

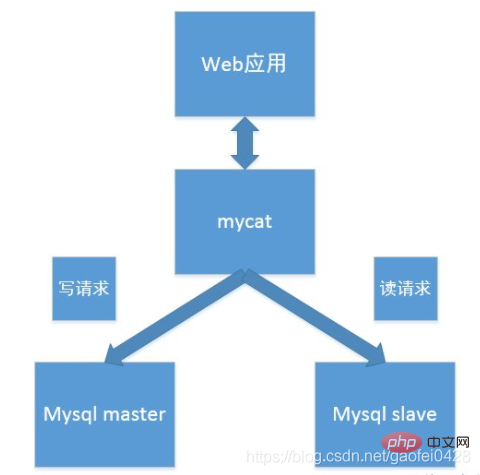
一起聊聊Mycat实现 Mysql 集群读写分离

本篇文章给大家介绍了关于MySQL读写分离的相关知识,希望对大家有帮助。

MySQL 读写分离的概述
MySQL 作为目前世界上使用最广泛的免费数据库,相信所有从事系统运维的工程师都一定接触过。
在实际的生产环境中,由单台 MySQL 作为独立的数据库是完全不能满足实际需求的,无论是在安全性,高可用性以及高并发等各个方面。
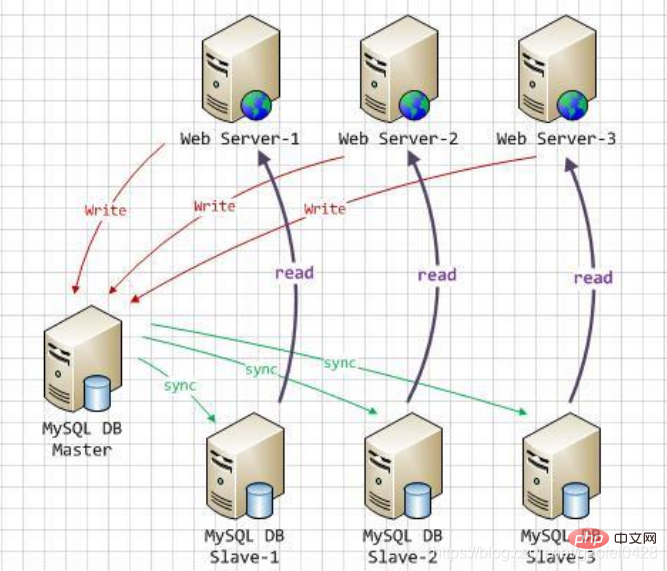
因此,一般来说都是通过主从复制(Master-Slave)的方式来同步数据,再通过读写分离(MySQL-Proxy/Amoeba)来提升数据库的并发负载能力进行部署与实施。
读写分离工作原理
基本的原理是:
主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE)
从数据库处理 SELECT 查询操作
数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
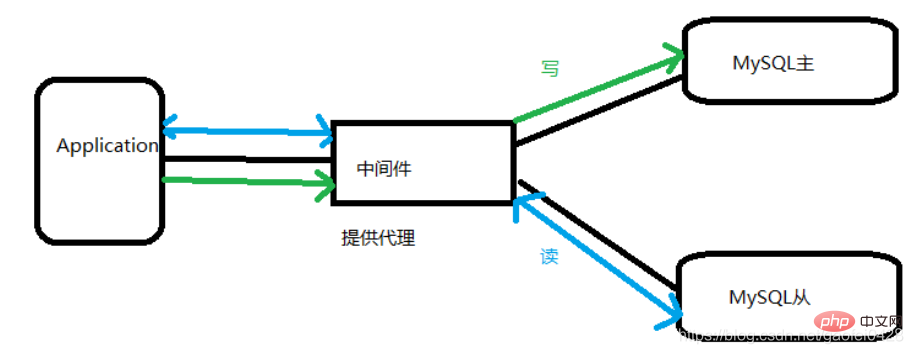
为什么要读写分离
面对越来越大的访问压力,单台的服务器的性能成为瓶颈,需要分担负载
主从只负责各自的写和读,极大程度的缓解 X(写)锁和 S(读)锁争用
从库可配置 myisam 引擎,提升查询性能以及节约系统开销
增加冗余,提高可用性
实现读写分离的方式
- 一般有两种方式实现
- 应用程序层实现,网站的程序实现
- 应用程序层实现指的是在应用程序内部及连接器中实现读写分离
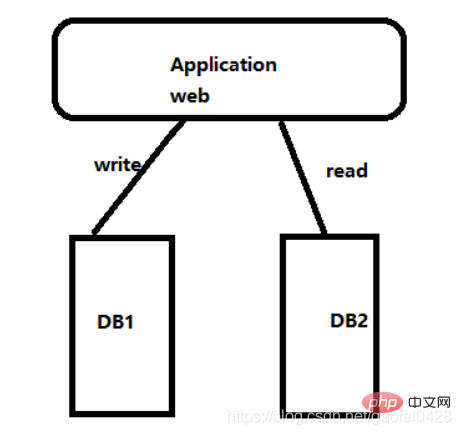
优点:
应用程序内部实现读写分离,安装既可以使用
减少一定部署难度
访问压力在一定级别以下,性能很好
缺点:
架构一旦调整,代码要跟着变
难以实现高级应用,如自动分库,分表
无法适用大型应用场景
中间件层实现:
中间件层实现是指在外部中间件程序实现读写分离
常见的中间件程序
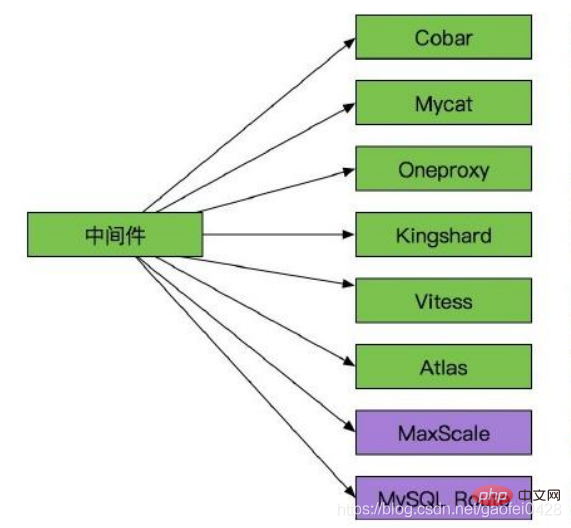
Cobar:
阿里巴巴 B2B 开发的关系型分布式系统,管理将近 3000 个 MySQL 实例。 在阿里经受住了考验,后面由于作者的走开的原因 cobar 没有人维护 了,阿里也开发了 tddl 替代 cobar。
MyCAT:
社区爱好者在阿里 cobar 基础上进行二次开发,解决了 cobar 当时存在的一些问题,并且加入了许多新的功能在其中。目前 MyCAT 社区活跃度很高,已经有一些公司在使用 MyCAT。总体来说支持度比
较高,也会一直维护下去。
OneProxy:
数据库界大牛,前支付宝数据库团队领导楼总开发,基于 mysql 官方 的 proxy 思想利用 c 进行开发的,OneProxy 是一款商业收费的中间件,楼总舍去了一些功能点,专注在性能和稳定性上。有人测
试过说在高并发下很稳定。
Vitess:
这个中间件是 Youtube 生产在使用的,但是架构很复杂。 与以往中间件不同,使用 Vitess 应用改动比较大,要使用他提供语言的 API 接口,我们可以借鉴他其中的一些设计思想。
Kingshard:
Kingshard 是前 360Atlas 中间件开发团队的陈菲利用业余时间 用 go 语言开发的,目前参与开发的人员有 3 个左右, 目前来看还不是成熟可以使用的产品,需要在不断完善。
Atlas:
360 团队基于 mysql proxy 把 lua 用 C 改写。原有版本是支持分表, 目前已经放出了分库分表版本。在网上看到一些朋友经常说在高并发下会经常挂掉,如果大家要使用需要提前做好测试。
MaxScale 与 MySQL Route:
这两个中间件都算是官方的,MaxScale 是 mariadb (MySQL 原作者维护的一个版本)研发的,目前版本不支持分库分表。MySQL Route 是现在 MySQL 官方 Oracle 公司发布出来的一个中间件。
优点:
架构设计更灵活
可以在程序上实现一些高级控制,如:透明化水平拆分,failover,监控可以依靠技术手段提高 mysql 性能对业务代码的影响小,同时也安全
缺点:
需要一定的开发运维团队的支持。
什么是 MyCAT
一个彻底开源的,面向企业应用开发的大数据库集群
支持事务、ACID、可以替代 MySQL 的加强版数据库
一个可以视为 MySQL 集群的企业级数据库,用来替代昂贵的 Oracle 集群
一个融合内存缓存技术、NoSQL 技术、HDFS 大数据的新型 SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
MyCat 服务安装与配置
MyCat 有提供编译好的安装包,支持 Windows、Linux、Mac、Solaris 等系统上安装与运行
官方下载主页 http://www.mycat.org.cn/

