

当被swoole协程三连问时,快哭了!

swoole教程介绍相关协程的面试问题

推荐(免费):swoole教程
什么是进程?
进程就是应用程序的启动实例。独立的文件资源,数据资源,内存空间。
什么是线程?
线程属于进程,是程序的执行者。一个进程至少包含一个主线程,也可以有更多的子线程。线程有两种调度策略,一是:分时调度,二是:抢占式调度。
我的官方企鹅群
什么是协程?
协程是轻量级线程,协程也是属于线程,协程是在线程里执行的。协程的调度是用户手动切换的,所以又叫用户空间线程。协程的创建、切换、挂起、销毁全部为内存操作,消耗是非常低的。协程的调度策略是:协作式调度。
Swoole 协程的原理
Swoole4 由于是单线程多进程的,同一时间同一个进程只会有一个协程在运行。
Swoole server 接收数据在 worker 进程触发 onReceive 回调,产生一个携程。Swoole 为每个请求创建对应携程。协程中也能创建子协程。
协程在底层实现上是单线程的,因此同一时间只有一个协程在工作,协程的执行是串行的。
因此多任务多协程执行时,一个协程正在运行时,其他协程会停止工作。当前协程执行阻塞 IO 操作时会挂起,底层调度器会进入事件循环。当有 IO 完成事件时,底层调度器恢复事件对应的协程的执行。。所以协程不存在 IO 耗时,非常适合高并发 IO 场景。(如下图)
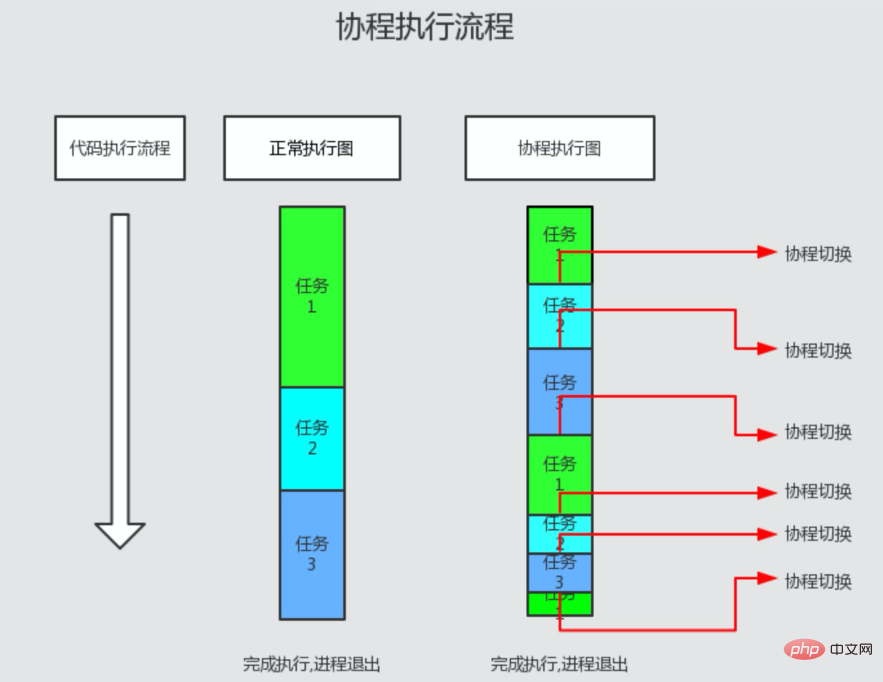
Swoole 的协程执行流程
协程没有 IO 等待 正常执行 PHP 代码,不会产生执行流程切换
协程遇到 IO 等待 立即将控制权切,待 IO 完成后,重新将执行流切回原来协程切出的点
协程并行协程依次执行,同上一个逻辑
协程嵌套执行流程由外向内逐层进入,直到发生 IO,然后切到外层协程,父协程不会等待子协程结束
协程的执行顺序
先来看看基础的例子:
go(function () {
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});go() 是 \Co::create() 的缩写, 用来创建一个协程, 接受 callback 作为参数, callback 中的代码, 会在这个新建的协程中执行.
