

Python爬取51cto数据并存入MySQL方法详解


【相关学习推荐:python教程】
实验环境
1.安装Python 3.7
2.安装requests, bs4,pymysql 模块
实验步骤1.安装环境及模块
可参考https://www.jb51.net/article/194104.htm
2.编写代码
# 51cto 博客页面数据插入mysql数据库
# 导入模块
import re
import bs4
import pymysql
import requests
# 连接数据库账号密码
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客名
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置顶" in each:
each = each.split(' ')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 语句
sql = """insert into blog (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替换页面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
comment = re.sub('\s', '', comment)
collects = re.sub('\s', '', collects)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
if __name__ == '__main__':
main()3..MySQL创建对应的表
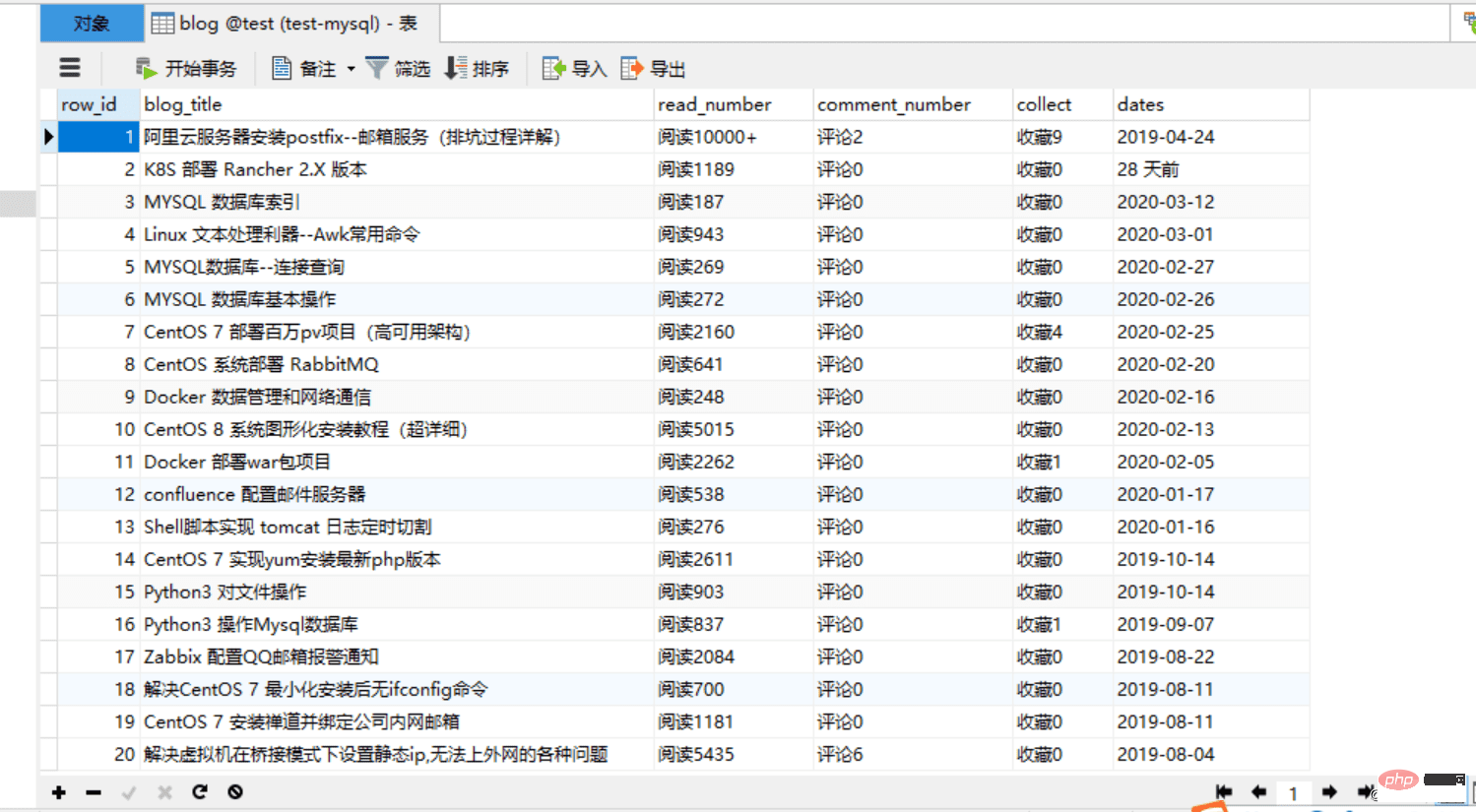