- 实验架构:
- 192.168.2.2 Mycat CentOS 8.3.2011
- 192.168.2.3 主服务器 CentOS 7.6
- 192.168.2.5 从服务器 CentOS 7.6
- 运行 Mycat 需要JDK 1.7 或者以上版

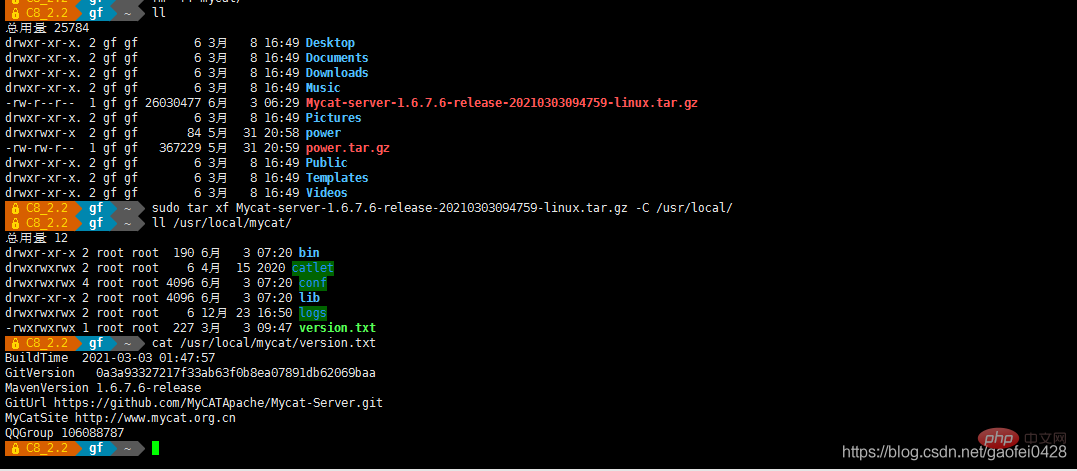
- 下载 Mycat
- wget http://dl.mycat.org.cn/1.6.7.6/20210303094759/Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz
- tar xf Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz -C /usr/local/
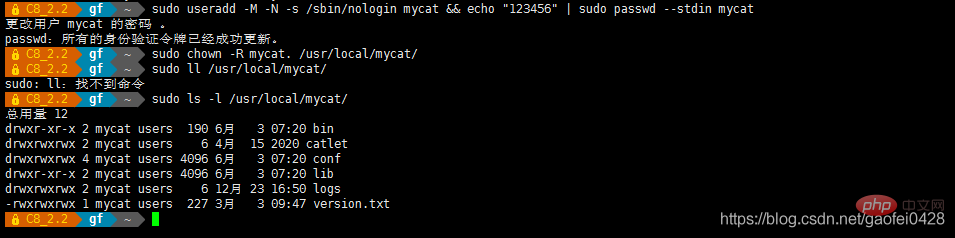
- sudo useradd -M -N -s /sbin/nologin mycat && echo "123456" | sudo passwd --stdin mycat
- sudo chown -R mycat. /usr/local/mycat/

- bin 程序目录,Linux 下运行:./mycat console,首先要 chmod +x *
注:mycat 支持的命令{ console | start | stop | restart | status | dump }
conf 目录下存放配置文件:server.xml 是 Mycat 服务器参数调整和用户授权的配置文件,schema.xml 是逻辑库定义和表以及分片定义的配置文件,rule.xml 是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录下,配置文件修改,需要重启 Mycat 生效。
lib 目录下主要存放 mycat 依赖的一些 jar 文件。
日志存放在 logs/mycat.log 中,每天一个文件,日志的配置是在 conf/log4j.xml 中,根据自己的需要,可以调整输出级别为 debug,在 debug 级别下,会输出更多的信息,方便排查问题。
MyCat 服务启动与启动设置
MyCAT 在 Linux 中部署启动时,首先需要在 Linux 系统的环境变量中配置 MYCAT_HOME,操作方式如下:
sudo vim /etc/profile.d/mycat.sh
MYCAT_HOME=/usr/local/mycat PATH=$MYCAT_HOME/bin:$PATH使环境变量生效
. /etc/profile.d/mycat.sh

- 启动服务
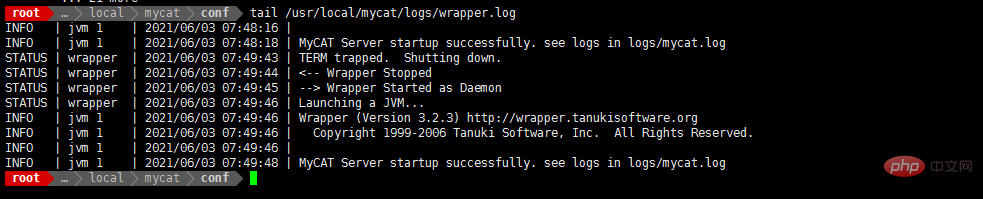
- /usr/local/mycat/bin/mycat start
- cat /usr/local/mycat/logs/wrapper.log

