

Redis6.0到底为何引入多线程?

下面由Redis教程栏目给大家介绍Redis6.0到底为何引入多线程?,希望对需要的朋友有所帮助!

作者简介:曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监。15年电商互联网经历。
一百天前Redis作者antirez在博客上(antirez.com)发布了一条重磅消息,Redis6.0正式发布了。其中最引人注目的改动就是,Redis6.0引入了多线程。
本文主要分两部分。首先我们先聊一下Redis6.0之前为什么采用单线程模型。然后再详细解释Redis6.0的多线程。

Redis6.0之前为什么采用单线程模型
严格地说,从Redis 4.0之后并不是单线程。除了主线程外,还有一些后台线程处理一些较为缓慢的操作,例如无用连接的释放、大 key 的删除等等。
单线程模型,为何性能那么高?
Redis作者从设计之初,进行了多方面的考虑。最终选择使用单线程模型来处理命令。之所以选择单线程模型,主要有如下几个重要原因:
Redis操作基于内存,绝大多数操作的性能瓶颈不在CPU
单线程模型,避免了线程间切换带来的性能开销
使用单线程模型也能并发的处理客户端的请求(多路复用I/O)
使用单线程模型,可维护性更高,开发,调试和维护的成本更低
上述第三个原因是Redis最终采用单线程模型的决定性因素,其他的两个原因都是使用单线程模型额外带来的好处,在这里我们会按顺序介绍上述的几个原因。
性能瓶颈不在CPU
下图是Redis官网对单线程模型的说明。大概意思是:Redis的瓶颈并不在CPU,它的主要瓶颈在于内存和网络。在Linux环境中,Redis每秒甚至可以提交100万次请求。

为什么说Redis的瓶颈不在CPU?
首先,Redis绝大部分操作是基于内存的,而且是纯kv(key-value)操作,所以命令执行速度非常快。我们可以大概理解成,redis中的数据存储在一张大HashMap中,HashMap的优势就是查找和写入的时间复杂度都是O(1)。Redis内部采用这种结构存储数据,就奠定了Redis高性能的基础。根据Redis官网描述,在理想情况下Redis每秒可以提交一百万次请求,每次请求提交所需的时间在纳秒的时间量级。既然每次的Redis操作都这么快,单线程就可以完全搞定了,那还何必要用多线程呢!