CREATE TABLE `blog` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客标题', `read_number` varchar(26) DEFAULT NULL COMMENT '阅读数量', `comment_number` varchar(16) DEFAULT NULL COMMENT '评论数量', `collect` varchar(16) DEFAULT NULL COMMENT '收藏数量', `dates` varchar(16) DEFAULT NULL COMMENT '发布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

4.运行代码,查看效果:
改进版:
改进内容:
1.数据库里面的某些字段只保留数字即可
2.默认爬取的内容都是字符串,存放数据库的某些字段,最好改为整型,方便后面数据库操作
1.代码如下:
import re
import bs4
import pymysql
import requests
# 连接数据库
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客标题
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置顶" in each:
each = each.split(' ')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 语句
sql = """insert into blogs (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替换页面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
reads=int(re.sub('\D', "", reads)) #匹配数字,转换为整型
comment = re.sub('\s', '', comment)
comment = int(re.sub('\D', "", comment)) #匹配数字,转换为整型
collects = re.sub('\s', '', collects)
collects = int(re.sub('\D', "", collects)) #匹配数字,转换为整型
dates = re.sub('\s', '', dates)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
#主程序入口
if __name__ == '__main__':
main()2.创建对应表
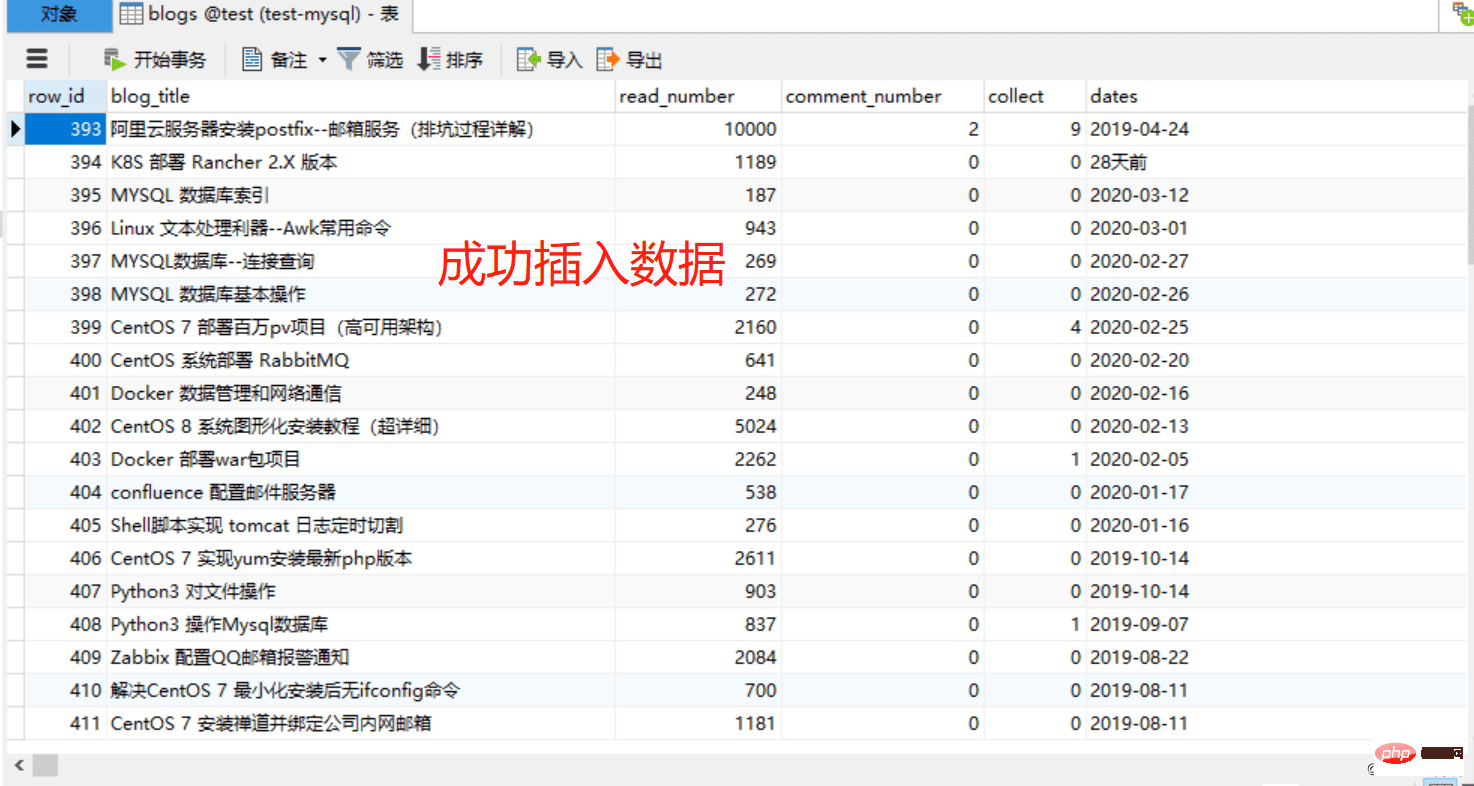
CREATE TABLE `blogs` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客标题', `read_number` int(26) DEFAULT NULL COMMENT '阅读数量', `comment_number` int(16) DEFAULT NULL COMMENT '评论数量', `collect` int(16) DEFAULT NULL COMMENT '收藏数量', `dates` varchar(16) DEFAULT NULL COMMENT '发布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
3.运行代码,验证
升级版
为了能让小白就可以使用这个程序,可以把这个项目打包成exe格式的文件,让其他人,使用电脑就可以运行代码,这样非常方便!
1.改进代码:
#末尾修改为:
if __name__ == '__main__':
main()
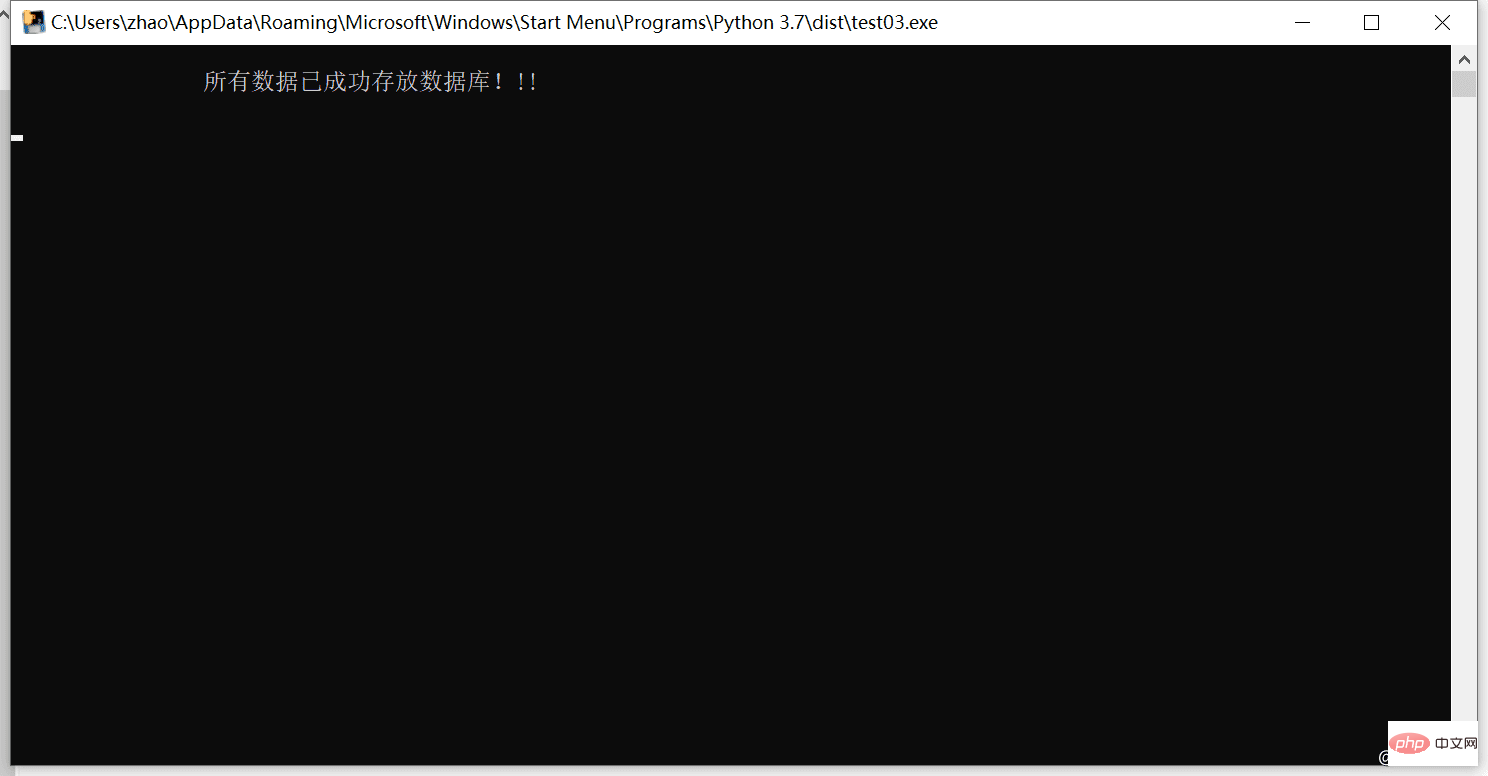
print("\n\t\t所有数据已成功存放数据库!!! \n")