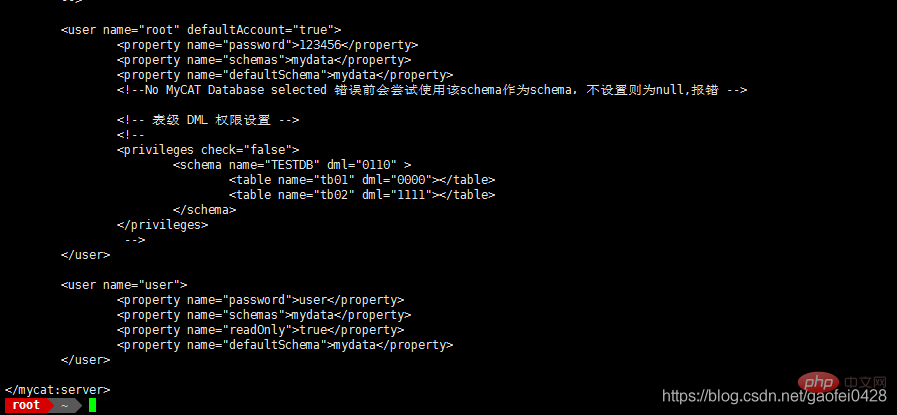
mycat 的用户账号和授权信息是在 conf/server.xml 文件中配置
vim /usr/local/mycat/conf/server.xml
这里定义的是在 192.168.2.2 上登陆 mycat 的用户名和密码,名称可以自定义。192.168.2.2 上没有运行 mysqld 服务,schemas里面指定的数据库名是服务器端必须存在的数据库!
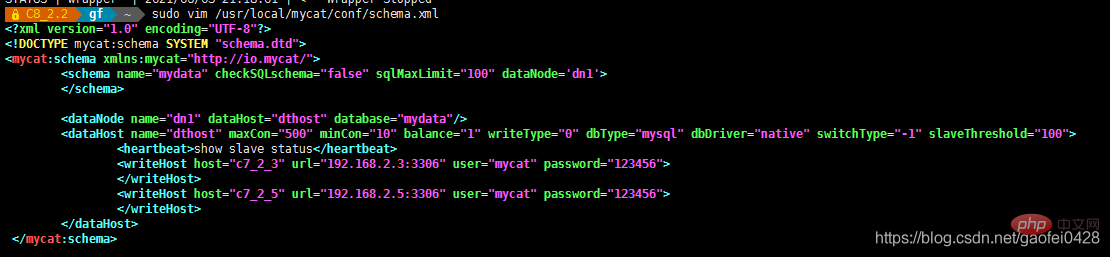
编辑 MyCAT 的配置文件 schema.xml,关于 dataHost 的配置信息如下:
- 备份原先的配置文件
- \cp /usr/local/mycat/conf/schema.xml{,.bak}
- 编辑 配置文件
-
vim /usr/local/mycat/conf/schema.xml
balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
show slave status
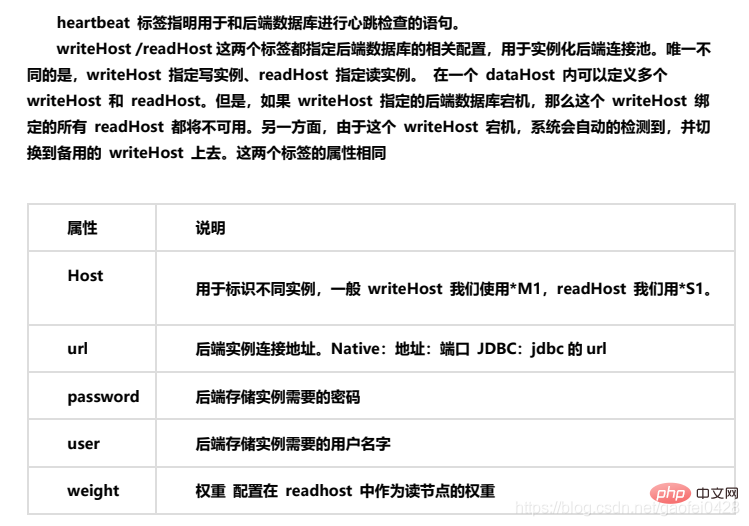
写服务器
读服务器
强制所有的读操作都在读服务器上运行,只有写入数据时才切换到写服务器
注意这里的 mycat 用户都要在 主从数据库 上 192.168.2.3 和 2.5 授权
GRANT ALL PRIVILEGES ON *.* TO 'mycat'@'%' IDENTIFIED BY '123456';
或者指定网段
GRANT ALL PRIVILEGES ON *.* TO 'mycat'@'192.168.2.%' IDENTIFIED BY '123456';
flush privileges;
如果报这个错误,服务器运行正常的话,首先检查有没有授权
ERROR 1184 (HY000): Invalid DataSource:0

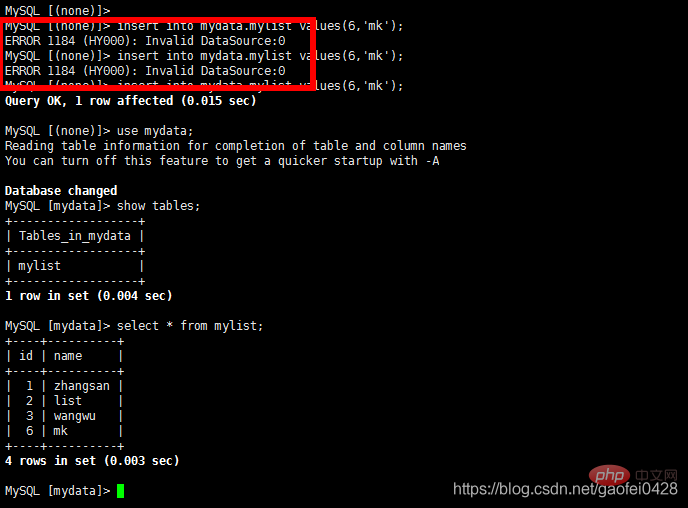
schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode,这是通过表格的分片规则定义来实现的,table可以定义其所属的“子表(childTable)”,子表的分片依赖于与“父表”的具体分片地址,简单的说,就是属于父表里某一条记录A的子表的所有记录都与A存储在同一个分片上。
分片规则:是一个字段与函数的捆绑定义,根据这个字段的取值来返回所在存储的分片(DataNode)的序号,每个表格可以定义一个分片规则,分片规则可以灵活扩展,默认提供了基于数字的分片规则,字符串的分片规则等。
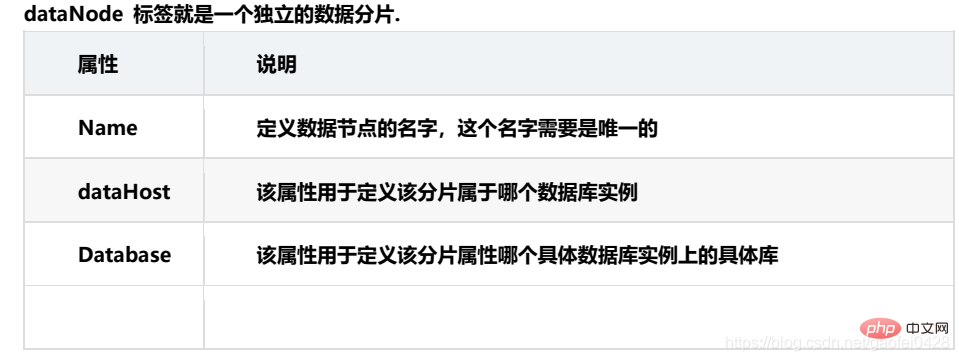
dataNode: MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上,一般来说,为了高可用性,每个DataNode都设置两个DataSource,一主一从,当主节点宕机,系统自动切换到从节点。
dataHost:定义某个物理库的访问地址,用于捆绑到dataNode上。
MyCAT目前通过配置文件的方式来定义逻辑库和相关配置:
MYCAT_HOME/conf/schema.xml中定义逻辑库,表、分片节点等内容;
MYCAT_HOME/conf/rule.xml中定义分片规则;
MYCAT_HOME/conf/server.xml中定义用户以及系统相关变量,如端口等。
注解:
schema 标签用于定义 MyCat 实例中的逻辑库,name:后面就是逻辑库名 MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。
checkSQLschema 这个属性默认就是 false,官方文档的意思就是是否去掉表前面的数据库的名称,”select * from db1.testtable” ,设置为 true 就会去掉 db1。但是如果 db1 的名称不是
schema 的名称,那么也不会被去掉,因此官方建议不要使用这种语法。同时默认设置为 false。
sqlMaxLimit 当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句,MyCat 也会自动的加上所对应的值。例如设置值为 100,执行”select * from test_table”,则效果为
“selelct * from test_table limit 100”.
dataNode 标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片




