

详细了解Nodejs中的事件循环机制

本篇文章带大家了解一下nodejs事件循环机制。有一定的参考价值,有需要的朋友可以参考一下,希望对大家有所帮助。

相关推荐:《nodejs 教程》
Node.js 采用事件驱动和异步 I/O 的方式,实现了一个单线程、高并发的 JavaScript 运行时环境,而单线程就意味着同一时间只能做一件事,那么 Node.js 如何通过单线程来实现高并发和异步 I/O?本文将围绕这个问题来探讨 Node.js 的单线程模型 。
高并发策略
一般来说,高并发的解决方案就是提供多线程模型,服务器为每个客户端请求分配一个线程,使用同步 I/O,系统通过线程切换来弥补同步 I/O 调用的时间开销。比如 Apache 就是这种策略,由于 I/O 一般都是耗时操作,因此这种策略很难实现高性能,但非常简单,可以实现复杂的交互逻辑。
而事实上,大多数网站的服务器端都不会做太多的计算,它们接收到请求以后,把请求交给其它服务来处理(比如读取数据库),然后等着结果返回,最后再把结果发给客户端。因此,Node.js 针对这一事实采用了单线程模型来处理,它不会为每个接入请求分配一个线程,而是用一个主线程处理所有的请求,然后对 I/O 操作进行异步处理,避开了创建、销毁线程以及在线程间切换所需的开销和复杂性。
事件循环
Node.js 在主线程里维护了一个事件队列,当接到请求后,就将该请求作为一个事件放入这个队列中,然后继续接收其他请求。当主线程空闲时(没有请求接入时),就开始循环事件队列,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,就从 线程池 中拿出一个线程来处理这个事件,并指定回调函数,然后继续循环队列中的其他事件。
当线程中的 I/O 任务完成以后,就执行指定的回调函数,并把这个完成的事件放到事件队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用。 这个过程就叫 事件循环 (Event Loop),其运行原理如下图所示:
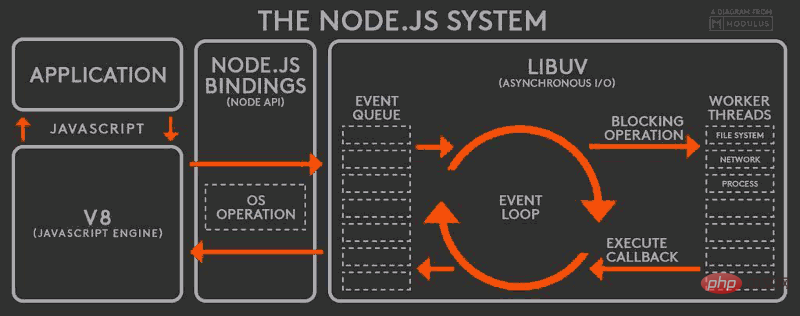
这个图是整个 Node.js 的运行原理,从左到右,从上到下,Node.js 被分为了四层,分别是 应用层、V8引擎层、Node API层 和 LIBUV层。
应用层: 即 JavaScript 交互层,常见的就是 Node.js 的模块,比如 http,fs
V8引擎层: 即利用 V8 引擎来解析JavaScript 语法,进而和下层 API 交互
NodeAPI层: 为上层模块提供系统调用,一般是由 C 语言来实现,和操作系统进行交互 。
LIBUV层: 是跨平台的底层封装,实现了 事件循环、文件操作等,是 Node.js 实现异步的核心 。
无论是 Linux 平台还是 Windows 平台,Node.js 内部都是通过 线程池 来完成异步 I/O 操作的,而 LIBUV 针对不同平台的差异性实现了统一调用。因此,Node.js 的单线程仅仅是指 JavaScript 运行在单线程中,而并非 Node.js 是单线程。
工作原理
Node.js 实现异步的核心是事件,也就是说,它把每一个任务都当成 事件 来处理,然后通过 Event Loop 模拟了异步的效果,为了更具体、更清晰的理解和接受这个事实,下面我们用伪代码来描述一下其工作原理 。
【1】定义事件队列
既然是队列,那就是一个先进先出 (FIFO) 的数据结构,我们用JS数组来描述,如下:
/** * 定义事件队列 * 入队:push() * 出队:shift() * 空队列:length == 0 */ globalEventQueue: []
我们利用数组来模拟队列结构:数组的第一个元素是队列的头部,数组的最后一个元素是队列的尾部,push() 就是在队列尾部插入一个元素,shift() 就是从队列头部弹出一个元素。这样就实现了一个简单的事件队列。
【2】定义接收请求入口
每一个请求都会被拦截并进入处理函数,如下所示:
/**
* 接收用户请求
* 每一个请求都会进入到该函数
* 传递参数request和response
*/
processHttpRequest:function(request,response){
// 定义一个事件对象
var event = createEvent({
params:request.params, // 传递请求参数
result:null, // 存放请求结果
callback:function(){} // 指定回调函数
});
// 在队列的尾部添加该事件
globalEventQueue.push(event);
}这个函数很简单,就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
【3】定义 Event Loop
当主线程处于空闲时就开始循环事件队列,所以我们还要定义一个函数来循环事件队列:
/**
* 事件循环主体,主线程择机执行
