查询和范围查询。2.非聚集索引存储索引键值和数据行的指针,适用于非主键列查询。
 哪些流行的MySQL GUI工具(例如MySQL Workbench,PhpMyAdmin)是什么?
Mar 21, 2025 pm 06:28 PM
哪些流行的MySQL GUI工具(例如MySQL Workbench,PhpMyAdmin)是什么?
Mar 21, 2025 pm 06:28 PM
文章讨论了流行的MySQL GUI工具,例如MySQL Workbench和PhpMyAdmin,比较了它们对初学者和高级用户的功能和适合性。[159个字符]

 如何使用Drop Table语句将表放入MySQL中?
Mar 19, 2025 pm 03:52 PM
如何使用Drop Table语句将表放入MySQL中?
Mar 19, 2025 pm 03:52 PM
本文讨论了使用Drop Table语句在MySQL中放下表,并强调了预防措施和风险。它强调,没有备份,该动作是不可逆转的,详细介绍了恢复方法和潜在的生产环境危害。
