

解析PHP8底层内核源码-数组(四)

本篇文章给大家介绍《解析PHP8底层内核源码-数组(四)》。有一定的参考价值,有需要的朋友可以参考一下,希望对大家有所帮助。
相关文章推荐:《解析PHP8底层内核源码-数组(一)》《解析PHP8底层内核源码-数组(二)》《解析PHP8底层内核源码-数组(三)》
在Runningprocess 里已经知道代码需要经过词法分析 语法分析 编译 执行 四大步骤
PHP 8会在编译阶段(将AST抽象语法树编译成opcode时)就创建一个数组常量。这个数组常量和数字常量、字符串常量一样,是在编译阶段就确定并分配内存的。因此数组的初始化发生在编译阶段。
PHP的数组初始化代码 部分如下
//如果开启zend_debug
#if !ZEND_DEBUG && defined(HAVE_BUILTIN_CONSTANT_P)
# define zend_new_array(size) \
(__builtin_constant_p(size) ? \
((((uint32_t)(size)) <= HT_MIN_SIZE) ? \
_zend_new_array_0() \
//走 _zend_new_array_0
: \
_zend_new_array((size)) \
) \
: \
_zend_new_array((size)) \
)
#else
//没有开启 也就是一般模式 走 _zend_new_array
# define zend_new_array(size) \
_zend_new_array(size)
#endif
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent)
{
_zend_hash_init_int(ht, nSize, pDestructor, persistent);
}
ZEND_API HashTable* ZEND_FASTCALL _zend_new_array_0(void)
{ //分配内存空间
HashTable *ht = emalloc(sizeof(HashTable));
//初始化
_zend_hash_init_int(ht, HT_MIN_SIZE, ZVAL_PTR_DTOR, 0);
return ht;
}
//初始化方法
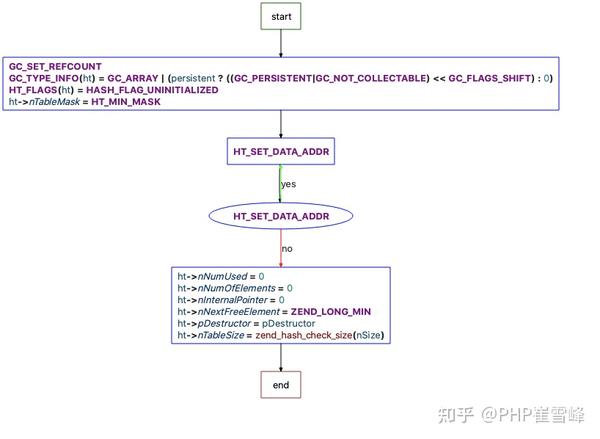
static zend_always_inline void _zend_hash_init_int(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent)
{
GC_SET_REFCOUNT(ht, 1);
GC_TYPE_INFO(ht) = GC_ARRAY | (persistent ? ((GC_PERSISTENT|GC_NOT_COLLECTABLE) << GC_FLAGS_SHIFT) : 0);
HT_FLAGS(ht) = HASH_FLAG_UNINITIALIZED;
ht->nTableMask = HT_MIN_MASK;
HT_SET_DATA_ADDR(ht, &uninitialized_bucket);
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
ht->nInternalPointer = 0;
ht->nNextFreeElement = ZEND_LONG_MIN;
ht->pDestructor = pDestructor;
ht->nTableSize = zend_hash_check_size(nSize);
}
//初始化 bucket 也就是 ardata
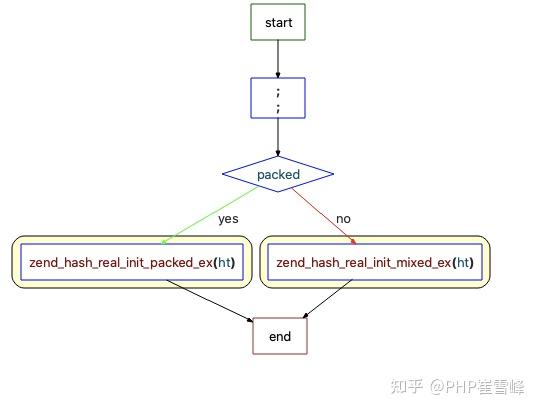
ZEND_API void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
{
