

详解SQLServer中Partition By及row_number函数的使用


partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组。
今天群里看到一个问题,在这里概述下:查询出不同分类下的最新记录。一看这不是很简单的么,要分类那就用Group By;要最新记录就用Order By呗。然后在自己的表中试着做出来:
相关学习推荐:mysql视频教程
首先呢我把表中的数据按照提交时间倒序出来:
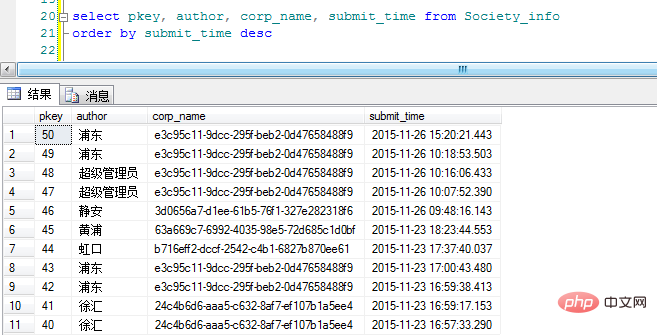
“corp_name”就是分类的GUID(请原谅我命名的随意性)。 OK, 这里按照最开始的想法加上Group By来看一下显示效果:
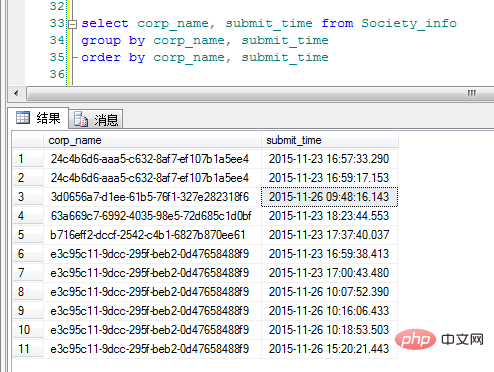
呃,嗯。这尼玛和想象中的结果不一样啊,看来写代码还是要理性分析问题,意念是无法控制结果滴!
既然要求是不同分类的数据,除了使用Group By之外,还有别的函数能用吗?度娘了一下结果还真有,over(partition by )函数,那么它和平时用的Group By有什么区别呢? Group By除了对结果进行单纯的分组之外呢,一般都和聚合函数一起使用,Partition By也具有分组功能,属于Oracle的分析函数,在这里就不详细的不啦不啦不啦了。
看代码:
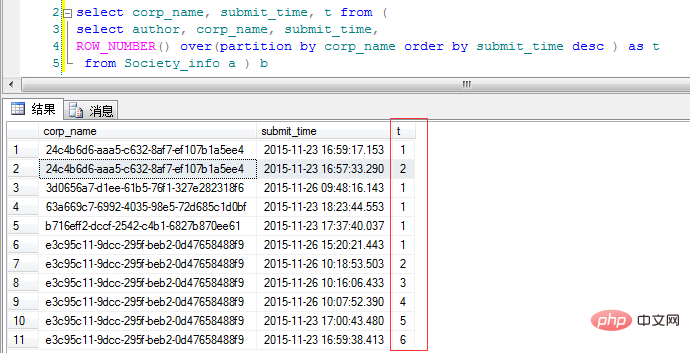
over(partition by corp_name order by submit_time desc ) as t 。就是按照corp_name分类并按时间倒序出来,"t" 这里一列呢就是不同corp_name类出现的次数,需求是只查询出不同分类的最新提交数据,那么我们只需要针对"t"再进行一次筛选即可:
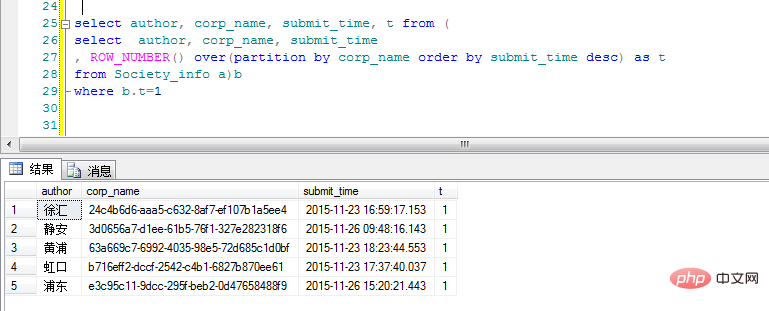
好啦,结果已经出来,不求各位看官喜欢,但求看在我头像中的胸器望点个赞, 好人一生平安哦!!!
ps:SQL Server数据库partition by 与ROW_NUMBER()函数使用详解
关于SQL的partition by 字段的一些用法心得
先看例子:
if object_id('TESTDB') is not null drop table TESTDB create table TESTDB(A varchar(8), B varchar(8)) insert into TESTDB select 'A1', 'B1' union all select 'A1', 'B2' union all select 'A1', 'B3' union all select 'A2', 'B4' union all select 'A2', 'B5' union all select 'A2', 'B6' union all select 'A3', 'B7' union all select 'A3', 'B3' union all select 'A3', 'B4'
-- 所有的信息
SELECT * FROM TESTDB A B ------- A1 B1 A1 B2 A1 B3 A2 B4 A2 B5 A2 B6 A3 B7 A3 B3 A3 B4
-- 使用PARTITION BY 函数后
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB A B NUM ------------- A1 B1 1 A1 B2 2 A1 B3 3 A2 B4 1 A2 B5 2 A2 B6 3 A3 B7 1 A3 B3 2 A3 B4 3
可以看到结果中多出一列NUM 这个NUM就是说明了相同行的个数,比如A1有3个,他就给每个A1标上是第几个。
-- 仅仅使用ROW_NUMBER() OVER的结果
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB A B NUM ------------------------ A3 B7 1 A3 B3 2 A3 B4 3 A2 B4 4 A2 B5 5 A2 B6 6 A1 B1 7 A1 B2 8 A1 B3 9
可以看到它只是单纯标出了行号。
-- 深入一点应用
SELECT A = CASE WHEN NUM = 1 THEN A ELSE '' END,B FROM (SELECT A,NUM = ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) FROM TESTDB) T A B --------- A1 B1 B2 B3 A2 B4 B5 B6 A3 B7 B3 B4
接下来我们就通过几个实例来一一介绍ROW_NUMBER()函数的使用。
实例如下:
1.使用row_number()函数进行编号,如
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理:先按psd进行排序,排序完后,给每条数据进行编号。
2.在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3.统计出每一个各户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样就知道每个客户下几单了。
如图:

