

优化技巧!!前端菜鸟让接口提速60%

javascript栏目介绍前端菜鸟让接口提速60%的技巧。

背景
好久没写文章了,沉寂了大半年
持续性萎靡不振,间歇性癫痫发作
天天来大姨爹,在迷茫、焦虑中度过每一天
不得不承认,其实自己就是个废物
作为一名低级前端工程师
最近处理了一个十几年的祖传老接口
它继承了一切至尊级复杂度逻辑
传说中调用一次就能让cpu负载飙升90%的日天服务
专治各种不服与老年痴呆
我们欣赏一下这个接口的耗时
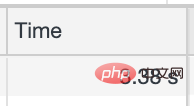
平均调用时间在3s以上
导致页面出现严重的转菊花
经过各种深度剖析与专业人士答疑
最后得出结论是:放弃医疗
鲁迅在《狂人日记》里曾说过:“能打败我的,只有女人和酒精,而不是bug”
每当身处黑暗之时
这句话总能让我看到光
所以这次要硬起来
我决定做一个node代理层
用下面三个方法进行优化:
按需加载 -> graphQL数据缓存 -> redis轮询更新 -> schedule
代码地址:github
按需加载 -> graphQL
天秀老接口存在一个问题,我们每次请求1000条数据,返回的数组中,每一条数据都有上百个字段,其实我们前端只用到其中的10个字段而已。
如何从一百多个字段中,抽取任意n个字段,这就用到graphQL。
graphQL按需加载数据只需要三步:
- 定义数据池 root
- 描述数据池中数据结构 schema
- 自定义查询数据 query
定义数据池
我们针对屌丝追求女神的场景,定义一个数据池,如下:
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码里面有两个女神的所有信息,包括女神的名字、手机、微信、身高、学校、备胎集合等信息。
接下来我们就要对这些数据结构进行描述。
描述数据池中数据结构
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码上面这段代码就是女神信息的schema。
首先我们用type Query定义了一个对女神信息的查询,里面包含了很多女孩girls的信息Info,这些信息是一堆数组,所以是[Info]
我们在type Info中描述了一个女孩的所有信息的维度,包括了名字(name)、手机(iphone)、微信(weixin)、身高(height)、学校(school)、备胎集合(wheel)
定义查询规则
得到女神的信息描述(schema)后,就可以自定义获取女神的各种信息组合了。
比如我想和女神认识,只需要拿到她的名字(name)和微信号(weixin)。查询规则代码如下:
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码筛选结果如下:

又比如我想进一步和女神发展,我需要拿到她备胎信息,查询一下她备胎们(wheel)的家产(money)分别是多少,分析一下自己能不能获取优先择偶权。查询规则代码如下:
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
wheel {
money
}
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码筛选结果如下:

