

用实例告诉你该如何优化SQL

虽然现今硬件成本已经下降,通过升级硬件提升系统性能也是常用的优化方式。而实时性要求很高的系统,还是要从sql方面进行优化,今天我们从实例的出发,介绍该如何优化SQL。
判断问题SQL
判断SQL是否有问题时可以通过两个表象进行判断:
-
系统级别表象
CPU消耗严重
IO等待严重
页面响应时间过长
应用的日志出现超时等错误
可以使用sar命令,top命令查看当前系统状态。也可以通过Prometheus、Grafana等监控工具观察系统状态。
-
SQL语句表象
冗长
执行时间过长
从全表扫描获取数据
执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,而且出现问题的频率肯定会更高。更进一步判断SQL问题就得从执行计划入手,如下所示:

执行计划告诉我们本次查询走了全表扫描Type=ALL,rows很大(9950400)基本可以判断这是一段"有味道"的SQL。
获取问题SQL
不同数据库有不同的获取方法,以下为目前主流数据库的慢查询SQL获取工具
-
MySQL
慢查询日志
测试工具loadrunner
Percona公司的ptquery等工具
-
Oracle
AWR报告
测试工具loadrunner等
相关内部视图如v$、$session_wait等
GRID CONTROL监控工具
-
达梦数据库
AWR报告
测试工具loadrunner等
达梦性能监控工具(dem)
相关内部视图如v$、$session_wait等
SQL编写技巧
SQL编写有以下几个通用的技巧:
• 合理使用索引
索引少了查询慢;索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能 选择率高(重复值少)且被where频繁引用需要建立B树索引;
一般join列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得平衡;复合索引创建时要注意基于非前导列查询的情况
• 使用UNION ALL替代UNION
UNION ALL的执行效率比UNION高,UNION执行时需要排重;UNION需要对数据进行排序
• 避免select * 写法
执行SQL时优化器需要将 * 转成具体的列;每次查询都要回表,不能走覆盖索引。
• JOIN字段建议建立索引
一般JOIN字段都提前加上索引
• 避免复杂SQL语句
提升可阅读性;避免慢查询的概率;可以转换成多个短查询,用业务端处理
• 避免where 1=1写法
• 避免order by rand()类似写法
RAND()导致数据列被多次扫描
SQL优化
执行计划
完成SQL优化一定要先读执行计划,执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以MYSQL为例,看看执行计划是什么。(每个数据库的执行计划都不一样,需要自行了解)

| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
接下来我们用一段实际优化案例来说明SQL优化的过程及优化技巧。
优化案例
表结构
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
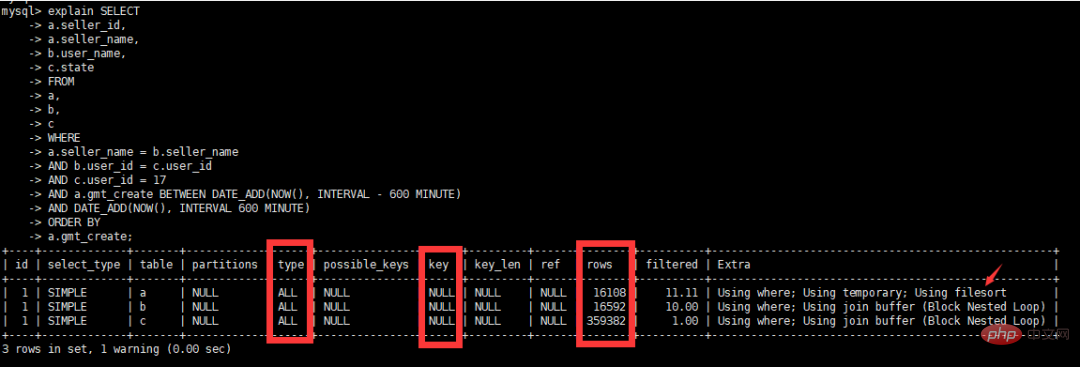
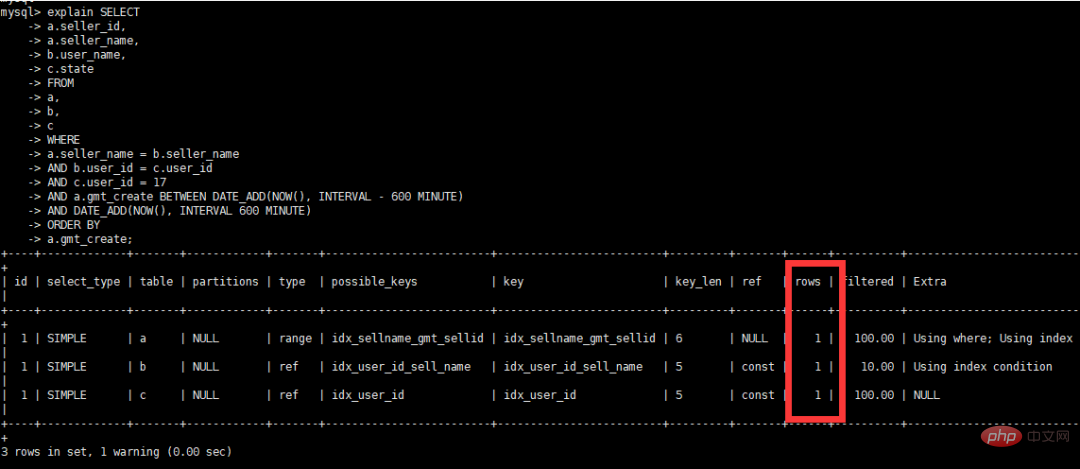
);三张表关联,查询当前用户在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列,具体SQL如下
select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;查看数据量

