

惊!一行SQL语句竟然这么多锁..


推荐(免费):SQL教程
间隙锁再加上行锁,很容易在判断是否会出现锁等待的问题上犯错。
因为间隙锁在可重复读隔离级别下才有效,本文默认可重复读。
加锁规则
- 原则1
加锁的基本单位是next-key lock,前开后闭区间。 - 原则2
查找过程中访问到的对象才会加锁。 - 优化1
索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁。 - 优化2
索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁。 - 一个bug
唯一索引上的范围查询会访问到不满足条件的第一个值为止。
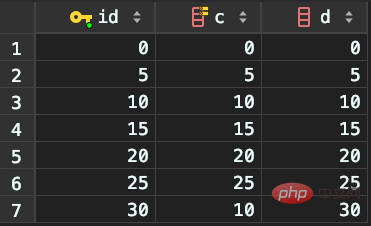
数据准备
表名:t
新增数据:(0,0,0),(5,5,5),(10,10,10),(15,15,15),(20,20,20),(25,25,25)
接下来的例子基本都是配合着图片说明的,所以我建议你可以对照着文稿看,有些例子可能会“毁三观”,也建议你读完文章后亲手实践一下。
案例
等值查询间隙锁
等值查询的间隙锁

表t中无id=7,所以根据原则1,加锁单位next-key lock,所以session A加锁范围(5,10]
同时根据优化2,等值查询(id=7),而id=10不满足,next-key lock退化成间隙锁,因此最终加锁范围(5,10)

所以,session B要往这个间隙里面插入id=8的记录会被锁住,但是session C修改id=10这行是可以的。
非唯一索引等值锁
只加在非唯一索引上的锁
session A要给索引c的c=5这行加读锁
根据原则1,加锁单位next-key lock,因此给(0,5]加next-key lock
c是普通索引,因此仅访问c=5这条记录不能马上停下,需要向右遍历,查到c=10才放弃。根据原则2,访问到的都要加锁,因此要给(5,10]加next-key lock
同时符合优化2:等值判断,向右遍历,最后一个值不满足c=5这个等值条件,因此退化成间隙锁(5,10)
根据原则2 ,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁,所以session B的update语句可以执行完成。
但session C要插入(7,7,7),就会被session A的间隙锁(5,10)锁住。
这个例子中,lock in share mode只锁覆盖索引,但如果是for update就不一样了。 执行 for update时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。
这例说明,锁是加在索引上的;同时,它给我们的指导是,如果你要用lock in share mode来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段。比如,将session A的查询语句改成select d from t where c=5 lock in share mode。你可以自己验证一下效果。
3 主键索引范围锁
范围查询。
对于我们这个表t,下面这两条查询语句,加锁范围相同吗?
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
你可能会想,id定义为int类型,这两个语句就是等价的吧?其实,它们并不完全等价。
在逻辑上,这两条查语句肯定是等价的,但是它们的加锁规则不太一样。现在,我们就让session A执行第二个查询语句,来看看加锁效果。
图3 主键索引上范围查询的锁
现在我们就用前面提到的加锁规则,来分析一下session A 会加什么锁呢?
开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。 根据优化1, 主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁。
范围查找就往后继续找,找到id=15这一行停下来,因此需要加next-key lock(10,15]。
所以,session A这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15]。这样,session B和session C的结果你就能理解了。
这里你需要注意一点,首次session A定位查找id=10的行的时候,是当做等值查询来判断的,而向右扫描到id=15的时候,用的是范围查询判断。
再看看范围查询加锁,你可以对照着案例三
非唯一索引范围锁
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; select * from t where c>=10 and c<11 for update; | ||
| insert into t values(8,8,8);(blocked) | ||
| update t set d=d+1 where c=15;(blocked) |
- session1在第一次用
c=10定位记录时,索引c加了(5,10] next-key lock - c是非唯一索引,无优化规则,即不会退变为行锁
- 因此最终sesion1加锁为c的
(5,10]和(10,15]next-key lock。
