

终于来了...RocketMQ扫盲篇

java基础教程栏目今天详细介绍有关RocketMQ知识。

又是好久没有写博客了,虽然可以找出无数个没有写的博客的理由,但是说到底,还是一个字“懒”。今天我终于吃了一颗治疗懒癌的药丸,决定写一篇博客。介绍什么好呢,思来想去,还是介绍下RocketMQ吧,毕竟写了30多篇博客,还没有好好写过关于MQ的博客呢。本篇博客比较基础,不涉及到源码分析,只是扫盲。
MQ有什么用
解耦
我觉得从某种角度来说,微服务促进了MQ的蓬勃发展,本来一个系统有N多个模块,所有模块都强耦合在一起,现在微服务了,一个模块就是一个系统,系统之间肯定需要交互,交互有三种常见的方法,一种是RPC,一种是HTTP,一种就是MQ了。
异步
原本一个业务分为N步,要一步一步处理,才能把最终的结果返回给用户,现在有了MQ,先把最关键的部分处理完毕,然后发送消息到MQ,直接返回给用户OK,至于后面的步骤在后台慢慢处理吧,真乃提升用户体验的神器。
削峰
某个接口的请求量突然飙升,势必会对应用服务器、数据库服务器造成很大的压力,现在有了MQ,来多少请求都不在怕的,后台慢慢处理呗。
RocketMQ简介
RocketMQ是用Java编写的,是阿里开源的消息中间件,吸收了Kafka很多优点。Kafka也是比较热门的消息中间件,不过Kafka是用Scala编写的,不利于Java程序员去阅读源码,也不利于Java程序员做一些定制化的开发。接触过Kafka的小伙伴都知道,要用好Kafka实属不易,相对来说,RocketMQ简单多了,而且RocketMQ有阿里加持,经历了N次双11的考验,比较适合国内互联网公司,所以国内使用RocketMQ的公司很多。
RocketMQ四大组件
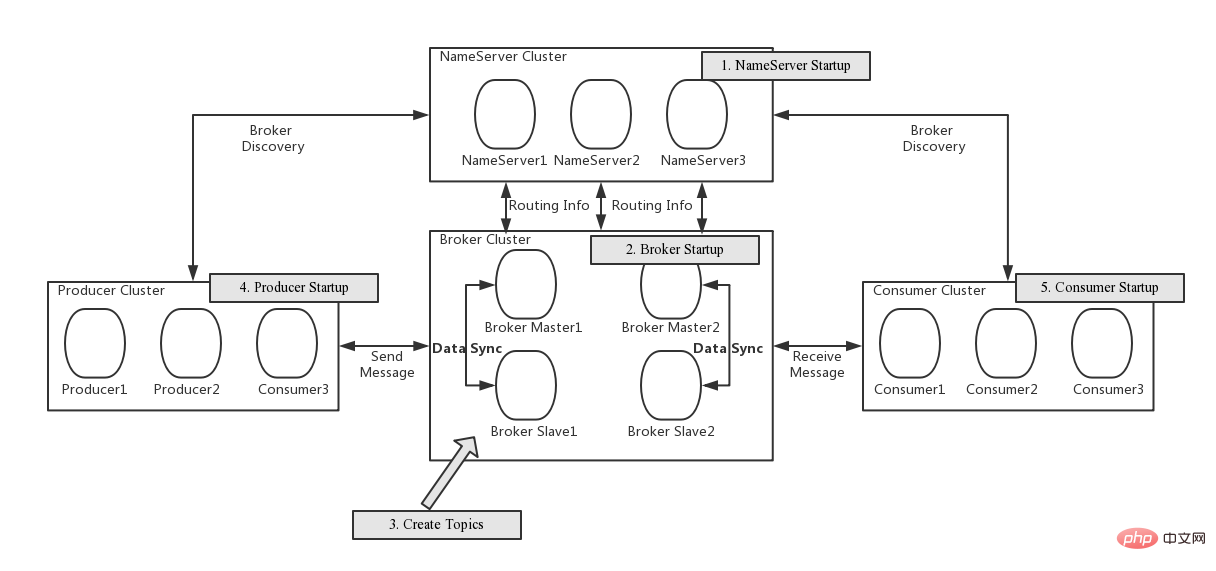 图片来自gitee.com/mirrors/roc…
图片来自gitee.com/mirrors/roc…
可以看到RocketMQ主要有四个组件:
NameServer
- 无状态服务,注册中心,可集群部署,但是NameServer节点之间没有任何数据交互。
- Borker会以定时把Topic路由信息上报给所有的NameServer。Producer、Consumer会随机选择一个NameServer定时Topic更新路由信息。
- Topic路由信息在NameServer集群中采用最终一致性。
- 保证AP。
Borker
- RocketMQ的服务端,用于存储消息、分发消息。
- Borker会定时把自身拥有的所有的Topic路由信息上报给NameServer。
- Borker有两个角色:Master、Follower,Master承担读(消费消息)写(生产消息)操作,如果Master比较忙,或者不可用,Follower可以承担读操作。BorkerId=0,代表是Matser,BorkerId!=0,代表是Follower,需要注意的有两点: 其一,目前为止,BorkerId=1的Follower才可以承担读操作; 其二,只有较高版本的RocketMQ才支持当Master节点挂掉,Follower自动升级到Master。
Producer
生产者,每隔一定时间向NameServer发起Topic的路由信息查询。
Consumer
消费者,每隔一定时间向NameServer发起Topic的路由信息查询。
为什么注册中心不选用Zookeeper