原执行时间

原执行计划
初步优化思路
SQL中 where条件字段类型要跟表结构一致,表中 user_id 为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表 user_id 字段改成int类型。
因存在b表和c表关联,将b和c表 user_id创建索引
因存在a表和b表关联,将a和b表 seller_name字段创建索引
利用复合索引消除临时表和排序
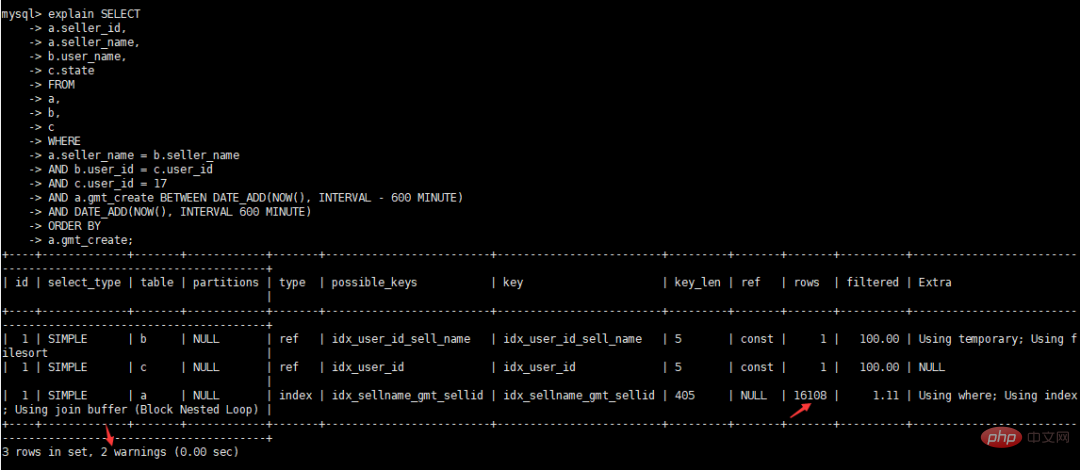
初步优化SQL
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
查看优化后执行时间

查看优化后执行计划
查看warnings信息
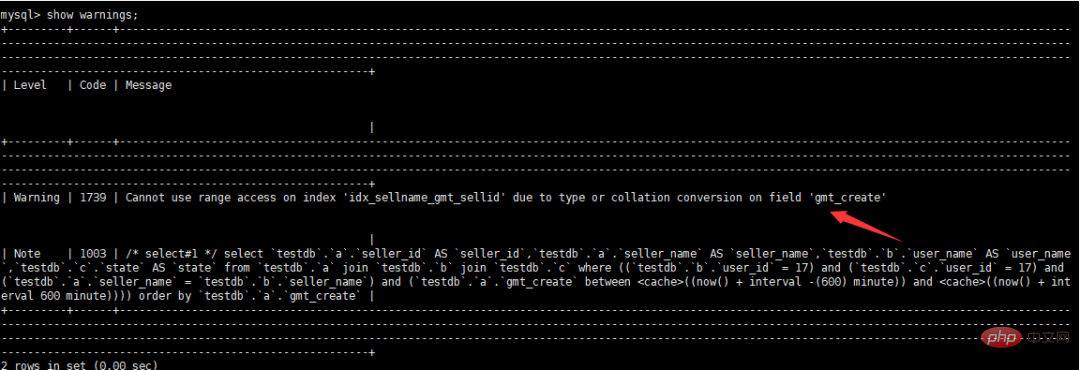
继续优化alter table a modify "gmt_create" datetime DEFAULT NULL;
查看执行时间