备注: \Swoole\Coroutine 可以简写为 \Co
上面的代码执行结果:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello go1 hello main hello go2
执行结果和我们平时写代码的顺序, 好像没啥区别. 实际执行过程:
运行此段代码, 系统启动一个新进程
遇到
go(), 当前进程中生成一个协程, 协程中输出heelo go1, 协程退出进程继续向下执行代码, 输出
hello main再生成一个协程, 协程中输出
heelo go2, 协程退出
运行此段代码, 系统启动一个新进程. 如果不理解这句话, 你可以使用如下代码:
// co.php<?phpsleep(100);
执行并使用 ps aux 查看系统中的进程:
root@b98940b00a9b /v/w/c/p/swoole# php co.php &⏎
root@b98940b00a9b /v/w/c/p/swoole# ps auxPID USER TIME COMMAND
1 root 0:00 php -a 10 root 0:00 sh 19 root 0:01 fish 749 root 0:00 php co.php 760 root 0:00 ps aux
⏎我们来稍微改一改, 体验协程的调度:
use Co;go(function () {
Co::sleep(1); // 只新增了一行代码
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});\Co::sleep() 函数功能和 sleep() 差不多, 但是它模拟的是 IO等待(IO后面会细讲). 执行的结果如下:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go2 hello go1
怎么不是顺序执行的呢? 实际执行过程:
- 运行此段代码, 系统启动一个新进程
- 遇到
go(), 当前进程中生成一个协程 - 协程中遇到 IO阻塞 (这里是
Co::sleep()模拟出的 IO等待), 协程让出控制, 进入协程调度队列 - 进程继续向下执行, 输出
hello main - 执行下一个协程, 输出
hello go2 - 之前的协程准备就绪, 继续执行, 输出
hello go1
到这里, 已经可以看到 swoole 中 协程与进程的关系, 以及 协程的调度, 我们再改一改刚才的程序:
go(function () {
Co::sleep(1);
echo "hello go1 \n";});echo "hello main \n";go(function () {
Co::sleep(1);
echo "hello go2 \n";});我想你已经知道输出是什么样子了:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go1 hello go2 ⏎
协程快在哪? 减少IO阻塞导致的性能损失
大家可能听到使用协程的最多的理由, 可能就是 协程快. 那看起来和平时写得差不多的代码, 为什么就要快一些呢? 一个常见的理由是, 可以创建很多个协程来执行任务, 所以快. 这种说法是对的, 不过还停留在表面.
首先, 一般的计算机任务分为 2 种:
- CPU密集型, 比如加减乘除等科学计算
- IO 密集型, 比如网络请求, 文件读写等
其次, 高性能相关的 2 个概念:
- 并行: 同一个时刻, 同一个 CPU 只能执行同一个任务, 要同时执行多个任务, 就需要有多个 CPU 才行
- 并发: 由于 CPU 切换任务非常快, 快到人类可以感知的极限, 就会有很多任务 同时执行 的错觉
了解了这些, 我们再来看协程, 协程适合的是 IO 密集型 应用, 因为协程在 IO阻塞 时会自动调度, 减少IO阻塞导致的时间损失.