线程上下文切换问题
另外,多线程场景下会发生线程上下文切换。线程是由CPU调度的,CPU的一个核在一个时间片内只能同时执行一个线程,在CPU由线程A切换到线程B的过程中会发生一系列的操作,主要过程包括保存线程A的执行现场,然后载入线程B的执行现场,这个过程就是“线程上下文切换”。其中涉及线程相关指令的保存和恢复。
频繁的线程上下文切换可能会导致性能急剧下降,这会导致我们不仅没有提升处理请求的速度,反而降低了性能,这也是 Redis 对于多线程技术持谨慎态度的原因之一。
在Linux系统中可以使用vmstat命令来查看上下文切换的次数,下面是vmstat查看上下文切换次数的示例:
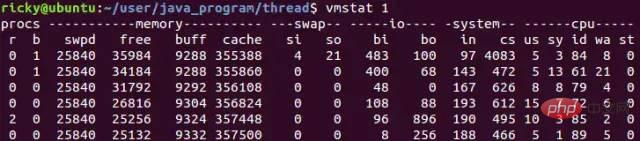 vmstat 1 表示每秒统计一次, 其中cs列就是指上下文切换的数目. 一般情况下, 空闲系统的上下文切换每秒在1500以下。
vmstat 1 表示每秒统计一次, 其中cs列就是指上下文切换的数目. 一般情况下, 空闲系统的上下文切换每秒在1500以下。
并行处理客户端的请求(I/O多路复用)
如上所述:Redis的瓶颈并不在CPU,它的主要瓶颈在于内存和网络。所谓内存瓶颈很好理解,Redis做为缓存使用时很多场景需要缓存大量数据,所以需要大量内存空间,这可以通过集群分片去解决,例如Redis自身的无中心集群分片方案以及Codis这种基于代理的集群分片方案。
对于网络瓶颈,Redis在网络I/O模型上采用了多路复用技术,来减少网络瓶颈带来的影响。很多场景中使用单线程模型并不意味着程序不能并发的处理任务。Redis 虽然使用单线程模型处理用户的请求,但是它却使用 I/O 多路复用技术“并行”处理来自客户端的多个连接,同时等待多个连接发送的请求。使用 I/O多路复用技术能极大地减少系统的开销,系统不再需要为每个连接创建专门的监听线程,避免了由于大量的线程创建带来的巨大性能开销。
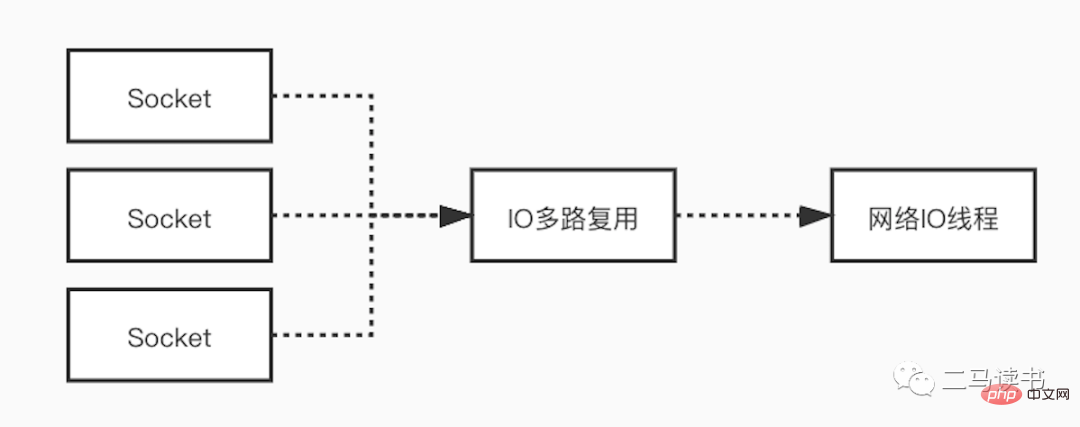
下面我们详细解释一下多路复用I/O模型。为了能更充分理解,我们先了解几个基本概念。