查看执行计划
总结
查看执行计划 explain
如果有告警信息,查看告警信息 show warnings;
查看SQL涉及的表结构和索引信息
根据执行计划,思考可能的优化点
按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
查看优化后的执行时间和执行计划
如果优化效果不明显,重复第四步操作
相关推荐:《mysql教程》
以上是用实例告诉你该如何优化SQL的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何优化Discuz论坛性能?
Mar 12, 2024 pm 06:48 PM
如何优化Discuz论坛性能?
Mar 12, 2024 pm 06:48 PM
如何优化Discuz论坛性能?引言:Discuz是一个常用的论坛系统,但在使用过程中可能会遇到性能瓶颈问题。为了提升Discuz论坛的性能,我们可以从多个方面进行优化,包括数据库优化、缓存设置、代码调整等方面。下面将介绍如何通过具体的操作和代码示例来优化Discuz论坛的性能。一、数据库优化:索引优化:为频繁使用的查询字段建立索引,可以大幅提升查询速度。例如
 如何优化SQL Server和MySQL的性能,让它们发挥最佳水平?
Sep 11, 2023 pm 01:40 PM
如何优化SQL Server和MySQL的性能,让它们发挥最佳水平?
Sep 11, 2023 pm 01:40 PM
如何优化SQLServer和MySQL的性能,让它们发挥最佳水平?摘要:在当今的数据库应用中,SQLServer和MySQL是两个最为常见和流行的关系型数据库管理系统(RDBMS)。随着数据量的增大和业务需求的不断变化,优化数据库性能变得尤为重要。本文将介绍一些优化SQLServer和MySQL性能的常见方法和技巧,以帮助用户利用
 Linux性能调优~
Feb 12, 2024 pm 03:30 PM
Linux性能调优~
Feb 12, 2024 pm 03:30 PM
Linux操作系统是一个开源产品,它也是一个开源软件的实践和应用平台。在这个平台下,有无数的开源软件支撑,如apache、tomcat、mysql、php等。开源软件的最大理念是自由和开放。因此,作为一个开源平台,linux的目标是通过这些开源软件的支持,以最低廉的成本,达到应用最优的性能。谈到性能问题,主要实现的是linux操作系统和应用程序的最佳结合。一、性能问题综述系统的性能是指操作系统完成任务的有效性、稳定性和响应速度。Linux系统管理员可能经常会遇到系统不稳定、响应速度慢等问题,例如
 Sybase与Oracle数据库管理系统的核心差异
Mar 08, 2024 pm 05:54 PM
Sybase与Oracle数据库管理系统的核心差异
Mar 08, 2024 pm 05:54 PM
Sybase与Oracle数据库管理系统的核心差异,需要具体代码示例数据库管理系统在现代信息技术领域中扮演着至关重要的角色,Sybase和Oracle作为两大知名的关系型数据库管理系统,在数据库领域中占据着重要地位。虽然它们都属于关系型数据库管理系统,但在实际应用中存在一些核心差异。本文将从多个角度对Sybase和Oracle进行比较,包括架构、语法、性能等
 sql中any是什么意思
May 01, 2024 pm 11:03 PM
sql中any是什么意思
May 01, 2024 pm 11:03 PM
SQL中的ANY关键词用于检查子查询是否返回任何满足给定条件的行:语法:ANY (subquery)用法:与比较运算符一起使用,如果子查询返回任何满足条件的行,则ANY表达式评估为true优点:简化查询,提高效率,适用于处理大量数据局限性:不提供满足条件的特定行,如果子查询返回多个满足条件的行,则只返回true
 SQL Server和MySQL性能调优:最佳实践与关键技巧。
Sep 11, 2023 pm 12:46 PM
SQL Server和MySQL性能调优:最佳实践与关键技巧。
Sep 11, 2023 pm 12:46 PM
SQLServer和MySQL性能调优:最佳实践与关键技巧摘要:本文将介绍SQLServer和MySQL两个常见的关系型数据库系统的性能调优方法,并提供一些最佳实践和关键技巧,以帮助开发人员和数据库管理员提高数据库系统的性能和效率。引言:在现代的应用开发中,数据库系统是不可或缺的一部分。随着数据量的增长和用户需求的增加,数据库性能的优化变得尤为重要。SQ
 MySql的SQL语句执行计划:如何优化MySQL的查询过程
Jun 16, 2023 am 09:15 AM
MySql的SQL语句执行计划:如何优化MySQL的查询过程
Jun 16, 2023 am 09:15 AM
随着互联网的快速发展,数据的存储和处理也变得越来越重要。因此,关系型数据库是现代软件平台中不可或缺的组成部分。MySQL数据库已经成为最受欢迎的关系型数据库之一,因为它使用简单,易于部署和管理。然而,在处理大量数据时,MySQL数据库的性能问题经常会成为问题。在本文中,我们将深入探讨MySQL的SQL语句执行计划,介绍如何通过优化查询过程来提高MySQL数据
 数据库搜索效果优化的Java技巧经验分享与总结
Sep 18, 2023 am 09:25 AM
数据库搜索效果优化的Java技巧经验分享与总结
Sep 18, 2023 am 09:25 AM
数据库搜索效果优化的Java技巧经验分享与总结摘要:数据库搜索是大多数应用程序中常见的操作之一。然而,当数据量庞大时,搜索操作可能变得缓慢,从而影响应用程序的性能和响应时间。本文将分享一些Java技巧,帮助优化数据库搜索效果,并提供具体的代码示例。使用索引索引是数据库中提高搜索效率的重要组成部分。在进行搜索操作之前,确保在需要搜索的列上创建了合适的索引。例如