其实,在低版本的RocketMQ中,确实是选用Zookeeper作为注册中心的,但是后面改成了现在的NameServer,猜想主要原因是:
- RocketMQ已经是一个中间件了,不想再依赖其他中间件。
- Zookeeper比较重,有很多功能RocketMQ是用不到的,不如写一个轻量级的注册中心。
- Zookeeper是CP,一旦触发领导选举,那么注册中心就不可用了,而RocketMQ的注册中心,不需要强一致性,只要保证最终一致性。
RocketMQ消息领域模型
Message
- 传输的消息。
- 消息必须有Topic。
- 消息可以有多个Tag和多个Key,可以看做消息的附加属性。
Topic
- 一类消息的集合。
- 每个消息必须有一个Topic。
- 消息的第一级类型。
Tag
- 一个消息除了有Topic之外,还可以有Tag,用来细分同一个Topic下的不同种类的消息。
- Tag不是必须的。
- 消息的第二级类型。
Group
分为ProducerGroup,ConsumerGroup,我们更多的是关注ConsumerGroup,ConsumerGroup包含多个Consumer。
在集群消费模式下,一个ConsumerGroup下的Consumer共同消费一个Topic,且每个Consumer会被分配到N个队列,但是一个队列只会被一个Consumer消费,不同的ConsumerGroup可以消费同一个Topic,一条消息会被订阅此Topic的所有ConsumerGroup消费。
Queue
- 一个Topic默认包含四个Queue。
- 在集群消费模式下,同一个ConsumerGroup中的Consumer可以消费多个Queue的消息,但是一个Queue只能被一个Consumer消费。
- Queue中的消息是有序的。
- 分为读Queue和写Queue,一般来说,读Queue的数量和写Queue的数量是一致的,否则很容易出问题。
消费模式
消费模式有两种:Clustering(集群消费)和Broadcasting(广播消费)。
和其他MQ不同,其他MQ是在发送消息的时候,指定是集群消费还是广播消费,RocketMQ是在消费者端设置是集群消费还是广播消费。
Clustering(集群消费)
默认情况下是集群消费模式,该模式下,ConsumerGroup所有的Consumer共同消费一个Topic的消息,每个Consumer负责消费N个队列的消息(N也可能为1,甚至是0,没有分配到队列),但是一个队列只会被一个Consumer消费。如果某个Consumer挂掉,ConsumerGroup下的其他Consumer会接替挂掉的Consumer继续消费。
集群消费模式下,消费进度维护在Borker端,存储路径为${ROCKET_HOME}/store/config/ consumerOffset.json,如下图所示: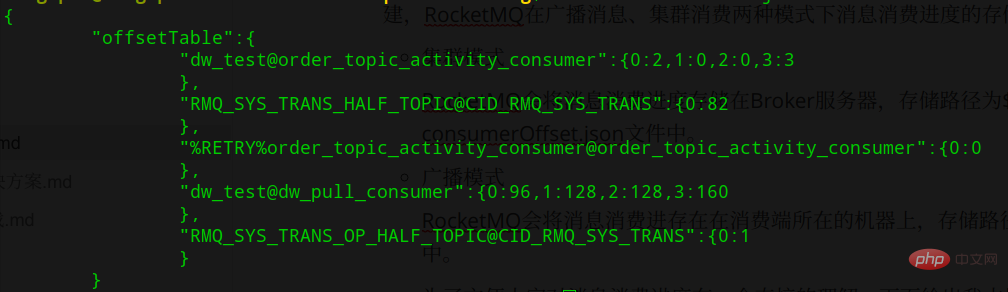 使用
使用topicName@consumerGroupName为Key,消费进度为Value,Value的形式是queueId:offset ,说明如果有多个ConsumerGroup,每个ConsumerGroup的消费进度是不同的,需要分开来存储。
Broadcasting(广播消费)
广播消费消息会发给ConsumerGroup中所有的Consumer。