Socket(套接字):Socket可以理解成,在两个应用程序进行网络通信时,分别在两个应用程序中的通信端点。通信时,一个应用程序将数据写入Socket,然后通过网卡把数据发送到另外一个应用程序的Socket中。我们平常所说的HTTP和TCP协议的远程通信,底层都是基于Socket实现的。5种网络IO模型也都要基于Socket实现网络通信。
阻塞与非阻塞:所谓阻塞,就是发出一个请求不能立刻返回响应,要等所有的逻辑全处理完才能返回响应。非阻塞反之,发出一个请求立刻返回应答,不用等处理完所有逻辑。
内核空间与用户空间:在Linux中,应用程序稳定性远远比不上操作系统程序,为了保证操作系统的稳定性,Linux区分了内核空间和用户空间。可以这样理解,内核空间运行操作系统程序和驱动程序,用户空间运行应用程序。Linux以这种方式隔离了操作系统程序和应用程序,避免了应用程序影响到操作系统自身的稳定性。这也是Linux系统超级稳定的主要原因。所有的系统资源操作都在内核空间进行,比如读写磁盘文件,内存分配和回收,网络接口调用等。所以在一次网络IO读取过程中,数据并不是直接从网卡读取到用户空间中的应用程序缓冲区,而是先从网卡拷贝到内核空间缓冲区,然后再从内核拷贝到用户空间中的应用程序缓冲区。对于网络IO写入过程,过程则相反,先将数据从用户空间中的应用程序缓冲区拷贝到内核缓冲区,再从内核缓冲区把数据通过网卡发送出去。
多路复用I/O模型,建立在多路事件分离函数select,poll,epoll之上。以Redis采用的epoll为例,在发起read请求前,先更新epoll的socket监控列表,然后等待epoll函数返回(此过程是阻塞的,所以说多路复用IO本质上也是阻塞IO模型)。当某个socket有数据到达时,epoll函数返回。此时用户线程才正式发起read请求,读取并处理数据。这种模式用一个专门的监视线程去检查多个socket,如果某个socket有数据到达就交给工作线程处理。由于等待Socket数据到达过程非常耗时,所以这种方式解决了阻塞IO模型一个Socket连接就需要一个线程的问题,也不存在非阻塞IO模型忙轮询带来的CPU性能损耗的问题。多路复用IO模型的实际应用场景很多,大家耳熟能详的Redis,Java NIO,以及Dubbo采用的通信框架Netty都采用了这种模型。
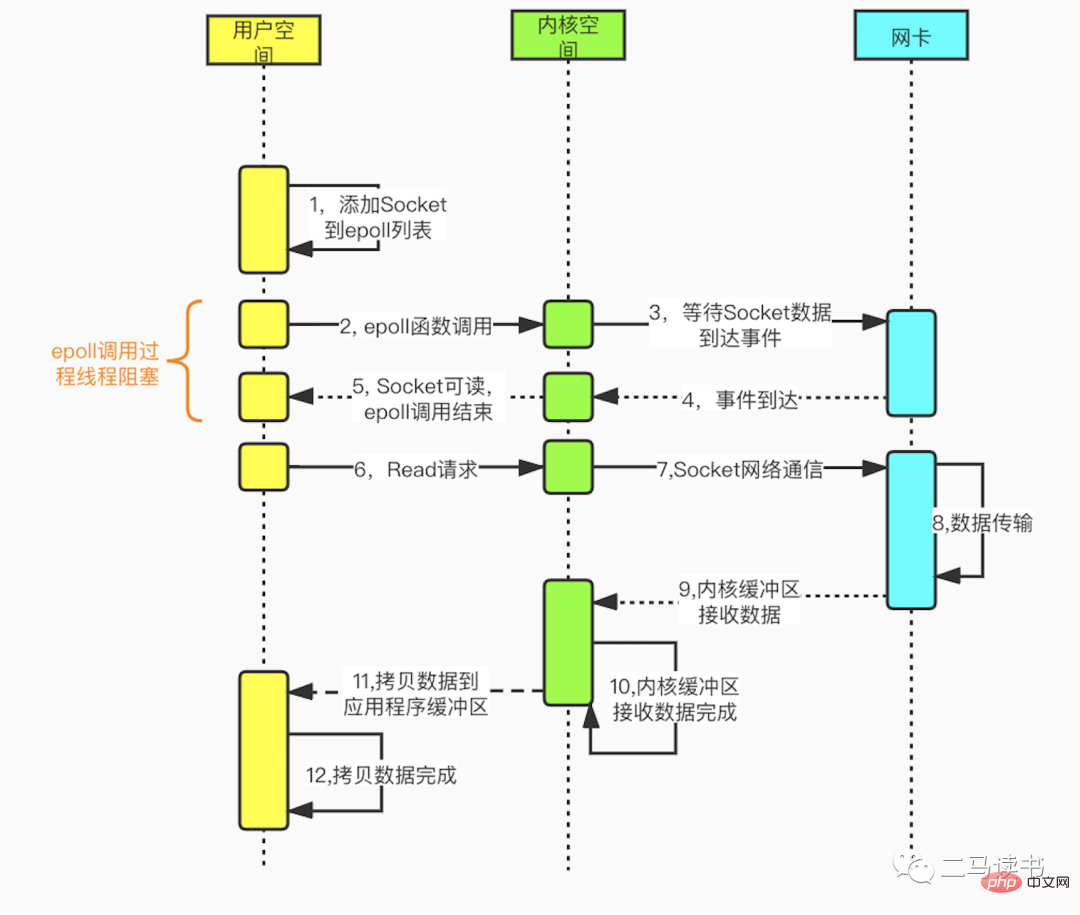