代码如下:
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4.统计每一个客户最近下的订单是第几次下的订单。

代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
5.统计每一个客户所有的订单中购买的金额最小,而且并统计改订单中,客户是第几次购买的。
如图:

上图:rows表示客户是第几次购买。
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,customerID,totalPrice, DID from OP_Order ) select * from tabs where totalPrice in ( select MIN(totalPrice)from tabs group by customerID )
6.筛选出客户第一次下的订单。

思路。利用rows=1来查询客户第一次下的订单记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order ) select * from tabs where rows = 1 select * from OP_Order
7.rows_number()可用于分页
思路:先把所有的产品筛选出来,然后对这些产品进行编号。然后在where子句中进行过滤。
8.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
如下代码:
select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID,totalPrice, DID from OP_Order where insDT>'2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录进行编号。
以上是详解SQLServer中Partition By及row_number函数的使用的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 说明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
说明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
InnoDB的全文搜索功能非常强大,能够显着提高数据库查询效率和处理大量文本数据的能力。 1)InnoDB通过倒排索引实现全文搜索,支持基本和高级搜索查询。 2)使用MATCH和AGAINST关键字进行搜索,支持布尔模式和短语搜索。 3)优化方法包括使用分词技术、定期重建索引和调整缓存大小,以提升性能和准确性。
 如何使用Alter Table语句在MySQL中更改表?
Mar 19, 2025 pm 03:51 PM
如何使用Alter Table语句在MySQL中更改表?
Mar 19, 2025 pm 03:51 PM
本文讨论了使用MySQL的Alter Table语句修改表,包括添加/删除列,重命名表/列以及更改列数据类型。
 与MySQL中使用索引相比,全表扫描何时可以更快?
Apr 09, 2025 am 12:05 AM
与MySQL中使用索引相比,全表扫描何时可以更快?
Apr 09, 2025 am 12:05 AM
全表扫描在MySQL中可能比使用索引更快,具体情况包括:1)数据量较小时;2)查询返回大量数据时;3)索引列不具备高选择性时;4)复杂查询时。通过分析查询计划、优化索引、避免过度索引和定期维护表,可以在实际应用中做出最优选择。
 可以在 Windows 7 上安装 mysql 吗
Apr 08, 2025 pm 03:21 PM
可以在 Windows 7 上安装 mysql 吗
Apr 08, 2025 pm 03:21 PM
是的,可以在 Windows 7 上安装 MySQL,虽然微软已停止支持 Windows 7,但 MySQL 仍兼容它。不过,安装过程中需要注意以下几点:下载适用于 Windows 的 MySQL 安装程序。选择合适的 MySQL 版本(社区版或企业版)。安装过程中选择适当的安装目录和字符集。设置 root 用户密码,并妥善保管。连接数据库进行测试。注意 Windows 7 上的兼容性问题和安全性问题,建议升级到受支持的操作系统。
 如何为MySQL连接配置SSL/TLS加密?
Mar 18, 2025 pm 12:01 PM
如何为MySQL连接配置SSL/TLS加密?
Mar 18, 2025 pm 12:01 PM
文章讨论了为MySQL配置SSL/TLS加密,包括证书生成和验证。主要问题是使用自签名证书的安全含义。[角色计数:159]
 哪些流行的MySQL GUI工具(例如MySQL Workbench,PhpMyAdmin)是什么?
Mar 21, 2025 pm 06:28 PM
哪些流行的MySQL GUI工具(例如MySQL Workbench,PhpMyAdmin)是什么?
Mar 21, 2025 pm 06:28 PM
文章讨论了流行的MySQL GUI工具,例如MySQL Workbench和PhpMyAdmin,比较了它们对初学者和高级用户的功能和适合性。[159个字符]
 InnoDB中的聚类索引和非簇索引(次级索引)之间的差异。
Apr 02, 2025 pm 06:25 PM
InnoDB中的聚类索引和非簇索引(次级索引)之间的差异。
Apr 02, 2025 pm 06:25 PM
聚集索引和非聚集索引的区别在于:1.聚集索引将数据行存储在索引结构中,适合按主键查询和范围查询。2.非聚集索引存储索引键值和数据行的指针,适用于非主键列查询。