广播消费模式下,消费进度维护在Consumer端。
消费队列负载算法与重平衡机制
消费队列负载算法
我们知道了在集群消费模式下,ConsumerGroup下所有的Consumer共同消费一个Topic的消息,每个Consumer负责消费N个队列的消息,那么具体是如何分配的呢?这就涉及到消费队列负载算法了。
RocketMQ提供了众多的消费队列负载算法,其中最常用的是两种算法,即AllocateMessageQueueAveragely、AllocateMessageQueueAveragelyByCircle。下面我们来看下这两个算法的区别。
假设,现在一个Topic有16个队列,用q0~q15表示,有3个Consumer,用c0-c2表示。
用AllocateMessageQueueAveragely消费队列负载算法的结果如下:
- c0:q0 q1 q2 q3 q4 q5
- c1:q6 q7 q8 q9 q10
- c2:q11 q12 q13 q14 q15
用AllocateMessageQueueAveragelyByCircle消费队列负载算法的结果如下:
- c0:q0 q3 q6 q9 q12 q15
- c1:q1 q4 q7 q10 q13
- c2:q2 q5 q8 q11 q14
ConsumerGroup下所有的Consumer共同消费一个Topic的消息,每个Consumer负责消费N个队列的消息,但是一个队列不能同时被N个Consumer消费,这意味着什么?
聪明的你一定可以想到,如果一个Topic只有4个队列,而有5个Consumer,那么有一个Consumer将不能分配到任何队列,所以在RocketMQ中,Topic下队列的个数直接决定了Consumer的最大个数,也就说明,不能光靠增加Consumer来提高消费速度。
重平衡
虽然建议在创建Topic的时候,就应该充分考虑队列的个数,但是实际情况往往是不尽人意的,哪怕队列数没有发生改变,Consumer的数量也一定会发生改变,比如Consumer的上下线,比如某个Consumer挂了,比如新增了Consumer。队列的扩容、缩容,Consumer的扩容、缩容都会导致重平衡,也就是为Consumer重新分配消费的队列。
在RocketMQ中,Consumer会定时查询Topic的队列的个数,Consumer的个数,如果发生了改变,就会触发重平衡。
重平衡是RocketMQ内部实现的,程序员无需关心。
Pull OR Push?
一般来说,MQ有两种方法获取消息:
- Pull:Consumer主动拉取消息,好处是Consumer可以控制拉取消息的频率,条数,Consumer知道自身的消费能力,所以在Consumer端不容易造成消息堆积,但是实时性不是太好,效率相对较低。
- Push:Broker主动发送消息,好处是实时性、效率比较高,但是Broker无法知道Consumer端的消费能力,如果发给Consumer的消息过多,会造成Consumer端的消息堆积;如果发给Consumer的数据太少,又会造成Consumer端的空闲。
不管是Pull,还是Push,Consumer总会与Broker产生交互,交互的方式一般有短连接、长连接、轮询三种方式。
看起来,RocketMQ支持既支持Pull,也支持Push,但是实际上Push也是用Pull实现的,那么Consumer是怎么与Broker产生交互的呢?