下图是基于epoll函数Socket编程的详细流程。
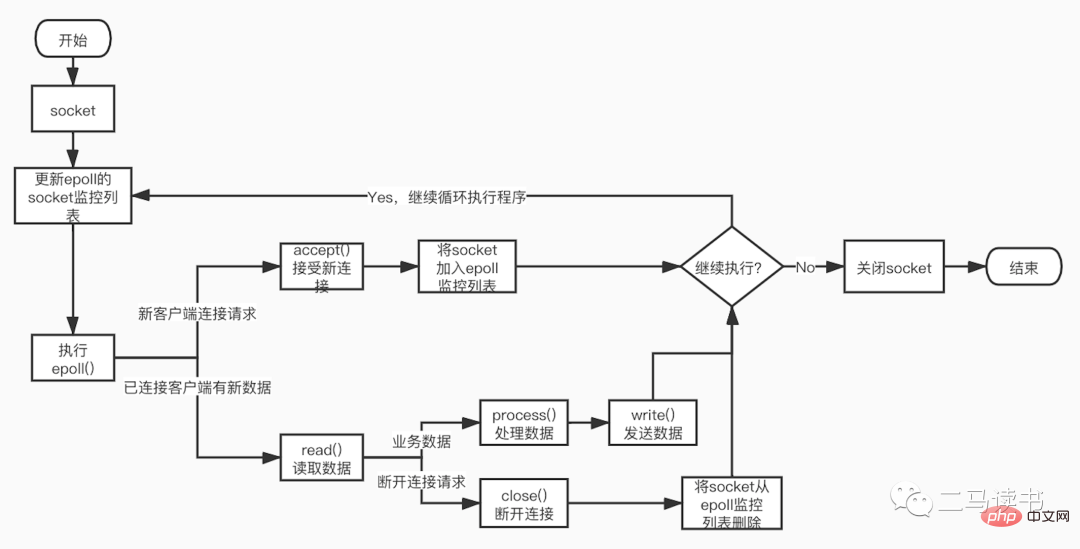
可维护性
我们知道,多线程可以充分利用多核CPU,在高并发场景下,能够减少因I/O等待带来的CPU损耗,带来很好的性能表现。不过多线程却是一把双刃剑,带来好处的同时,还会带来代码维护困难,线上问题难于定位和调试,死锁等问题。多线程模型中代码的执行过程不再是串行的,多个线程同时访问的共享变量如果处理不当也会带来诡异的问题。
我们通过一个例子,看一下多线程场景下发生的诡异现象。看下面的代码:
class MemoryReordering {
int num = 0;
boolean flag = false;
public void set() {
num = 1; //语句1
flag = true; //语句2
}
public int cal() {
if( flag == true) { //语句3
return num + num; //语句4
}
return -1;
}
}flag为true时,cal() 方法返回值是多少?很多人会说:这还用问吗!肯定返回2
结果可能会让你大吃一惊!上面的这段代码,由于语句1和语句2没有数据依赖性,可能会发生指令重排序,有可能编译器会把flag=true放到num=1的前面。此时set和cal方法分别在不同线程中执行,没有先后关系。cal方法,只要flag为true,就会进入if的代码块执行相加的操作。可能的顺序是:
语句1先于语句2执行,这时的执行顺序可能是:语句1->语句2->语句3->语句4。执行语句4前,num = 1,所以cal的返回值是2
语句2先于语句1执行,这时的执行顺序可能是:语句2->语句3->语句4->语句1。执行语句4前,num = 0,所以cal的返回值是0
我们可以看到,在多线程环境下如果发生了指令重排序,会对结果造成严重影响。
当然可以在第三行处,给flag加上关键字volatile来避免指令重排。即在flag处加上了内存栅栏,来阻隔flag(栅栏)前后的代码的重排序。当然多线程还会带来可见性问题,死锁问题以及共享资源安全等问题。
boolean volatile flag = false;
Redis6.0为何引入多线程?