time.sleep(5)2.安装打包模块pyinstaller(cmd安装)
pip install pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/
3.Python代码打包
1.切换到需要打包代码的路径下面
2.在cmd窗口运行 pyinstaller -F test03.py (test03为项目名称)
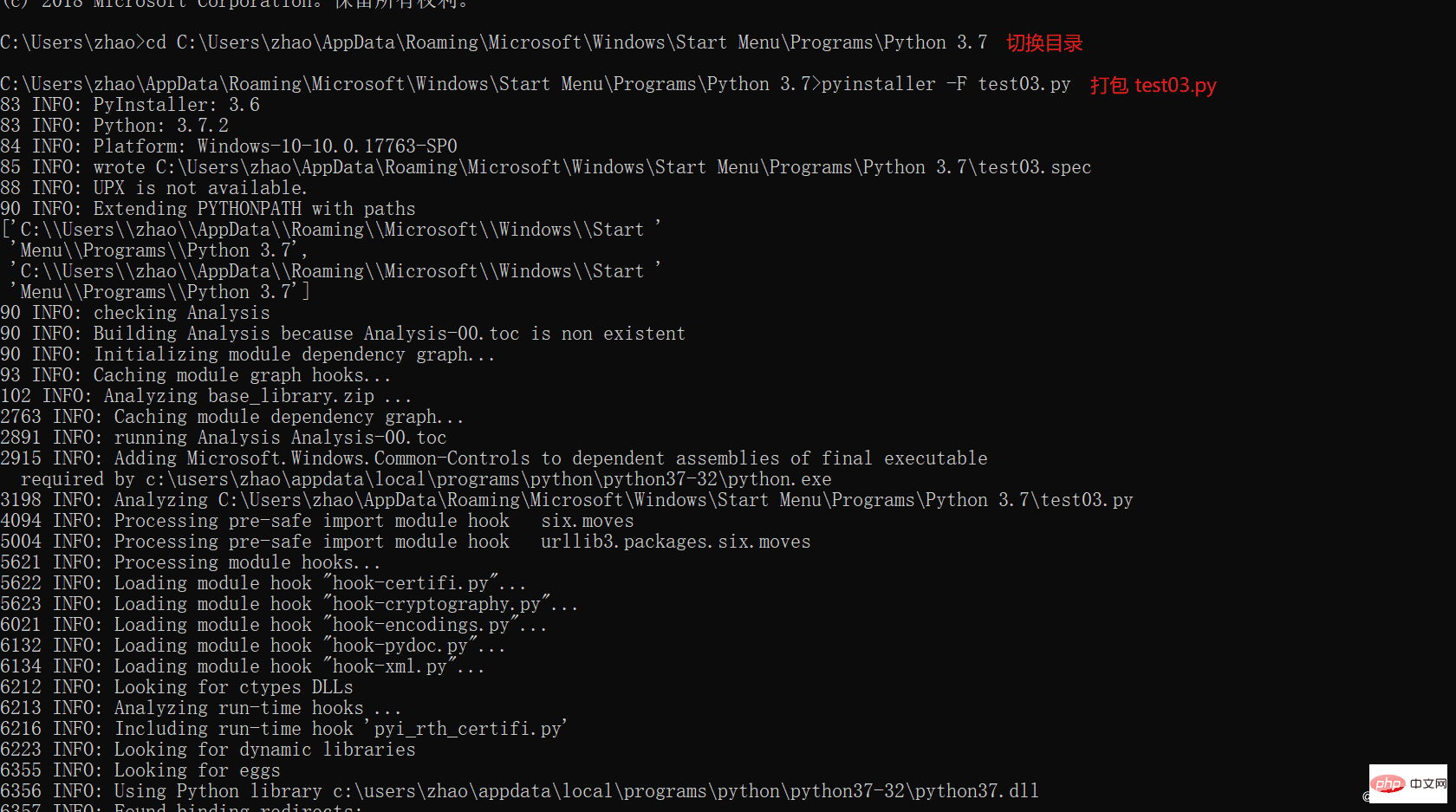
4.查看exe包
在打包后会出现dist目录,打好包就在这个目录里面

5.运行exe包,查看效果
检查数据库
相关学习推荐:mysql教程
以上是Python爬取51cto数据并存入MySQL方法详解的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题
 7651
7651
 15
1392
52
91
11
73
19
36
110
15
1392
52
91
11
73
19
36
110

 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL在Web应用中的主要作用是存储和管理数据。1.MySQL高效处理用户信息、产品目录和交易记录等数据。2.通过SQL查询,开发者能从数据库提取信息生成动态内容。3.MySQL基于客户端-服务器模型工作,确保查询速度可接受。
 PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
 notepad 怎么运行python
Apr 16, 2025 pm 07:33 PM
notepad 怎么运行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中运行 Python 代码需要安装 Python 可执行文件和 NppExec 插件。安装 Python 并为其添加 PATH 后,在 NppExec 插件中配置命令为“python”、参数为“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通过快捷键“F6”运行 Python 代码。