这就是RocketMQ设计的巧妙的地方了,既不是短连接,也不是长连接,也不是轮询,而是采用的长轮询。
长轮询
Consumer发起拉取消息的请求,分为两种情况:
- 有消息:Consumer拿到消息后,连接断开。
- 没有消息:Borker Hold(保持)住连接一定时间,每隔5秒,检查下是否有消息,如果有消息,给Consumer,连接断开。
事务消息
RocketMQ支持事务消息,Producer把事务消息发送给Broker后,Broker会把消息存储在系统Topic:RMQ_SYS_TRANS_HALF_TOPIC,这样Consumer就无法消费到这条消息了。
Broker会有一个定时任务,消费RMQ_SYS_TRANS_HALF_TOPIC的消息,向Producer发起回查,回查的状态有三种:提交、回滚、未知。
- 如果回查的状态是提交,回滚,会触发消息的提交和回滚;
- 如果是未知,会等待下一次回查,RocketMQ可以设置一条消息的回查间隔与回查次数,超过一定的回查次数,消息会自动回滚。
延迟消息
延迟消息是指息发到Broker后,不能立刻被Consumer消费,需要等待一定的时间才可以被消费到,RocketMQ只支持特定的延迟时间:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。
消费形式
RocketMQ支持两种消费形式:并发消费、顺序消费。 如果是顺序消费,需要保证排序的消息在同一个队列。如何选择队列发送呢,RocketMQ发送消息的方法有好几个重载,其中有一个重载方法支持队列的选择。
同步刷盘、异步刷盘
Producer把消息发送到Borker中,Borker是需要把消息持久化的,RocketMQ支持两种持久化策略:
- 同步刷盘:Borker把消息持久后才返回ACK给Producer,好处是消息可靠性高,但是效率较慢。
- 异步刷盘:Broker把消息写入到PageCache中,就返回ACK给Producer。好处是效率极高,但是如果服务器挂了,消息可能会丢失,如果只是RocketMQ服务挂了,不会造成消息丢失。
同步复制、异步复制
为了MQ的可靠性、可用性,在生产环境,一般会部署Follower节点,Follower节点会复制Master的数据,RocketMQ支持两种持复制策略:
- 同步复制:Master、Follower都把消息写入成功,才返回ACK给Producer,可靠性较高,但是效率较慢。
- 异步复制:只要Master写入成功,就返回ACK给Producer,效率较高,但是可能会丢失消息。
"写入"是写入PageCache,还是写入硬盘,要看Follower Broker的配置。
再谈谈Producer
RocketMQ提供了三种发送消息的方法:
- oneway:fire and forget,单向消息,指消息发送出去后,就不管了,这个方法是没有返回值的。
- 同步:消息发送出去后,同步等待Borker的响应。
- 异步:消息发送出去后,立即返回,收到Boker的响应后,会执行函调方法。
在实际开发中,一般选用同步方法,如果要提高RocketMQ的性能,一般都是修改Borker端的参数,特别是刷盘策略和复制策略。
发送消息重试
消息发送时,如果使用了MessageQueueSelector,那消息发送的重试机制将会失效。
发送消息响应可能为以下四种:
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}复制代码除了第一种,其他情况都是有问题的,为了保证消息不丢失,需要设置Producer参数:RetryAnotherBrokerWhenNotStoreOK为true。
故障规避机制
如果消息发送失败了,重试的时候,还是发送给这个Borker,那么大概率发送还是失败的,RockteMQ设计精巧之处在于,重试的时候,会自动避开这个Borker,而选择其他Borker,但是目前为止,异步发送没有那么智能,只会在一个Borker上重试,所以强烈建议选择同步发送方式。
RocketMQ提供了两种故障规避机制。用参数SendLatencyFaultEnable来控制。
- false:默认值,只有在重试的时候,才会启用故障规避机制,比如发送消息给BorkerA失败了,重试的时候,会选择BorkerB,但是下次发送消息,还是会选择发送给BorkerA。