我们可以对比下面三段代码:
- 普通版: 执行 4 个任务
$n = 4;for ($i = 0; $i < $n; $i++) {
sleep(1);
echo microtime(true) . ": hello $i \n";};echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ⏎
- 单个协程版:
$n = 4;go(function () use ($n) {
for ($i = 0; $i < $n; $i++) {
Co::sleep(1);
echo microtime(true) . ": hello $i \n";
};});echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s user 0m 0.00s sys 0m 0.02s ⏎
- 多协程版: 见证奇迹的时刻
$n = 4;for ($i = 0; $i < $n; $i++) {
go(function () use ($i) {
Co::sleep(1);
echo microtime(true) . ": hello $i \n";
});};echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965245.5491: hello 01528965245.5498: hello 31528965245.5502: hello 21528965245.5506: hello 1real 0m 1.02s user 0m 0.01s sys 0m 0.00s ⏎
为什么时间有这么大的差异呢:
普通写法, 会遇到 IO阻塞 导致的性能损失
单协程: 尽管 IO阻塞 引发了协程调度, 但当前只有一个协程, 调度之后还是执行当前协程
多协程: 真正发挥出了协程的优势, 遇到 IO阻塞 时发生调度, IO就绪时恢复运行
我们将多协程版稍微修改一下:
- 多协程版2: CPU密集型
$n = 4;for ($i = 0; $i < $n; $i++) {
go(function () use ($i) {
// Co::sleep(1);
sleep(1);
echo microtime(true) . ": hello $i \n";
});};echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965743.4327: hello 01528965744.4331: hello 11528965745.4337: hello 21528965746.4342: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ⏎
只是将 Co::sleep() 改成了 sleep(), 时间又和普通版差不多了. 因为:
sleep()可以看做是 CPU密集型任务, 不会引起协程的调度Co::sleep()模拟的是 IO密集型任务, 会引发协程的调度
这也是为什么, 协程适合 IO密集型 的应用.
再来一组对比的例子: 使用 redis
// 同步版, redis使用时会有 IO 阻塞$cnt = 2000;for ($i = 0; $i < $cnt; $i++) {
$redis = new \Redis();
$redis->connect('redis');
$redis->auth('123');
$key = $redis->get('key');}// 单协程版: 只有一个协程, 并没有使用到协程调度减少 IO 阻塞go(function () use ($cnt) {
for ($i = 0; $i < $cnt; $i++) {
$redis = new Co\Redis();
$redis->connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
}});// 多协程版, 真正使用到协程调度带来的 IO 阻塞时的调度for ($i = 0; $i < $cnt; $i++) {
go(function () {
$redis = new Co\Redis();
$redis->connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
});}性能对比:
# 多协程版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 0.54s user 0m 0.04s sys 0m 0.23s ⏎# 同步版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 1.48s user 0m 0.17s sys 0m 0.57s ⏎
swoole 协程和 go 协程对比: 单进程 vs 多线程