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
//调用 zend_hash_real_init_ex方法
zend_hash_real_init_ex(ht, packed);
}
//zend_hash_real_init_ex方法
static zend_always_inline void zend_hash_real_init_ex(HashTable *ht, bool packed)
{
HT_ASSERT_RC1(ht);
ZEND_ASSERT(HT_FLAGS(ht) & HASH_FLAG_UNINITIALIZED);
if (packed) {
//如果是packed_array
zend_hash_real_init_packed_ex(ht);
} else {
//如果是 hash_array
zend_hash_real_init_mixed_ex(ht);
}
}
//paced_array 初始化bucket 的代码
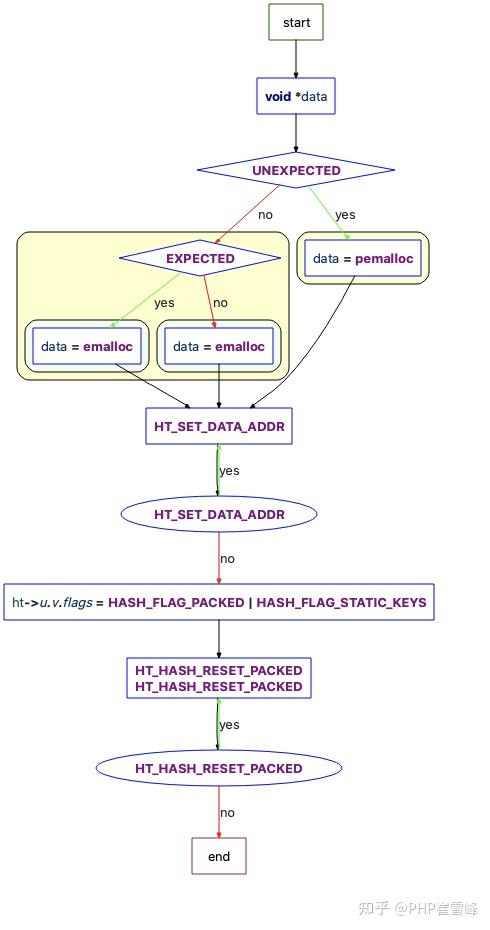
static zend_always_inline void zend_hash_real_init_packed_ex(HashTable *ht)
{
void *data;
if (UNEXPECTED(GC_FLAGS(ht) & IS_ARRAY_PERSISTENT)) {
data = pemalloc(HT_SIZE_EX(ht->nTableSize, HT_MIN_MASK), 1);
} else if (EXPECTED(ht->nTableSize == HT_MIN_SIZE)) {
data = emalloc(HT_SIZE_EX(HT_MIN_SIZE, HT_MIN_MASK));
} else {
data = emalloc(HT_SIZE_EX(ht->nTableSize, HT_MIN_MASK));
}
HT_SET_DATA_ADDR(ht, data);
/* Don't overwrite iterator count. */
ht->u.v.flags = HASH_FLAG_PACKED | HASH_FLAG_STATIC_KEYS;
HT_HASH_RESET_PACKED(ht);
}
//hash_array 初始化bucket的代码
static zend_always_inline void zend_hash_real_init_mixed_ex(HashTable *ht)
{
void *data;
uint32_t nSize = ht->nTableSize;
if (UNEXPECTED(GC_FLAGS(ht) & IS_ARRAY_PERSISTENT)) {
data = pemalloc(HT_SIZE_EX(nSize, HT_SIZE_TO_MASK(nSize)), 1);
} else if (EXPECTED(nSize == HT_MIN_SIZE)) {
data = emalloc(HT_SIZE_EX(HT_MIN_SIZE, HT_SIZE_TO_MASK(HT_MIN_SIZE)));
ht->nTableMask = HT_SIZE_TO_MASK(HT_MIN_SIZE);
HT_SET_DATA_ADDR(ht, data);
/* Don't overwrite iterator count. */
ht->u.v.flags = HASH_FLAG_STATIC_KEYS;
#ifdef __SSE2__
do {
__m128i xmm0 = _mm_setzero_si128();
xmm0 = _mm_cmpeq_epi8(xmm0, xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 0), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 4), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 8), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 12), xmm0);