* 循环遍历事件队列
* 处理非IO任务
* 处理IO任务
* 执行回调,返回给上层
*/
eventLoop:function(){
// 如果队列不为空,就继续循环
while(this.globalEventQueue.length > 0){
// 从队列的头部拿出一个事件
var event = this.globalEventQueue.shift();
// 如果是耗时任务
if(isIOTask(event)){
// 从线程池里拿出一个线程
var thread = getThreadFromThreadPool();
// 交给线程处理
thread.handleIOTask(event)
}else {
// 非耗时任务处理后,直接返回结果
var result = handleEvent(event);
// 最终通过回调函数返回给V8,再由V8返回给应用程序
event.callback.call(null,result);
}
}
}主线程不停的检测事件队列,对于 I/O 任务,就交给线程池来处理,非 I/O 任务就自己处理并返回。
【4】处理 I/O 任务
线程池接到任务以后,直接处理IO操作,比如读取数据库:
/**
* 处理IO任务
* 完成后将事件添加到队列尾部
* 释放线程
*/
handleIOTask:function(event){
//当前线程
var curThread = this;
// 操作数据库
var optDatabase = function(params,callback){
var result = readDataFromDb(params);
callback.call(null,result)
};
// 执行IO任务
optDatabase(event.params,function(result){
// 返回结果存入事件对象中
event.result = result;
// IO完成后,将不再是耗时任务
event.isIOTask = false;
// 将该事件重新添加到队列的尾部
this.globalEventQueue.push(event);
// 释放当前线程
releaseThread(curThread)
})
}当 I/O 任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件时,就直接处理了。
总结以上过程我们发现,Node.js 只用了一个主线程来接收请求,但它接收请求以后并没有直接做处理,而是放到了事件队列中,然后又去接收其他请求了,空闲的时候,再通过 Event Loop 来处理这些事件,从而实现了异步效果,当然对于IO类任务还需要依赖于系统层面的线程池来处理。
因此,我们可以简单的理解为:Node.js 本身是一个多线程平台,而它对 JavaScript 层面的任务处理是单线程的。
CPU密集型是短板
至此,对于 Node.js 的单线程模型,我们应该有了一个简单而又清晰的认识,它通过事件驱动模型实现了高并发和异步 I/O,然而也有 Node.js 不擅长做的事情:
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。但不是所有的任务都是 I/O 密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时 Node.js 就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着 。如下图所示:
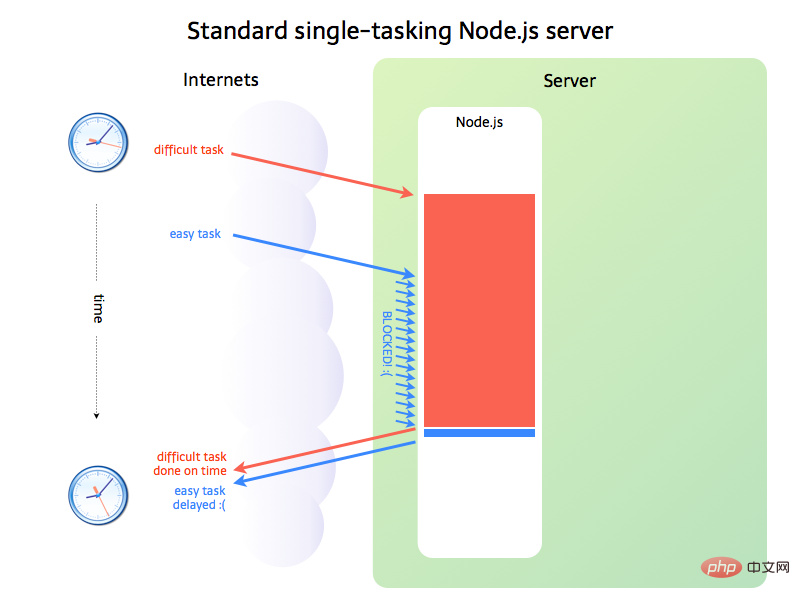
在事件队列中,如果前面的 CPU 计算任务没有完成,后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多 CPU 或多核的,而 Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
因此,Node.js 并不适合 CPU 密集型任务。
适用场景
RESTful API - 请求和响应只需少量文本,并且不需要大量逻辑处理, 因此可以并发处理数万条连接。
聊天服务 - 轻量级、高流量,没有复杂的计算逻辑。
更多编程相关知识,请访问:编程教学!!
以上是详细了解Nodejs中的事件循环机制的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 nodejs和vuejs区别
Apr 21, 2024 am 04:17 AM
nodejs和vuejs区别
Apr 21, 2024 am 04:17 AM
Node.js 是一种服务器端 JavaScript 运行时,而 Vue.js 是一个客户端 JavaScript 框架,用于创建交互式用户界面。Node.js 用于服务器端开发,如后端服务 API 开发和数据处理,而 Vue.js 用于客户端开发,如单页面应用程序和响应式用户界面。