- 重新启动服务
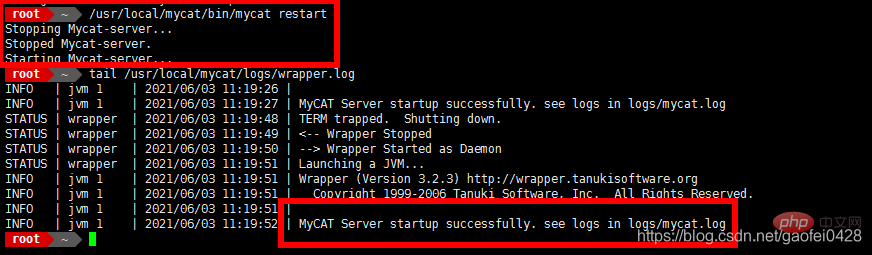
- /usr/local/mycat/bin/mycat restart
Stopping Mycat-server...
Stopped Mycat-server.
Starting Mycat-server...
tail /usr/local/mycat/logs/wrapper.log
配置 MySQL 主从
- 在2台服务器上分别安装、配置mariadb,具体步骤请参阅:https://blog.csdn.net/gaofei0428/article/details/103829676?spm=1001.2014.3001.5501
首先在主数据库端 192.168.2.3 编辑 /etc/my.cnf
- /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-bin=/data/mysql/mysql-bin
server-id=1
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
binlog-ignore-db=test
innodb_flush_log_at_trx_commit=1
binlog-do-db=mydata
replicate-do-db=mydata - lower_case_table_names=1 开启大小写匹配
- 注意需要同步的数据库必须事先存在
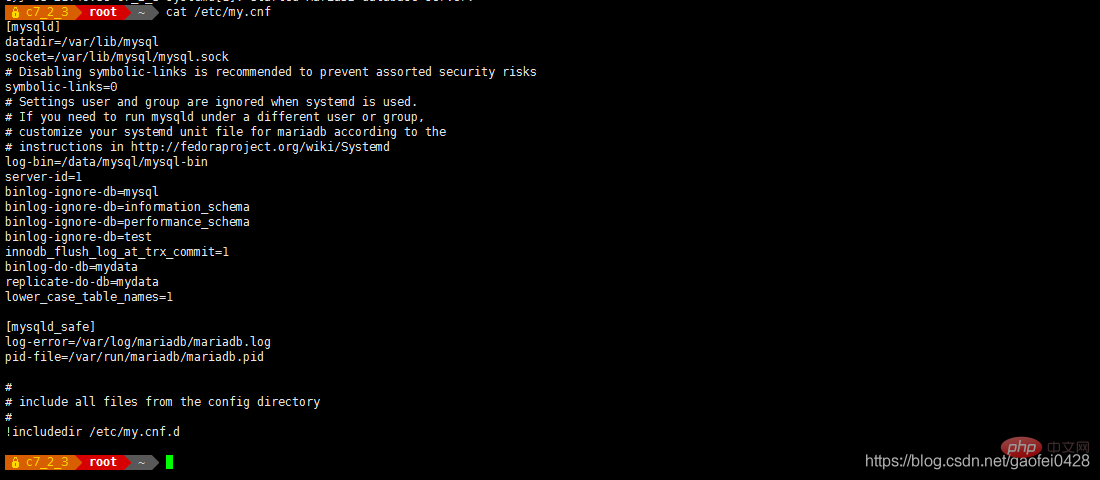

启动无误后在然后在从服务器 192.168.2.5 上配置 /etc/my.cnf
- vim /etc/my.cnf 1
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-bin=/data/mysql/mysql-bin
server-id=2
relay-log-index=/data/mysql/slave-relay-bin.index
relay-log=/data/mysql/slave-relay-bin
lower_case_table_names=1 - read_only=1 开启只读模式,防止数据回写,不会影响 slave 同步复制
- lower_case_table_names=1 开启大小写匹配
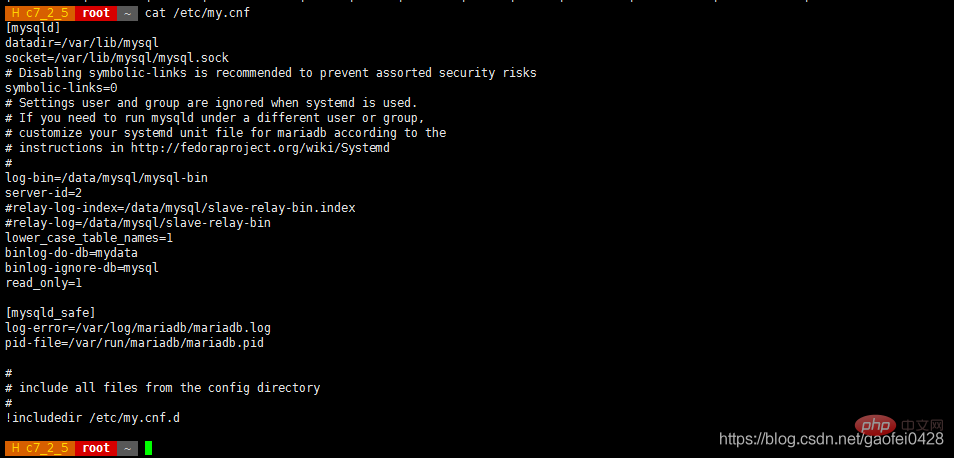
- 重启 从数据库服务后进行以下操作
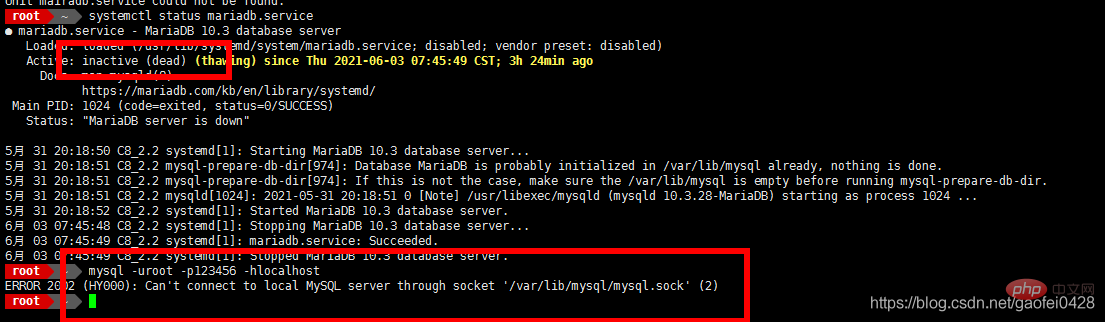
- 停止从服务器的slave,创建slave数据库用户
- mysql -uroot -p123456 -e "stop slave"
mysql -uroot -p123456 -e "grant replication slave on *.* to 'slave'@'%' identified by '123456'"
mysql -uroot -p123456 -e "select user,password from mysql.user"

- mysql -uroot -p123456 -e "change master to master_host='192.168.2.3',master_user='slave',master_password='123456',master_log_file='mysql-bin.000002',master_log_pos=245;"
mysql -uroot -p123456 -e "start slave"
mysql -uroot -p123456 -e "show slave status"