我们通过女神的例子,展现了如何通过graphQL按需加载数据。
映射到我们业务具体场景中,天秀接口返回的每条数据都包含100个字段,我们配置schema,获取其中的10个字段,这样就避免了剩下90个不必要字段的传输。
graphQL还有另一个好处就是可以灵活配置,这个接口需要10个字段,另一个接口要5个字段,第n个接口需要另外x个字段
按照传统的做法我们要做出n个接口才能满足,现在只需要一个接口配置不同schema就能满足所有情况了。
感悟
在生活中,咱们舔狗真的很缺少graphQL按需加载的思维
渣男渣女,各取所需
你的真情在名媛面前不值一提
我们要学会投其所好
上来就亮车钥匙,没有车就秀才艺
今晚我有一条祖传的染色体想与您分享一下
行就行,不行就换下一个
直奔主题,简单粗暴
缓存 -> redis
第二个优化手段,使用redis缓存
天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
轮询更新 -> schedule
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
- “啊宝贝,最近有没有想我”
- “啊宝贝早安安”
- “宝贝晚安,么么哒”
虽然女神依然看不上我
但仍然时刻准备着为女神服务
结尾
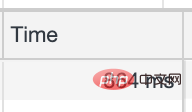
经过以上三个方法优化后
接口请求耗时从3s降到了860ms
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
以上是优化技巧!!前端菜鸟让接口提速60%的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 电脑主板内部接口都有什么 推荐电脑主板内部接口介绍
Mar 12, 2024 pm 04:34 PM
电脑主板内部接口都有什么 推荐电脑主板内部接口介绍
Mar 12, 2024 pm 04:34 PM
我们在电脑组装的过程中,安装过程虽然简单,不过往往都是在接线上遇到问题,经常有装机用户误将CPU散热器的供电线插到了SYS_FAN上,虽然风扇可以转动,不过在开机可能会有F1报错“CPUFanError”,同时也导致了CPU散热器无法智能调速。下面装机之家分享一下电脑主板上CPU_FAN、SYS_FAN、CHA_FAN、CPU_OPT接口知识科普。电脑主板上CPU_FAN、SYS_FAN、CHA_FAN、CPU_OPT接口知识科普1、CPU_FANCPU_FAN是CPU散热器专用接口,12V工作
 Go语言中常见的编程范式和设计模式
Mar 04, 2024 pm 06:06 PM
Go语言中常见的编程范式和设计模式
Mar 04, 2024 pm 06:06 PM
Go语言作为一门现代化的、高效的编程语言,拥有丰富的编程范式和设计模式可以帮助开发者编写高质量、可维护的代码。本文将介绍Go语言中常见的编程范式和设计模式,并提供具体的代码示例。1.面向对象编程在Go语言中,可以使用结构体和方法实现面向对象编程。通过定义结构体和给结构体绑定方法,可以实现数据封装和行为绑定在一起的面向对象特性。packagemaini
 PHP接口简介及其定义方式
Mar 23, 2024 am 09:00 AM
PHP接口简介及其定义方式
Mar 23, 2024 am 09:00 AM
PHP接口简介及其定义方式PHP是一种广泛应用于Web开发的开源脚本语言,具有灵活、简单、强大等特点。在PHP中,接口(interface)是一种定义多个类之间公共方法的工具,实现了多态性,让代码更加灵活和可重用。本文将介绍PHP接口的概念及其定义方式,同时提供具体的代码示例展示其用法。1.PHP接口概念接口在面向对象编程中扮演着重要的角色,定义了类应
 NotImplementedError()的处理方案
Mar 01, 2024 pm 03:10 PM
NotImplementedError()的处理方案
Mar 01, 2024 pm 03:10 PM
报错的原因在python中,Tornado中抛出NotImplementedError()的原因可能是因为未实现某个抽象方法或接口。这些方法或接口在父类中声明,但在子类中未实现。子类需要实现这些方法或接口才能正常工作。如何解决解决这个问题的方法是在子类中实现父类声明的抽象方法或接口。如果您正在使用一个类来继承另一个类,并且您看到了这个错误,则应该在子类中实现父类中所有声明的抽象方法。如果您正在使用一个接口,并且您看到了这个错误,则应该在实现该接口的类中实现该接口中所有声明的方法。如果您不确定哪些
 Java 中接口和抽象类在设计模式中的应用
May 01, 2024 pm 06:33 PM
Java 中接口和抽象类在设计模式中的应用
May 01, 2024 pm 06:33 PM
接口和抽象类在设计模式中用于解耦和可扩展性。接口定义方法签名,抽象类提供部分实现,子类必须实现未实现的方法。在策略模式中,接口用于定义算法,抽象类或具体类提供实现,允许动态切换算法。在观察者模式中,接口用于定义观察者行为,抽象类或具体类用于订阅和发布通知。在适配器模式中,接口用于适配现有类,抽象类或具体类可实现兼容接口,允许与原有代码交互。
 透视鸿蒙系统:功能实测与使用感受
Mar 23, 2024 am 10:45 AM
透视鸿蒙系统:功能实测与使用感受
Mar 23, 2024 am 10:45 AM
鸿蒙系统作为华为推出的全新操作系统,在行业内引起了不小的轰动。作为华为在美国禁令之后的一次全新尝试,鸿蒙系统被寄予了厚望和期待。近日,我有幸得到了一部搭载鸿蒙系统的华为手机,经过一段时间的使用和实测,我将分享一些关于鸿蒙系统的功能实测和使用感受。首先,让我们来看一下鸿蒙系统的界面和功能。鸿蒙系统整体采用了华为自家的设计风格,简洁清晰,操作流畅。在桌面上,各种
 Java 中接口和抽象类的内部类实现
Apr 30, 2024 pm 02:03 PM
Java 中接口和抽象类的内部类实现
Apr 30, 2024 pm 02:03 PM
Java允许在接口和抽象类中定义内部类,为代码重用和模块化提供灵活性。接口中的内部类可实现特定功能,而抽象类中的内部类可定义通用功能,子类提供具体实现。
 Java 接口与抽象类:通往编程天堂之路
Mar 04, 2024 am 09:13 AM
Java 接口与抽象类:通往编程天堂之路
Mar 04, 2024 am 09:13 AM
接口:无实现的契约接口在Java中定义了一组方法签名,但不提供任何具体实现。它充当一种契约,强制实现该接口的类实现其指定的方法。接口中的方法是抽象方法,没有方法体。代码示例:publicinterfaceAnimal{voideat();voidsleep();}抽象类:部分实现的蓝图抽象类是一种父类,它提供了一个部分实现,可以被它的子类继承。与接口不同,抽象类可以包含具体的实现和抽象方法。抽象方法是用abstract关键字声明的,并且必须被子类覆盖。代码示例:publicabstractcla