Redis6.0引入的多线程部分,实际上只是用来处理网络数据的读写和协议解析,执行命令仍然是单一工作线程。
从上图我们可以看到Redis在处理网络数据时,调用epoll的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,达到几万的QPS,此处可能会成为瓶颈。一般我们遇到此类网络IO瓶颈的问题,可以增加线程数来解决。开启多线程除了可以减少由于网络I/O等待造成的影响,还可以充分利用CPU的多核优势。Redis6.0也不例外,在此处增加了多线程来处理网络数据,以此来提高Redis的吞吐量。当然相关的命令处理还是单线程运行,不存在多线程下并发访问带来的种种问题。
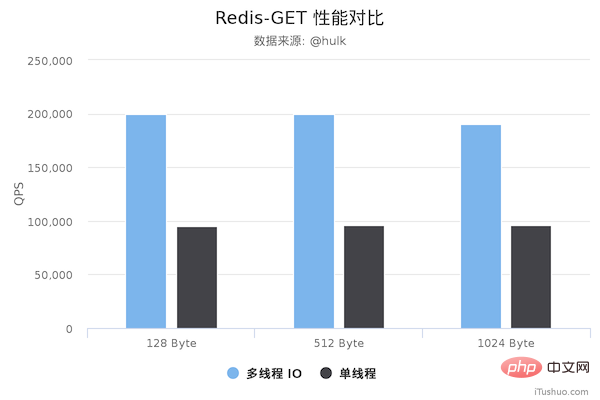
性能对比
压测配置:
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlarge Redis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge
多线程版本Redis 6.0,单线程版本是 Redis 5.0.5。多线程版本需要新增以下配置:
io-threads 4 # 开启 4 个 IO 线程 io-threads-do-reads yes # 请求解析也是用 IO 线程
压测命令: redis-benchmark -h 192.168.0.49 -a foobared -t set,get -n 1000000 -r 100000000 --threads 4 -d ${datasize} -c 256
图片来源于网络 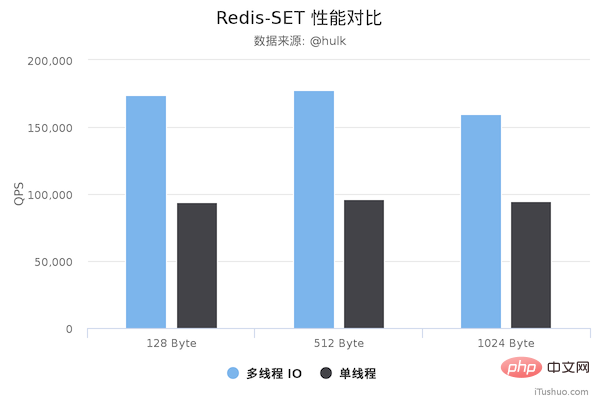
图片来源于网络
从上面可以看到 GET/SET 命令在多线程版本中性能相比单线程几乎翻了一倍。另外,这些数据只是为了简单验证多线程 I/O 是否真正带来性能优化,并没有针对具体的场景进行压测,数据仅供参考。本次性能测试基于 unstble 分支,不排除后续发布的正式版本的性能会更好。
最后
可见单线程有单线程的好处,多线程有多线程的优势,只有充分理解其中的本质原理,才能灵活运用于生产实践当中。
以上是Redis6.0到底为何引入多线程?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何在Redis群集中选择一个碎片键?
Mar 17, 2025 pm 06:55 PM
如何在Redis群集中选择一个碎片键?
Mar 17, 2025 pm 06:55 PM
本文讨论了在Redis群集中选择碎片键,并强调了它们对性能,可伸缩性和数据分布的影响。关键问题包括确保均匀数据分配,与访问模式保持一致以及避免常见错误l
 如何在Redis中实施身份验证和授权?
Mar 17, 2025 pm 06:57 PM
如何在Redis中实施身份验证和授权?
Mar 17, 2025 pm 06:57 PM
本文讨论了在REDIS中实施身份验证和授权,重点是实现身份验证,使用ACL以及确保REDIS的最佳实践。它还涵盖了管理用户权限和工具以增强重新安全性。
 如何将Redis用于工作队列和背景处理?
Mar 17, 2025 pm 06:51 PM
如何将Redis用于工作队列和背景处理?
Mar 17, 2025 pm 06:51 PM
本文讨论了使用REDIS进行工作队列和背景处理,详细的设置,作业定义和执行。它涵盖了原子运营和工作优先级等最佳实践,并解释了REDIS如何提高处理效率。
 如何在REDIS中实施缓存无效策略?
Mar 17, 2025 pm 06:46 PM
如何在REDIS中实施缓存无效策略?
Mar 17, 2025 pm 06:46 PM
本文讨论了在REDIS中实施和管理缓存无效的策略,包括基于时间的到期,事件驱动的方法和版本控制。它还涵盖了缓存到期的最佳实践和监视和自动的工具
 如何监视REDIS群集的性能?
Mar 17, 2025 pm 06:56 PM
如何监视REDIS群集的性能?
Mar 17, 2025 pm 06:56 PM
文章讨论了使用Redis CLI,Redis Insight和Datadog和Prometheus等工具等工具进行监视REDIS群集的性能和健康。

 如何在Web应用程序中使用REDI进行会话管理?
Mar 17, 2025 pm 06:47 PM
如何在Web应用程序中使用REDI进行会话管理?
Mar 17, 2025 pm 06:47 PM
本文讨论了在Web应用程序中使用REDIS进行会话管理,详细介绍设置,诸如可伸缩性和性能以及安全措施之类的好处。