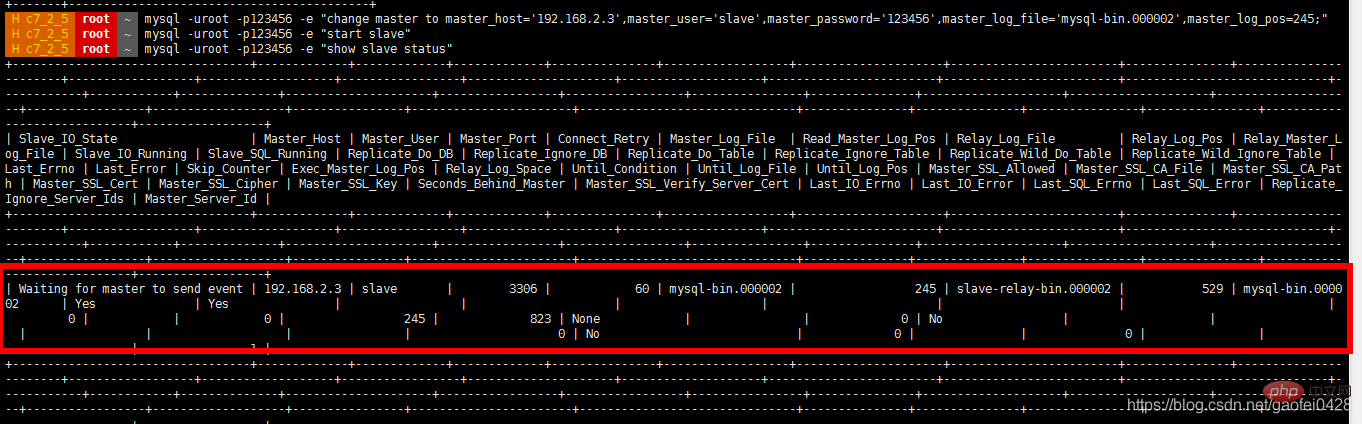
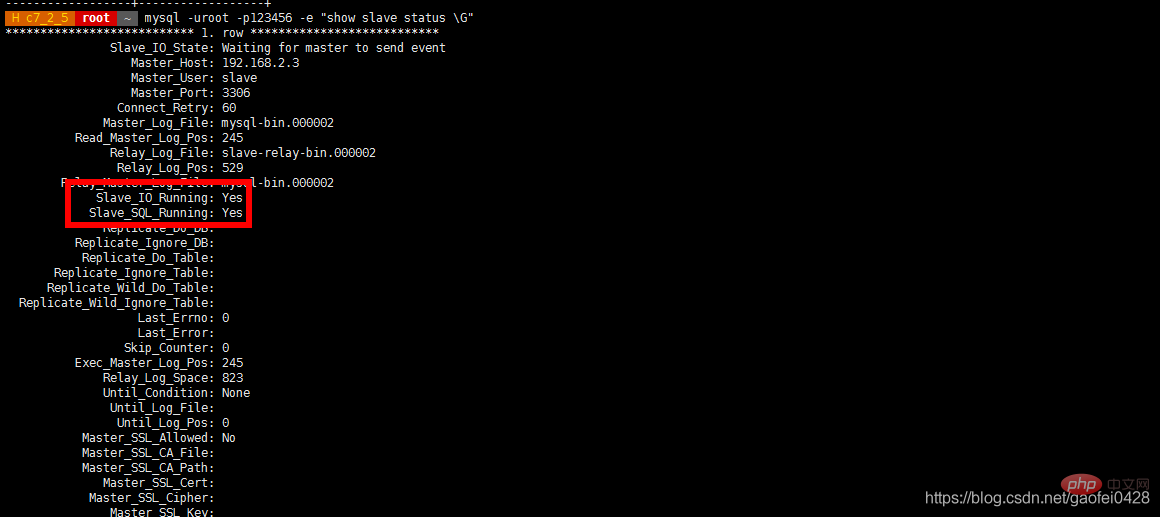
测试
首先导出主服务器 192.168.2.3 的所有库的备份
mysqldump -uroot -p --all-databases > /tmp/all_dbs.sql
然后在从服务器 192.168.2.5 导入
mysql -uroot -p < /tmp/all_dbs.sql
- 在主数据库端 192.168.2.3 添加一些数据,观测从数据库是否同步
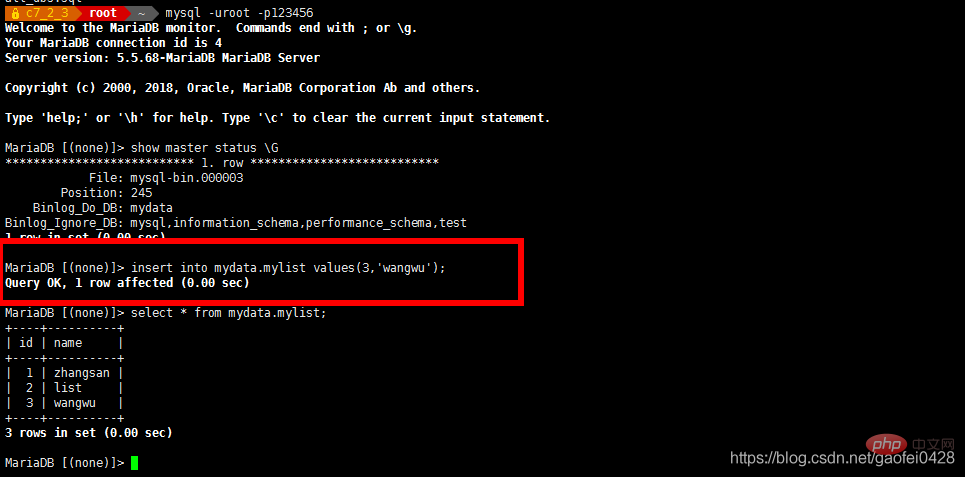
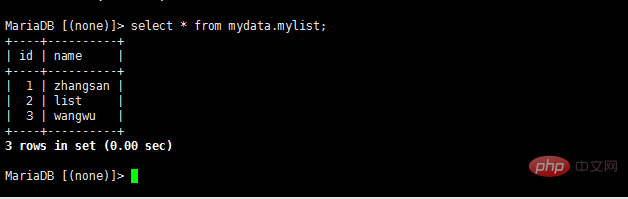
- 在从服务器端查看
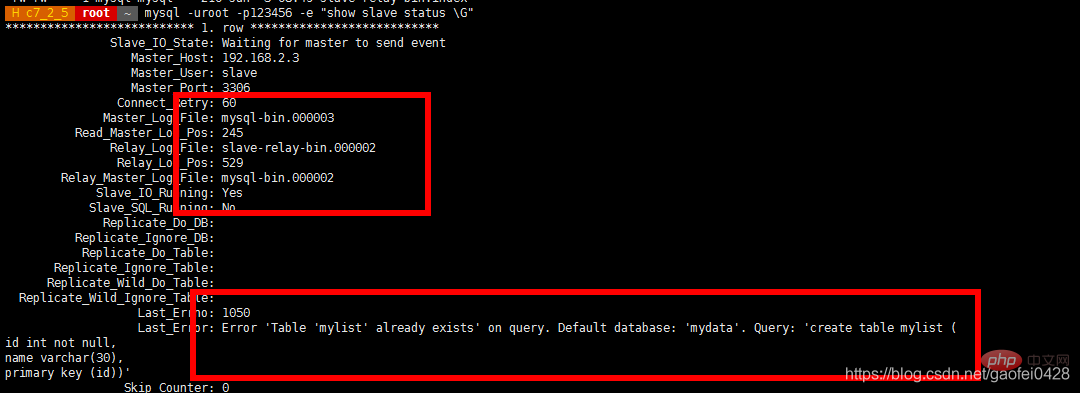
- 如果同步出错,需要在从服务器 stop slave,然后重新 change master
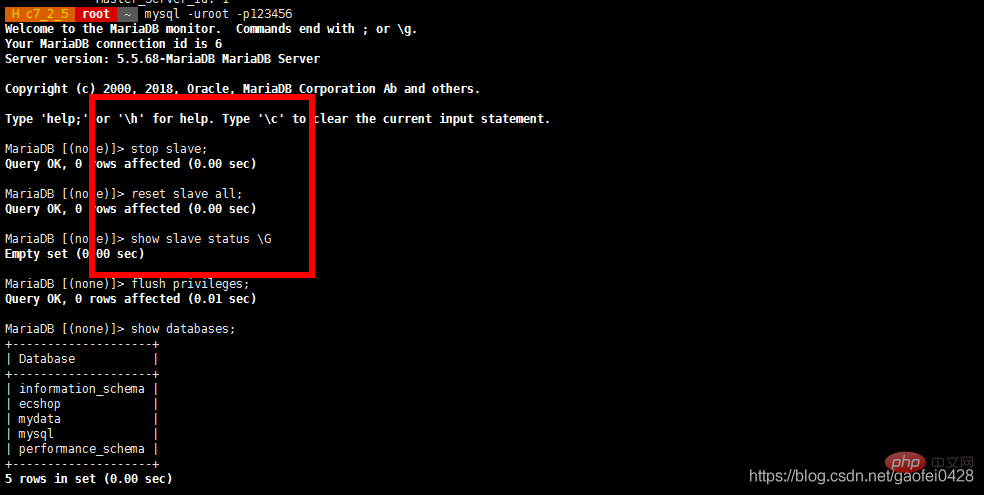