- true:开启延迟退避机制,一旦消息发送给BorkerA失败,就会悲观的认为在一段时间内,BorkerA不可用,在将来的一段时间内,不会再向BorkerA发送消息。
延迟退避机制看起来很好用,但是一般来说Borker端繁忙,导致Borker不可用或者网络不可用只是一瞬间的事情,马上就可以恢复,如果开启了延迟退避机制,本来可用的Borker在一段时间内却被规避了,其他Borker更加繁忙,那可能情况更糟糕。
再谈谈Consumer
Consumer线程注意事项
Consumer有两个参数,可以消费的并行度,即ConsumeThreadMin、ConsumeThreadMax,看起来给人的感觉是,如果Consumer端堆积消息比较少,消费线程数为ConsumeThreadMin;如果Consumer端堆积消息比较多,就自动开启新的线程来消费,直到消费线程数为ConsumeThreadMax。但是并不是这样,Consumer内部持有一个线程池,选用的是无界队列,也就是ConsumeThreadMax参数是无效的,所以在实际开发中,ConsumeThreadMin、ConsumeThreadMax往往设置成一样。
ConsumeFromWhere
如果查询不到消费进度的时候,Consumer从哪里开始消费,RocketMQ支持从最新消息、最早消息、指定时间戳这三种方式进行消费。
消费消息重试
RocketMQ会为每个ConsumerGroup都设置一个Topic名称为%RETRY%+consumerGroup的重试队列,用来保存需要给ConsumerGroup重试的消息,但是重试需要一定的延时时间,RocketMQ对于重试消息的处理是先保存至Topic名称为SCHEDULE_TOPIC_XXXX的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至%RETRY%+consumerGroup的重试队列中。
消息堆积、消费能力不够,怎么办
- 提高消费进度,这是最好的办法。
- 增加队列,增加Consumer。
- 原先的Consumer作为搬砖工,根据一定的规则把消息“搬”到多个新的Topic,再开几个ConsumerGroup去消费不同的Topic。
- 新开一个ConsumerGroup去消费,也就是两个ConsumerGroup同时消费一个Topic,但是需要注意offset的判断,比如一个ConsumerGroup消费offset为奇数的消息,一个ConsumerGroup消费offset为偶数的消息。
本来以为写扫盲文,应该会写的很顺,但是还是想多了,因为是扫盲文,面向的是没有怎么接触过RocketMQ的小伙伴,但是RocketMQ有没有那么简单,不可能用一篇博客,就让没有怎么接触过RocketMQ的小伙伴顺利入门,所以在写博客的时候,一直在想,这个东西重要吗,需要仔细描述吗;这个东西可以忽视,可以不介绍吗 等等,大家可以看到本文基本都是在介绍各种概念,几乎没有涉及到API的层面,因为一旦涉及到API,那么估计写两个星期也写不完。
End
相关免费学习推荐:java基础教程
以上是终于来了...RocketMQ扫盲篇的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 SpringBoot整合RocketMQ的方法是什么
May 14, 2023 am 10:19 AM
SpringBoot整合RocketMQ的方法是什么
May 14, 2023 am 10:19 AM
1.SpringBoot整合RocketMQ在SpringBoot中集成RocketMQ,只需要简单四步:1.引入相关依赖org.apache.rocketmqrocketmq-spring-boot-starter2.添加RocketMQ的相关配置rocketmq:consumer:group:springboot_consumer_group#一次拉取消息最大值,注意是拉取消息的最大值而非消费最大值pull-batch-size:10name-server:10.5.103.6:9876pr
 阿里二面:RocketMQ 消费者拉取一批消息,其中部分消费失败了,偏移量怎样更新?
Apr 12, 2023 pm 11:28 PM
阿里二面:RocketMQ 消费者拉取一批消息,其中部分消费失败了,偏移量怎样更新?