接触过 go 协程的 coder, 初始接触 swoole 的协程会有点 懵, 比如对比下面的代码:
package main
import (
"fmt"
"time")func main() {
go func() {
fmt.Println("hello go")
}()
fmt.Println("hello main")
time.Sleep(time.Second)}> 14:11 src $ go run test.go hello main hello go
刚写 go 协程的 coder, 在写这个代码的时候会被告知不要忘了 time.Sleep(time.Second), 否则看不到输出 hello go, 其次, hello go与 hello main 的顺序也和 swoole 中的协程不一样.
原因就在于 swoole 和 go 中, 实现协程调度的模型不同.
上面 go 代码的执行过程:
- 运行 go 代码, 系统启动一个新进程
- 查找
package main, 然后执行其中的func mian() - 遇到协程, 交给协程调度器执行
- 继续向下执行, 输出
hello main - 如果不添加
time.Sleep(time.Second), main 函数执行完, 程序结束, 进程退出, 导致调度中的协程也终止
go 中的协程, 使用的 MPG 模型:
- M 指的是 Machine, 一个M直接关联了一个内核线程
- P 指的是 processor, 代表了M所需的上下文环境, 也是处理用户级代码逻辑的处理器
- G 指的是 Goroutine, 其实本质上也是一种轻量级的线程
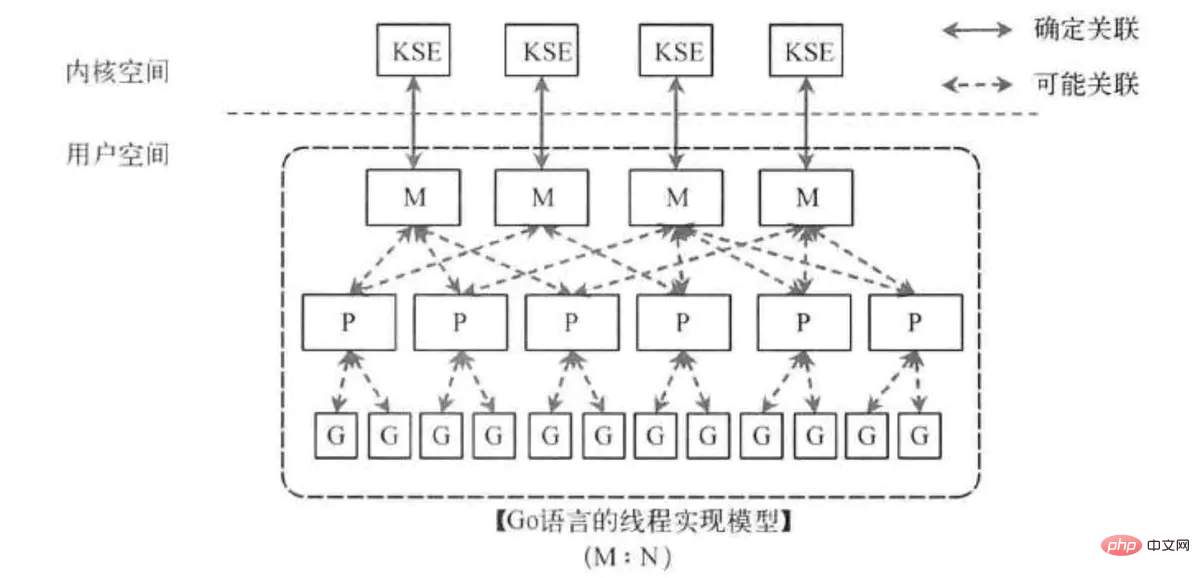
而 swoole 中的协程调度使用 单进程模型, 所有协程都是在当前进程中进行调度, 单进程的好处也很明显 – 简单 / 不用加锁 / 性能也高.
无论是 go 的 MPG模型, 还是 swoole 的 单进程模型, 都是对 CSP理论 的实现.
以上是当被swoole协程三连问时,快哭了!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题




 如何使用Swoole的内存池来减少内存碎片?
Mar 17, 2025 pm 01:23 PM
如何使用Swoole的内存池来减少内存碎片?
Mar 17, 2025 pm 01:23 PM
本文讨论了使用Swoole的内存池通过有效的内存管理和配置来减少内存碎片。主要重点是在池中启用,大小和重复使用内存。

 我该如何为Swoole开源项目做出贡献?
Mar 18, 2025 pm 03:58 PM
我该如何为Swoole开源项目做出贡献?
Mar 18, 2025 pm 03:58 PM
本文概述了为Swoole项目做出贡献的方法,包括报告错误,提交功能,编码和改进文档。它讨论了初学者开始贡献的必要技能和步骤,以及如何找到紧迫的是
 如何使用Swoole的异步I/O功能?
Mar 18, 2025 pm 03:56 PM
如何使用Swoole的异步I/O功能?
Mar 18, 2025 pm 03:56 PM
本文讨论了在PHP中使用Swoole的异步I/O功能用于高性能应用程序。它涵盖安装,服务器设置和优化策略。单词计数:159
 Swoole的反应堆模型如何在引擎盖下工作?
Mar 18, 2025 pm 03:54 PM
Swoole的反应堆模型如何在引擎盖下工作?
Mar 18, 2025 pm 03:54 PM
Swoole的反应堆模型使用事件驱动的,非阻滞I/O架构来有效地管理高持续性场景,通过各种技术优化性能。(159个字符)(159个字符)
 Swoole的内置Websocket客户端的关键功能是什么?
Mar 14, 2025 pm 12:25 PM
Swoole的内置Websocket客户端的关键功能是什么?
Mar 14, 2025 pm 12:25 PM
Swoole的Websocket客户端以高性能,异步I/O以及SSL/TLS等安全功能增强实时通信。它支持可扩展性和有效的数据流。
 如何使用Swoole构建微服务体系结构?
Mar 17, 2025 pm 01:18 PM
如何使用Swoole构建微服务体系结构?
Mar 17, 2025 pm 01:18 PM
文章讨论使用Swoole进行微服务,重点介绍通过异步I/O和Coroutines的设计,实现和性能提高。WordCount:159