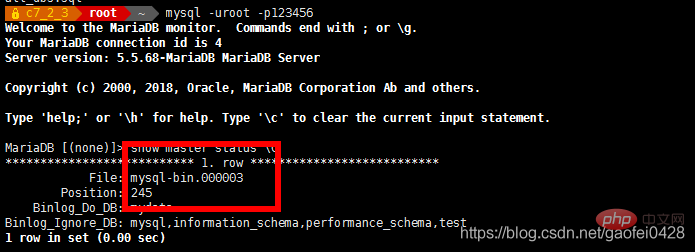
- 使用 slave 用户登陆测试
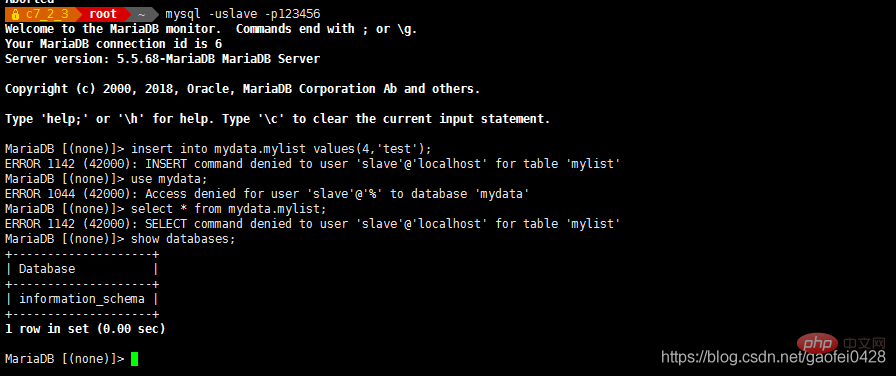
回到 mycat 服务器 192.168.2.2
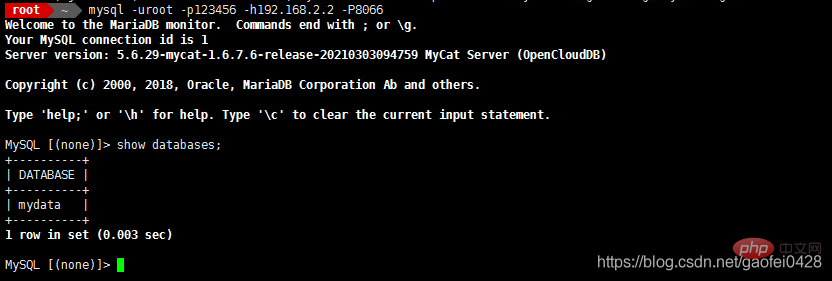
- 尝试登陆
- mysql -uroot -p123456 -h192.168.2.2 -P8066
- 8066 为 mycat 运行时的端口号

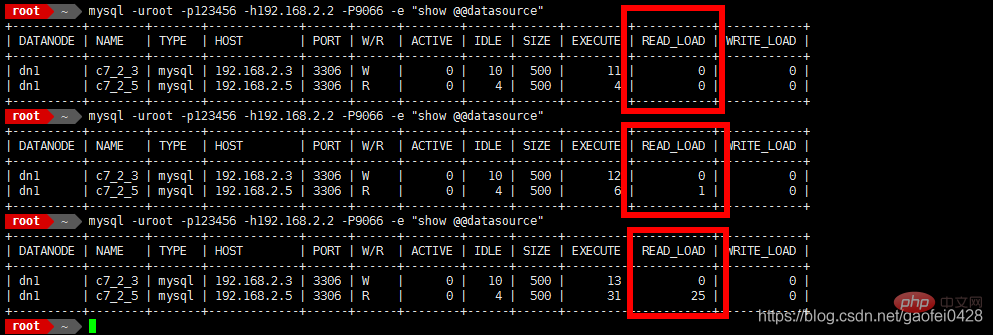
测试读写分离
- mysql -uroot -p123456 -h192.168.2.2 -P9066 -e "show @@datasource"
- 9066为 mycat 管理端口
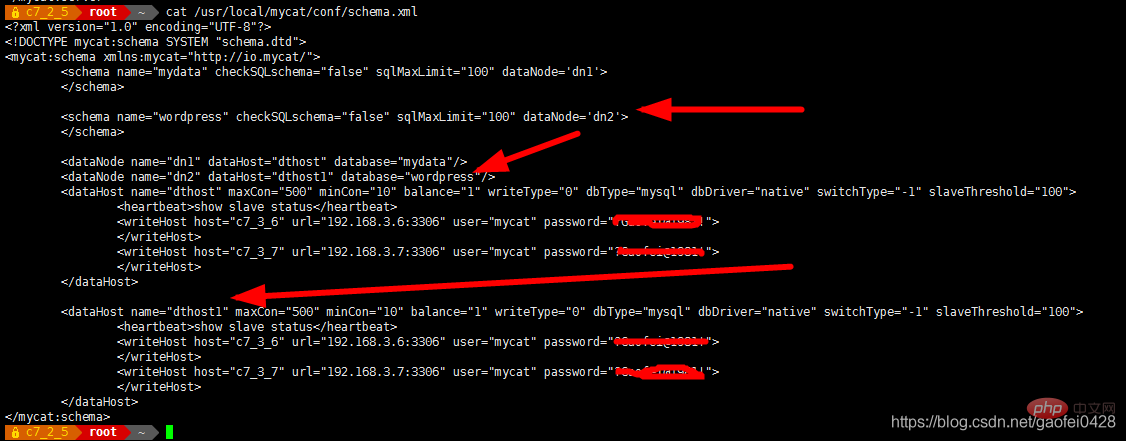
- select * from mydata.mylist;
写入数据或者更改数据
- insert into mydata.mylist values(10,'test');