 nodejs怎么连接mysql数据库
Apr 21, 2024 am 06:13 AM
nodejs怎么连接mysql数据库
Apr 21, 2024 am 06:13 AM
要连接 MySQL 数据库,需要遵循以下步骤:安装 mysql2 驱动程序。使用 mysql2.createConnection() 创建连接对象,其中包含主机地址、端口、用户名、密码和数据库名称。使用 connection.query() 执行查询。最后使用 connection.end() 结束连接。
 nodejs中的全局变量有哪些
Apr 21, 2024 am 04:54 AM
nodejs中的全局变量有哪些
Apr 21, 2024 am 04:54 AM
Node.js 中存在以下全局变量:全局对象:global核心模块:process、console、require运行时环境变量:__dirname、__filename、__line、__column常量:undefined、null、NaN、Infinity、-Infinity
 nodejs安装目录里的npm与npm.cmd文件有什么区别
Apr 21, 2024 am 05:18 AM
nodejs安装目录里的npm与npm.cmd文件有什么区别
Apr 21, 2024 am 05:18 AM
Node.js 安装目录中有两个与 npm 相关的文件:npm 和 npm.cmd,区别如下:扩展名不同:npm 是可执行文件,npm.cmd 是命令窗口快捷方式。Windows 用户:npm.cmd 可以在命令提示符下使用,npm 只能从命令行运行。兼容性:npm.cmd 特定于 Windows 系统,npm 跨平台可用。使用建议:Windows 用户使用 npm.cmd,其他操作系统使用 npm。
 nodejs和java的差别大吗
Apr 21, 2024 am 06:12 AM
nodejs和java的差别大吗
Apr 21, 2024 am 06:12 AM
Node.js 和 Java 的主要差异在于设计和特性:事件驱动与线程驱动:Node.js 基于事件驱动,Java 基于线程驱动。单线程与多线程:Node.js 使用单线程事件循环,Java 使用多线程架构。运行时环境:Node.js 在 V8 JavaScript 引擎上运行,而 Java 在 JVM 上运行。语法:Node.js 使用 JavaScript 语法,而 Java 使用 Java 语法。用途:Node.js 适用于 I/O 密集型任务,而 Java 适用于大型企业应用程序。

 nodejs项目怎么部署到服务器
Apr 21, 2024 am 04:40 AM
nodejs项目怎么部署到服务器
Apr 21, 2024 am 04:40 AM
Node.js 项目的服务器部署步骤:准备部署环境:获取服务器访问权限、安装 Node.js、设置 Git 存储库。构建应用程序:使用 npm run build 生成可部署代码和依赖项。上传代码到服务器:通过 Git 或文件传输协议。安装依赖项:SSH 登录服务器并使用 npm install 安装应用程序依赖项。启动应用程序:使用 node index.js 等命令启动应用程序,或使用 pm2 等进程管理器。配置反向代理(可选):使用 Nginx 或 Apache 等反向代理路由流量到应用程