} while (0);
#elif defined(__aarch64__)
do {
int32x4_t t = vdupq_n_s32(-1);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 0), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 4), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 8), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 12), t);
} while (0);
#else
HT_HASH_EX(data, 0) = -1;
HT_HASH_EX(data, 1) = -1;
HT_HASH_EX(data, 2) = -1;
HT_HASH_EX(data, 3) = -1;
HT_HASH_EX(data, 4) = -1;
HT_HASH_EX(data, 5) = -1;
HT_HASH_EX(data, 6) = -1;
HT_HASH_EX(data, 7) = -1;
HT_HASH_EX(data, 8) = -1;
HT_HASH_EX(data, 9) = -1;
HT_HASH_EX(data, 10) = -1;
HT_HASH_EX(data, 11) = -1;
HT_HASH_EX(data, 12) = -1;
HT_HASH_EX(data, 13) = -1;
HT_HASH_EX(data, 14) = -1;
HT_HASH_EX(data, 15) = -1;
#endif
return;
} else {
data = emalloc(HT_SIZE_EX(nSize, HT_SIZE_TO_MASK(nSize)));
}
ht->nTableMask = HT_SIZE_TO_MASK(nSize);
HT_SET_DATA_ADDR(ht, data);
HT_FLAGS(ht) = HASH_FLAG_STATIC_KEYS;
HT_HASH_RESET(ht);
}
//数组赋值和更新值
static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag)
{
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if ((flag & HASH_ADD_NEXT) && h == ZEND_LONG_MIN) {
h = 0;
}
if (HT_FLAGS(ht) & HASH_FLAG_PACKED) {
if (h < ht->nNumUsed) {
p = ht->arData + h;
if (Z_TYPE(p->val) != IS_UNDEF) {
replace:
if (flag & HASH_ADD) {
return NULL;
}
if (ht->pDestructor) {
ht->pDestructor(&p->val);
}
ZVAL_COPY_VALUE(&p->val, pData);
return &p->val;
} else { /* we have to keep the order :( */
goto convert_to_hash;
}
} else if (EXPECTED(h < ht->nTableSize)) {
add_to_packed:
p = ht->arData + h;
/* incremental initialization of empty Buckets */