模拟故障,首先停止 从服务器 192.168.2.5
- systemctl stop mariadb.service

- 在 192.168.2.2 上尝试写入数据
- insert into mydata.mylist values(7,'gf');
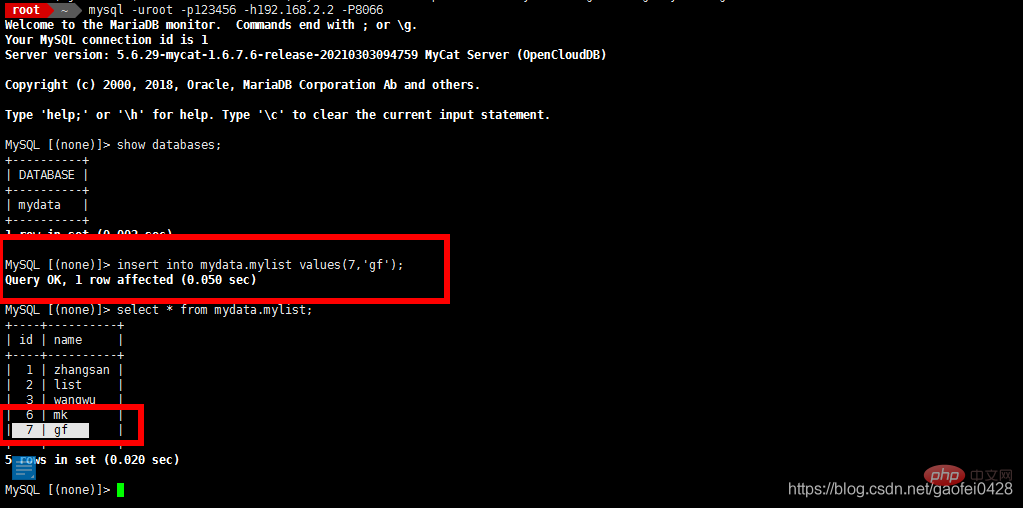
- 在 主服务器 192.168.2.3 上查看
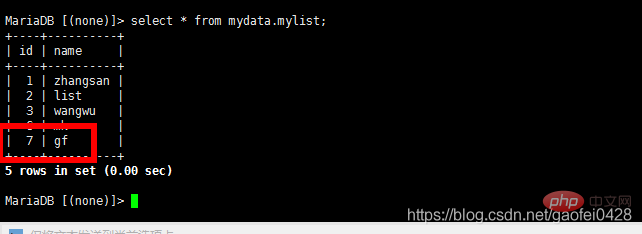
- 开启 从服务器 192.168.2.5
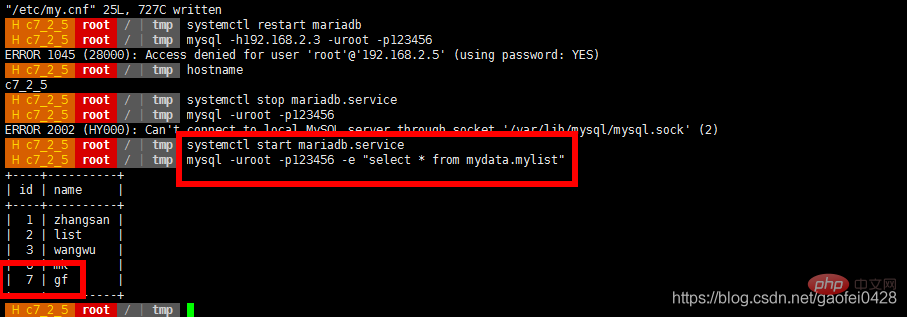
- 模拟 主服务器 192.168.2.3 宕机
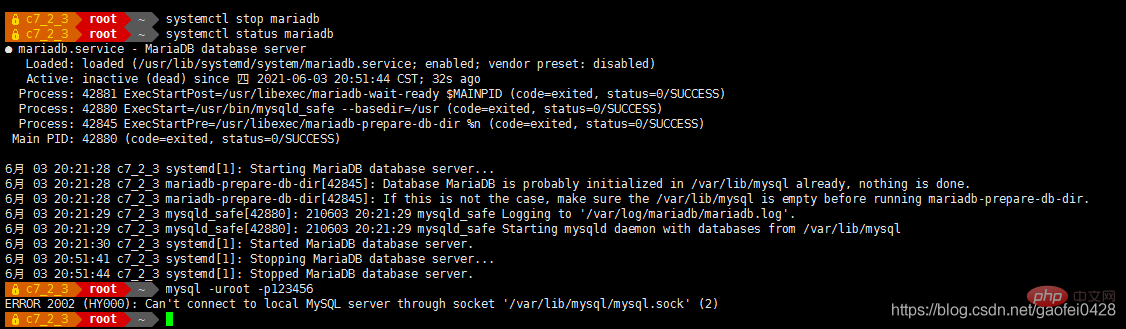
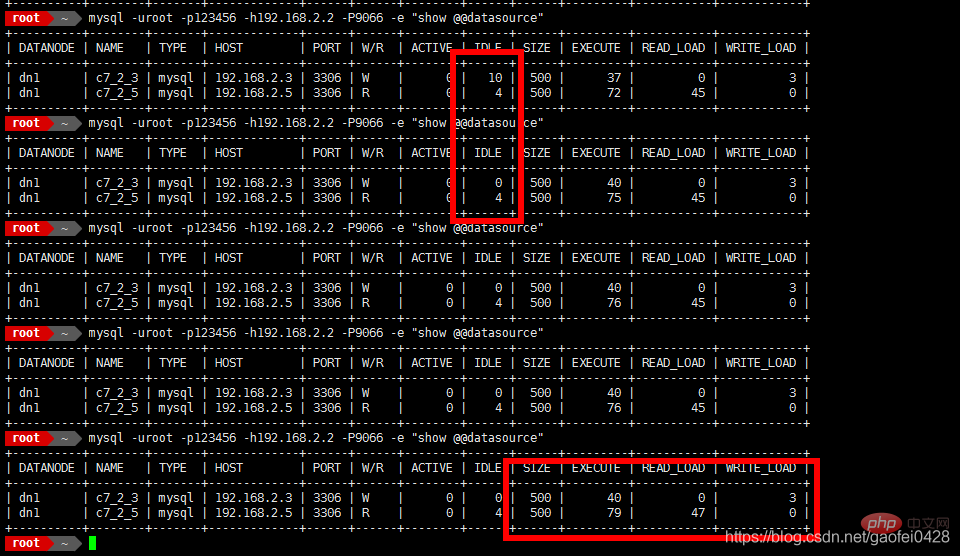
- 查询正常,尝试写入数据
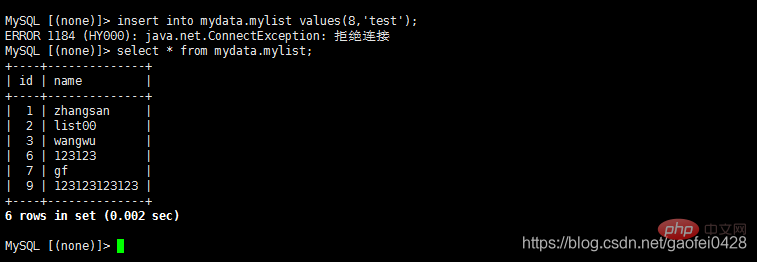
- 查询正常但是不能写入
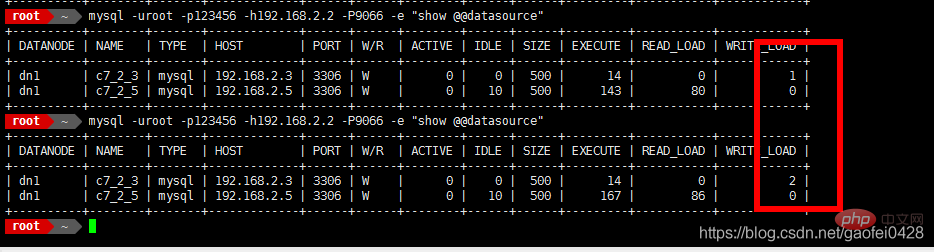
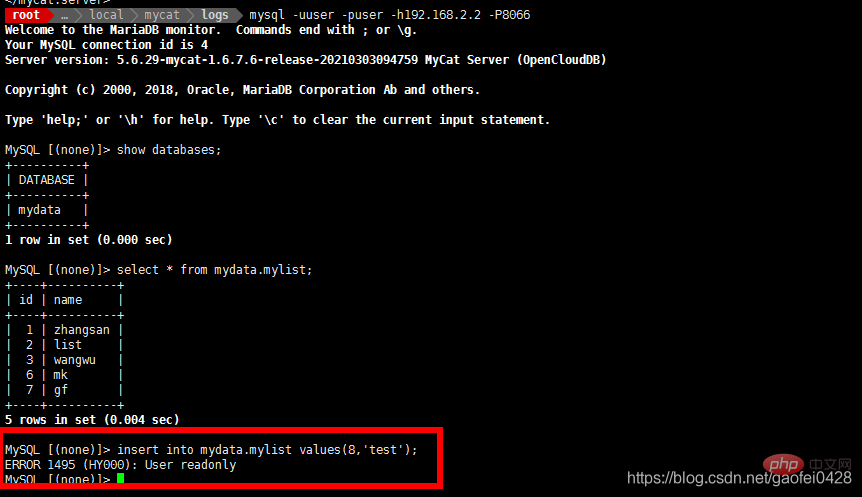
- 添加多个库
- vim cat /usr/local/mycat/conf/server.xml
-
mydata,wordpress
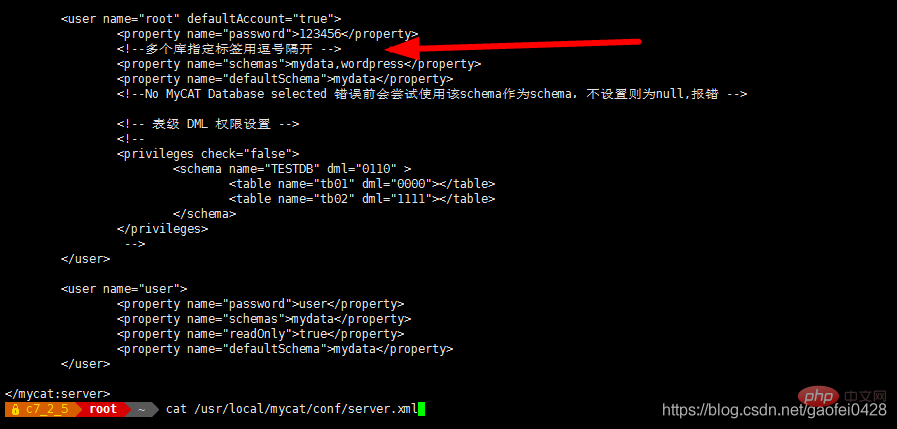
- vim /usr/local/mycat/conf/schema.xml
-
- 添加完重启服务
- /usr/local/mycat/bin/mycat restart
- tail /usr/local/mycat/logs/wrpper.log