所以从结果上来看,sesson2要插入(8,8,8)的这个insert语句时就被阻塞。
非唯一索引要扫到c=15,才知道无需继续往后遍历。
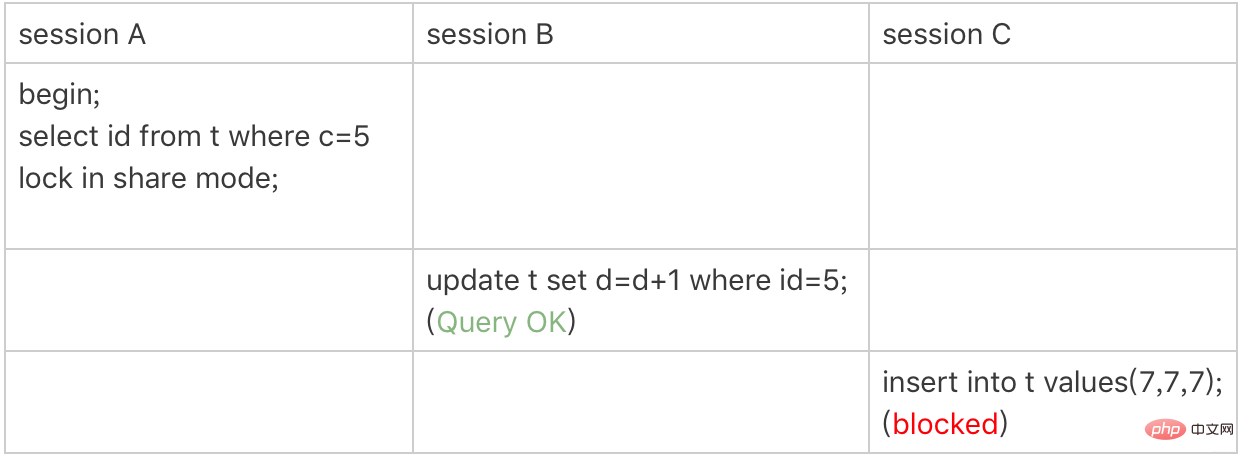
唯一索引范围锁bug
前四案例用到两个原则和两个优化,再看加锁规则bug案例。
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; select * from t where id>10 and id<=15 for update; | ||
| update t set d=d+1 where id=20;(阻塞) |
||
| insert into t values(16,16,16);(阻塞) |
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; delete * from t where c=10 |
||
| insert into t values(13,13,13);(阻塞) |
||
| update t set d=d+1 where c=15; |
session1遍历时先访问第一个c=10:
- 根据原则1,这里加是(c=5,id=5)到(c=10,id=10) next-key lock
- 然后,session1 向右查找,直到碰到(c=15,id=15)这行,循环结束。根据优化2,等值查询,向右查找到不满足条件的行,所以退化成(c=10,id=10) 到 (c=15,id=15)的间隙锁(开区间,(c=5,id=5)和(c=15,id=15)这两行无锁)。
7 limit 语句加锁
| session_1 | session_2 |
|---|---|
| begin; delete * from t where c=10 limit 2 |
|
| insert into t values(13,13,13);(阻塞) |
session1 的delete语句加了 limit 2。你知道表t里c=10的记录其实只有两条,因此加不加limit 2,删除的效果都是一样的,但是加锁的效果却不同。可以看到,session B的insert语句执行通过了,跟案例六的结果不同。
这是因为,案例七里的delete语句明确加了limit 2的限制,因此在遍历到(c=10, id=30)这一行之后,满足条件的语句已经有两条,循环就结束了。
因此,索引c上的加锁范围就变成了从(c=5,id=5)到(c=10,id=30)这个前开后闭区间,如下图所示:
带limit 2的加锁效果
可以看到,(c=10,id=30)之后的这个间隙并没有在加锁范围里,因此insert语句插入c=12是可以执行成功的。
这个例子对我们实践的指导意义就是,在删除数据的时候尽量加limit。这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围。
一个死锁的例子
前面的例子中,我们在分析的时候,是按照next-key lock的逻辑来分析的,因为这样分析比较方便。最后我们再看一个案例,目的是说明:next-key lock实际上是间隙锁和行锁加起来的结果。
你一定会疑惑,这个概念不是一开始就说了吗?不要着急,我们先来看下面这个例子:
案例八的操作序列
session A 启动事务后执行查询语句加lock in share mode,在索引c上加了next-key lock(5,10] 和间隙锁(10,15);
session B 的update语句也要在索引c上加next-key lock(5,10] ,进入锁等待;
然后session A要再插入(8,8,8)这一行,被session B的间隙锁锁住。由于出现了死锁,InnoDB让session B回滚。
你可能会问,session B的next-key lock不是还没申请成功吗?
其实是这样的,session B的“加next-key lock(5,10] ”操作,实际上分成了两步,先是加(5,10)的间隙锁,加锁成功;然后加c=10的行锁,这时候才被锁住的。
也就是说,我们在分析加锁规则的时候可以用next-key lock来分析。但是要知道,具体执行的时候,是要分成间隙锁和行锁两段来执行的。
总结
所有案例都是在可重复读下验证,可重复读遵守两阶段锁协议,所有加锁的资源,都是在事务提交或者回滚的时候才释放。
在最后的案例中,你可以清楚地知道next-key lock实际上是由间隙锁加行锁实现的。如果切换到读提交隔离级别(read-committed)的话,就好理解了,过程中去掉间隙锁的部分,也就是只剩下行锁的部分。
在读提交隔离级别下还有一个优化,即:语句执行过程中加上的行锁,在语句执行完成后,就要把“不满足条件的行”上的行锁直接释放了,不需要等到事务提交。
读提交隔离级别下,锁的范围更小,锁的时间更短,所以不少业务也默认使用读提交。
在业务需要使用可重复读时,解决幻读问题同时,最大限度提升系统并行处理事务的能力。
间隙锁再加上行锁,很容易在判断是否会出现锁等待的问题上犯错。
因为间隙锁在可重复读隔离级别下才有效,本文默认可重复读。
更多相关知识敬请访问SQL免费栏目~~
以上是惊!一行SQL语句竟然这么多锁..的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Hibernate 框架中 HQL 和 SQL 的区别是什么?