if ((flag & (HASH_ADD_NEW|HASH_ADD_NEXT)) != (HASH_ADD_NEW|HASH_ADD_NEXT)) {
if (h > ht->nNumUsed) {
Bucket *q = ht->arData + ht->nNumUsed;
while (q != p) {
ZVAL_UNDEF(&q->val);
q++;
}
}
}
ht->nNextFreeElement = ht->nNumUsed = h + 1;
goto add;
} else if ((h >> 1) < ht->nTableSize &&
(ht->nTableSize >> 1) < ht->nNumOfElements) {
zend_hash_packed_grow(ht);
goto add_to_packed;
} else {
if (ht->nNumUsed >= ht->nTableSize) {
ht->nTableSize += ht->nTableSize;
}
convert_to_hash:
zend_hash_packed_to_hash(ht);
}
} else if (HT_FLAGS(ht) & HASH_FLAG_UNINITIALIZED) {
if (h < ht->nTableSize) {
zend_hash_real_init_packed_ex(ht);
goto add_to_packed;
}
zend_hash_real_init_mixed(ht);
} else {
if ((flag & HASH_ADD_NEW) == 0 || ZEND_DEBUG) {
p = zend_hash_index_find_bucket(ht, h);
if (p) {
ZEND_ASSERT((flag & HASH_ADD_NEW) == 0);
goto replace;
}
}
ZEND_HASH_IF_FULL_DO_RESIZE(ht);/* If the Hash table is full, resize it */
}
idx = ht->nNumUsed++;
nIndex = h | ht->nTableMask;
p = ht->arData + idx;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
if ((zend_long)h >= ht->nNextFreeElement) {
ht->nNextFreeElement = (zend_long)h < ZEND_LONG_MAX ? h + 1 : ZEND_LONG_MAX;
}
add:
ht->nNumOfElements++;
p->h = h;
p->key = NULL;
ZVAL_COPY_VALUE(&p->val, pData);
return &p->val;
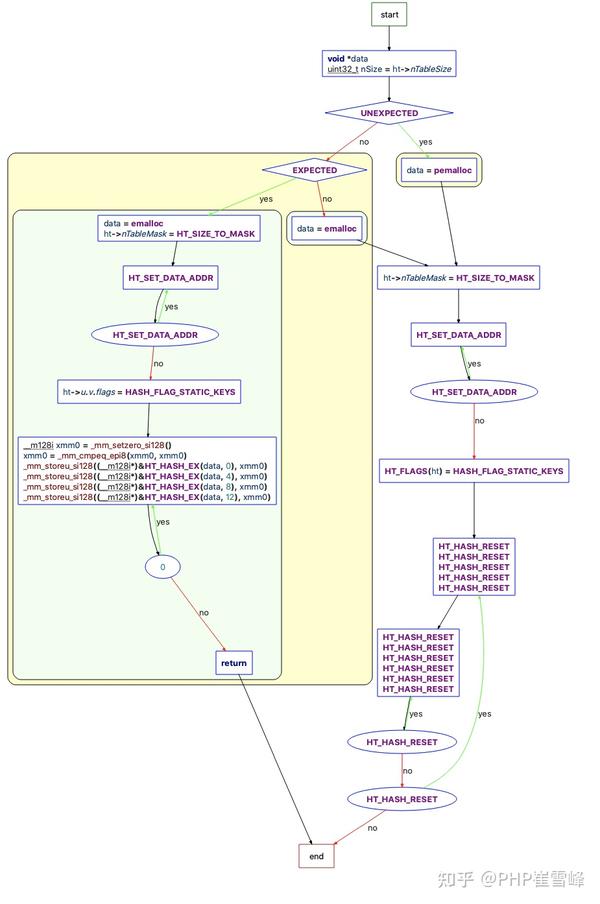
}_zend_hash_init_int 流程图如下


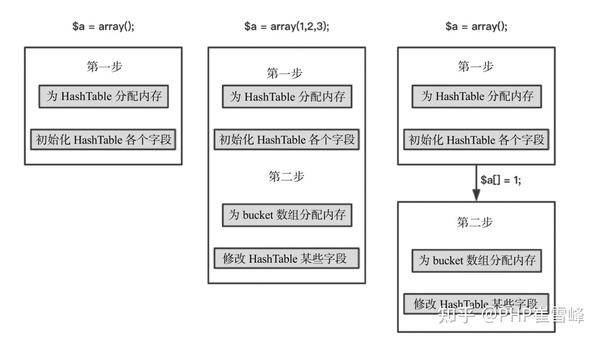
在PHP 8中,数组的初始化其实是分两步的。
第1步:分配HashTable结构体内存
第2步: 初始化HashTable结构体各个字段
第3步:分配bucket数组内存,修改一些字段值。
对于第3步,并不是每次都进行。比如像“$a = array()”这种写法,由于数组为空,PHP 不会额外申请bucket数组内存。而对于“$a = array(1, 2, 3)”这种写法,由于数组非空,因此PHP 需要执行第3步 分配bucket数组内存,修改一些字段值。



▏本文经原作者PHP崔雪峰同意,发布在php中文网,原文地址:https://zhuanlan.zhihu.com/p/361006441
以上是解析PHP8底层内核源码-数组(四)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何使用 foreach 循环去除 PHP 数组中的重复元素?