- 报错处理
Startup failed: Timed out waiting for a signal from the JVM.
JVM did not exit on request, terminated
解决办法
在wrapper.conf中添加
wrapper.startup.timeout=300 //超时时间300秒
wrapper.ping.timeout=120
推荐学习:mysql视频教程
以上是一起聊聊Mycat实现 Mysql 集群读写分离的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 mysql:简单的概念,用于轻松学习
Apr 10, 2025 am 09:29 AM
mysql:简单的概念,用于轻松学习
Apr 10, 2025 am 09:29 AM
MySQL是一个开源的关系型数据库管理系统。1)创建数据库和表:使用CREATEDATABASE和CREATETABLE命令。2)基本操作:INSERT、UPDATE、DELETE和SELECT。3)高级操作:JOIN、子查询和事务处理。4)调试技巧:检查语法、数据类型和权限。5)优化建议:使用索引、避免SELECT*和使用事务。
 phpmyadmin怎么打开
Apr 10, 2025 pm 10:51 PM
phpmyadmin怎么打开
Apr 10, 2025 pm 10:51 PM
可以通过以下步骤打开 phpMyAdmin:1. 登录网站控制面板;2. 找到并点击 phpMyAdmin 图标;3. 输入 MySQL 凭据;4. 点击 "登录"。
 MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL是一种开源的关系型数据库管理系统,主要用于快速、可靠地存储和检索数据。其工作原理包括客户端请求、查询解析、执行查询和返回结果。使用示例包括创建表、插入和查询数据,以及高级功能如JOIN操作。常见错误涉及SQL语法、数据类型和权限问题,优化建议包括使用索引、优化查询和分表分区。
 为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
选择MySQL的原因是其性能、可靠性、易用性和社区支持。1.MySQL提供高效的数据存储和检索功能,支持多种数据类型和高级查询操作。2.采用客户端-服务器架构和多种存储引擎,支持事务和查询优化。3.易于使用,支持多种操作系统和编程语言。4.拥有强大的社区支持,提供丰富的资源和解决方案。
 redis怎么使用单线程
Apr 10, 2025 pm 07:12 PM
redis怎么使用单线程
Apr 10, 2025 pm 07:12 PM
Redis 使用单线程架构,以提供高性能、简单性和一致性。它利用 I/O 多路复用、事件循环、非阻塞 I/O 和共享内存来提高并发性,但同时存在并发性受限、单点故障和不适合写密集型工作负载的局限性。
 MySQL和SQL:开发人员的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL:开发人员的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL是开发者必备技能。1.MySQL是开源的关系型数据库管理系统,SQL是用于管理和操作数据库的标准语言。2.MySQL通过高效的数据存储和检索功能支持多种存储引擎,SQL通过简单语句完成复杂数据操作。3.使用示例包括基本查询和高级查询,如按条件过滤和排序。4.常见错误包括语法错误和性能问题,可通过检查SQL语句和使用EXPLAIN命令优化。5.性能优化技巧包括使用索引、避免全表扫描、优化JOIN操作和提升代码可读性。
 MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL在数据库和编程中的地位非常重要,它是一个开源的关系型数据库管理系统,广泛应用于各种应用场景。1)MySQL提供高效的数据存储、组织和检索功能,支持Web、移动和企业级系统。2)它使用客户端-服务器架构,支持多种存储引擎和索引优化。3)基本用法包括创建表和插入数据,高级用法涉及多表JOIN和复杂查询。4)常见问题如SQL语法错误和性能问题可以通过EXPLAIN命令和慢查询日志调试。5)性能优化方法包括合理使用索引、优化查询和使用缓存,最佳实践包括使用事务和PreparedStatemen
 SQL删除行后如何恢复数据
Apr 09, 2025 pm 12:21 PM
SQL删除行后如何恢复数据
Apr 09, 2025 pm 12:21 PM
直接从数据库中恢复被删除的行通常是不可能的,除非有备份或事务回滚机制。关键点:事务回滚:在事务未提交前执行ROLLBACK可恢复数据。备份:定期备份数据库可用于快速恢复数据。数据库快照:可创建数据库只读副本,在数据误删后恢复数据。慎用DELETE语句:仔细检查条件,避免误删数据。使用WHERE子句:明确指定要删除的数据。使用测试环境:在执行DELETE操作前进行测试。