Apr 17, 2024 pm 02:57 PM
Hibernate 框架中 HQL 和 SQL 的区别是什么?
Apr 17, 2024 pm 02:57 PM
HQL和SQL在Hibernate框架中进行比较:HQL(1.面向对象语法,2.数据库无关的查询,3.类型安全),而SQL直接操作数据库(1.与数据库无关的标准,2.可执行复杂查询和数据操作)。
 Oracle SQL中除法运算的用法
Mar 10, 2024 pm 03:06 PM
Oracle SQL中除法运算的用法
Mar 10, 2024 pm 03:06 PM
《OracleSQL中除法运算的用法》在OracleSQL中,除法运算是常见的数学运算之一。在数据查询和处理过程中,除法运算可以帮助我们计算字段之间的比例或者得出特定数值的逻辑关系。本文将介绍OracleSQL中除法运算的用法,并提供具体的代码示例。一、OracleSQL中除法运算的两种方式在OracleSQL中,除法运算可以使用两种不同的方式进行
 Oracle和DB2的SQL语法比较与区别
Mar 11, 2024 pm 12:09 PM
Oracle和DB2的SQL语法比较与区别
Mar 11, 2024 pm 12:09 PM
Oracle和DB2是两个常用的关系型数据库管理系统,它们都有自己独特的SQL语法和特点。本文将针对Oracle和DB2的SQL语法进行比较与区别,并提供具体的代码示例。数据库连接在Oracle中,使用以下语句连接数据库:CONNECTusername/password@database而在DB2中,连接数据库的语句如下:CONNECTTOdataba
 详解MyBatis动态SQL标签中的Set标签功能
Feb 26, 2024 pm 07:48 PM
详解MyBatis动态SQL标签中的Set标签功能
Feb 26, 2024 pm 07:48 PM
MyBatis动态SQL标签解读:Set标签用法详解MyBatis是一个优秀的持久层框架,它提供了丰富的动态SQL标签,可以灵活地构建数据库操作语句。其中,Set标签是用于生成UPDATE语句中SET子句的标签,在更新操作中非常常用。本文将详细解读MyBatis中Set标签的用法,以及通过具体的代码示例来演示其功能。什么是Set标签Set标签用于MyBati
 SQL中的identity属性是什么意思?
Feb 19, 2024 am 11:24 AM
SQL中的identity属性是什么意思?
Feb 19, 2024 am 11:24 AM
SQL中的Identity是什么,需要具体代码示例在SQL中,Identity是一种用于生成自增数字的特殊数据类型,它常用于唯一标识表中的每一行数据。Identity列通常与主键列配合使用,可以确保每条记录都有一个独一无二的标识符。本文将详细介绍Identity的使用方式以及一些实际的代码示例。Identity的基本使用方式在创建表时,可以使用Identit
 SQL出现5120错误怎么解决
Mar 06, 2024 pm 04:33 PM
SQL出现5120错误怎么解决
Mar 06, 2024 pm 04:33 PM
解决办法:1、检查登录用户是否具有足够的权限来访问或操作该数据库,确保该用户具有正确的权限;2、检查SQL Server服务的帐户是否具有访问指定文件或文件夹的权限,确保该帐户具有足够的权限来读取和写入该文件或文件夹;3、检查指定的数据库文件是否已被其他进程打开或锁定,尝试关闭或释放该文件,并重新运行查询;4、尝试以管理员身份运行Management Studio等等。
 数据库技术大比拼:Oracle和SQL的区别有哪些?
Mar 09, 2024 am 08:30 AM
数据库技术大比拼:Oracle和SQL的区别有哪些?
Mar 09, 2024 am 08:30 AM
数据库技术大比拼:Oracle和SQL的区别有哪些?在数据库领域中,Oracle和SQLServer是两种备受推崇的关系型数据库管理系统。尽管它们都属于关系型数据库的范畴,但两者之间存在着诸多不同之处。在本文中,我们将深入探讨Oracle和SQLServer之间的区别,以及它们在实际应用中的特点和优势。首先,Oracle和SQLServer在语法方面存
 SQL中months_between如何使用
Jan 25, 2024 pm 03:23 PM
SQL中months_between如何使用
Jan 25, 2024 pm 03:23 PM
SQL中MONTHS_BETWEEN是一个常见的函数,用于计算两个日期之间的月份差。它的使用方法取决于具体的数据库管理系统。