Apr 27, 2024 am 11:33 AM
如何使用 foreach 循环去除 PHP 数组中的重复元素?
Apr 27, 2024 am 11:33 AM
使用foreach循环去除PHP数组中重复元素的方法如下:遍历数组,若元素已存在且当前位置不是第一个出现的位置,则删除它。举例而言,若数据库查询结果存在重复记录,可使用此方法去除,得到不含重复记录的结果。
 PHP数组深度复制的艺术:使用不同方法实现完美复制
May 01, 2024 pm 12:30 PM
PHP数组深度复制的艺术:使用不同方法实现完美复制
May 01, 2024 pm 12:30 PM
PHP中深度复制数组的方法包括:使用json_decode和json_encode进行JSON编码和解码。使用array_map和clone进行深度复制键和值的副本。使用serialize和unserialize进行序列化和反序列化。
 PHP 数组键值翻转:不同方法的性能对比分析
May 03, 2024 pm 09:03 PM
PHP 数组键值翻转:不同方法的性能对比分析
May 03, 2024 pm 09:03 PM
PHP数组键值翻转方法性能对比表明:array_flip()函数在大型数组(超过100万个元素)下比for循环性能更优,耗时更短。手动翻转键值的for循环方法耗时相对较长。
 PHP 数组分组函数在数据整理中的应用
May 04, 2024 pm 01:03 PM
PHP 数组分组函数在数据整理中的应用
May 04, 2024 pm 01:03 PM
PHP的array_group_by函数可根据键或闭包函数对数组中的元素分组,返回一个关联数组,其中键是组名,值是属于该组的元素数组。
 深度复制PHP数组的最佳实践:探索高效的方法
Apr 30, 2024 pm 03:42 PM
深度复制PHP数组的最佳实践:探索高效的方法
Apr 30, 2024 pm 03:42 PM
在PHP中执行数组深度复制的最佳实践是:使用json_decode(json_encode($arr))将数组转换为JSON字符串,然后再将其转换回数组。使用unserialize(serialize($arr))将数组序列化为字符串,然后将其反序列化为新数组。使用RecursiveIteratorIterator迭代器对多维数组进行递归遍历。
 PHP数组多维排序实战:从简单到复杂场景
Apr 29, 2024 pm 09:12 PM
PHP数组多维排序实战:从简单到复杂场景
Apr 29, 2024 pm 09:12 PM
多维数组排序可分为单列排序和嵌套排序。单列排序可使用array_multisort()函数按列排序;嵌套排序需要递归函数遍历数组并排序。实战案例包括按产品名称排序和按销售量和价格复合排序。
 PHP 数组合并去重算法:并行的解决方案
Apr 18, 2024 pm 02:30 PM
PHP 数组合并去重算法:并行的解决方案
Apr 18, 2024 pm 02:30 PM
PHP数组合并去重算法提供了并行的解决方案,将原始数组分成小块并行处理,主进程合并块的结果去重。算法步骤:分割原始数组为均等分配的小块。并行处理每个块去重。合并块结果并再次去重。
 PHP 数组分组函数在查找重复元素中的作用
May 05, 2024 am 09:21 AM
PHP 数组分组函数在查找重复元素中的作用
May 05, 2024 am 09:21 AM
PHP的array_group()函数可用于按指定键对数组进行分组,以查找重复元素。该函数通过以下步骤工作:使用key_callback指定分组键。可选地使用value_callback确定分组值。对分组元素进行计数并识别重复项。因此,array_group()函数对于查找和处理重复元素非常有用。