 解决数据库连接问题:使用minii/db库的实际案例
Apr 18, 2025 am 07:09 AM
解决数据库连接问题:使用minii/db库的实际案例
Apr 18, 2025 am 07:09 AM
在开发一个小型应用时,我遇到了一个棘手的问题:需要快速集成一个轻量级的数据库操作库。尝试了多个库后,我发现它们要么功能过多,要么兼容性不佳。最终,我找到了minii/db,这是一个基于Yii2的简化版本,完美地解决了我的问题。
 laravel入门实例
Apr 18, 2025 pm 12:45 PM
laravel入门实例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用于轻松构建 Web 应用程序。它提供一系列强大的功能,包括:安装: 使用 Composer 全局安装 Laravel CLI,并在项目目录中创建应用程序。路由: 在 routes/web.php 中定义 URL 和处理函数之间的关系。视图: 在 resources/views 中创建视图以呈现应用程序的界面。数据库集成: 提供与 MySQL 等数据库的开箱即用集成,并使用迁移来创建和修改表。模型和控制器: 模型表示数据库实体,控制器处理 HTTP 请求。
 Golang vs. Python:并发和多线程
Apr 17, 2025 am 12:20 AM
Golang vs. Python:并发和多线程
Apr 17, 2025 am 12:20 AM
Golang更适合高并发任务,而Python在灵活性上更有优势。1.Golang通过goroutine和channel高效处理并发。2.Python依赖threading和asyncio,受GIL影响,但提供多种并发方式。选择应基于具体需求。