Apr 12, 2023 pm 11:28 PM
大家好,我是君哥。最近有读者参加面试时被问了一个问题,如果消费者拉取了一批消息,比如 100 条,第 100 条消息消费成功了,但是第 50 条消费失败,偏移量会怎样更新?就着这个问题,今天来聊一下,如果一批消息有消费失败的情况时,偏移量怎么保存。1 拉取消息1.1 封装拉取请求以 RocketMQ 推模式为例,RocketMQ 消费者启动代码如下:public static void main(String[] args) throws InterruptedException, MQClie
 SpringBoot整合RocketMQ遇到的坑怎么解决
May 19, 2023 am 11:25 AM
SpringBoot整合RocketMQ遇到的坑怎么解决
May 19, 2023 am 11:25 AM
应用场景在实现RocketMQ消费时,一般会用到@RocketMQMessageListener注解定义Group、Topic以及selectorExpression(数据过滤、选择的规则)为了能支持动态筛选数据,一般都会使用表达式,然后通过apollo或者cloudconfig进行动态切换。引入依赖org.apache.rocketmqrocketmq-spring-boot-starter2.0.4消费者代码@RocketMQMessageListener(consumerGroup=&qu
 常用环境部署—Docker安装RocketMQ教程!
Mar 07, 2024 am 09:30 AM
常用环境部署—Docker安装RocketMQ教程!
Mar 07, 2024 am 09:30 AM
在Docker中安装RocketMQ的过程如下所示:创建Docker网络:在终端中执行以下命令来创建Docker网络,以便在容器之间进行通信:dockernetworkcreaterocketmq-network下载RocketMQ镜像:在终端中执行以下命令来下载RocketMQ的Docker镜像:dockerpullrocketmqinc/rocketmq启动NameServer容器:在终端中执行以下命令来启动NameServer容器:dockerrun-d--namermqnamesrv--
 分析Java开发RocketMQ生产者高可用示例
Apr 23, 2023 pm 11:28 PM
分析Java开发RocketMQ生产者高可用示例
Apr 23, 2023 pm 11:28 PM
1消息publicclassMessageimplementsSerializable{privatestaticfinallongserialVersionUID=8445773977080406428L;//主题名字privateStringtopic;//消息扩展信息,Tag,keys,延迟级别都存在这里privateMapproperties;//消息体,字节数组privatebyte[]body;//设置消息的key,publicvoidsetKeys(Stringkeys){}//设
 Springboot中RocketMQ怎么实现广播消息
May 11, 2023 pm 08:13 PM
Springboot中RocketMQ怎么实现广播消息
May 11, 2023 pm 08:13 PM
RocketMQ消息模式主要有两种:广播模式、集群模式(负载均衡模式)广播模式是每个消费者,都会消费消息;负载均衡模式是每一个消费只会被某一个消费者消费一次;我们业务上一般用的是负载均衡模式,当然一些特殊场景需要用到广播模式,比如发送一个信息到邮箱,手机,站内提示;我们可以通过@RocketMQMessageListener的messageModel属性值来设置,MessageModel.BROADCASTING是广播模式,MessageModel.CLUSTERING是默认集群负载均衡模式下面
 Springboot中RocketMQ怎么实现消息发送与接收
May 18, 2023 pm 05:19 PM
Springboot中RocketMQ怎么实现消息发送与接收
May 18, 2023 pm 05:19 PM
springboot+rockermq实现简单的消息发送与接收普通消息的发送方式有3种:单向发送、同步发送和异步发送。下面来介绍下springboot+rockermq整合实现普通消息的发送与接收创建Springboot项目,添加rockermq依赖org.apache.rocketmqrocketmq-spring-boot-starter2.2.1配置rocketmq#端口server:port:8083#配置rocketmqrocketmq:name-server:127.0.0.1:98
 SpringBoot如何整合RocketMQ事务、广播以及顺序消息
May 18, 2023 am 10:04 AM
SpringBoot如何整合RocketMQ事务、广播以及顺序消息
May 18, 2023 am 10:04 AM
环境:springboot2.3.9RELEASE+RocketMQ4.8.0依赖org.springframework.bootspring-boot-starter-weborg.apache.rocketmqrocketmq-spring-boot-starter2.2.0配置文件server:port:8080---rocketmq:nameServer:localhost:9876producer:group:demo-mq普通消息发送@ResourceprivateRocketMQT
