
docker进行隔离的资源:1、文件系统;2、网络(Network);3、进程间的通信;4、针对权限的用户和用户组;5、进程内的PID和宿主机的PID;6、主机名与域名等。

本教程操作环境:linux5.9.8系统、docker-1.13.1版、Dell G3电脑。
docker容器的本质是宿主机上的一个进程。
Docker通过namespace实现了资源隔离,通过cgroups实现了资源限制,通过*写时复制机制(copy-on-write)*实现了高效的文件操作。
namespace 机制提供一种资源隔离方案。
PID,IPC,Network等系统资源不再试全局性的,而是属于某个特定的Namespace.
每个namespace下的资源对于其他的namespace下的资源是透明的,不可见的。
Linux 内核实现namespace的一个主要目的就是实现轻量级虚拟化(容器)服务,在同一个namespace下的进程可以感知彼此的变化,而对外界的进程一无所知,以达到独立和隔离的目的。
namespace可以隔离哪些
一个容器要想与其他容器互不干扰需要能够做到:
文件系统需要是被隔离的
网络也是需要被隔离的
进程间的通信也要被隔离
针对权限,用户和用户组也需要隔离
进程内的PID也需要与宿主机中的PID进行隔离
容器也要有自己的主机名
有了以上的隔离,我们认为一个容器可以与宿主机和其他容器是隔离开的。
恰巧Linux 的namespace可以做到这些。
| namespace | 隔离内容 | 系统调用参数 |
|---|---|---|
| UTS | 主机名与域名 | CLONE_NEWUTS |
| IPC | 信号量、消息队列和共享内存 | CLONE_NEWIPC |
| Network | 网络设备、网络栈、端口等 | CLONE_NEWNET |
| PID | 进程编号 | CLONE_NEWPID |
| Mount | 挂载点(文件系统) | CLONE_NEWNS |
| User | 用户和用户组 | CLONE_NEWUSER |
UTS namespace
UTS (UNIX TIme-sharing System) namespace 提供了主机和域名的隔离,这样每个Docker容器就可以拥有独立的主机名和域名,在网络上可以被视作一个独立的节点,而不是宿主机上的一个进程。
Docker中,每个镜像基本都以自身提供的服务名称来命名hostname,且不会对宿主机产生任何影响。
IPC namespace
进程间通信(Inter-Process Communication,IPC)设计的IPC资源包括常见的信号量、消息队列和共享内存。
申请IPC资源就申请了一个全局唯一的32位ID。
IPCnamespace中包含了系统IPC标识符以及实现POSIX消息队列的文件系统。
在同一个IPC namespace中的进程彼此可见,不同的namespace中的进程则互不可见。
PID namespace
PID namespace的隔离非常实用,他对进程PID重新编号,即两个不同namespace下的进程可以拥有相同的PID,每个PID namespace都有自己的计数程序。
内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,被称为root namespace。新创建的PIDnamespace被称为child namespace,而原先的PID namespace就是新创建的PID namespace的child namespace,而原来的PID namespace就是新创建的PID namespace的 parent namespace。
通过这种方式,不同的PID namespace会形成=一个层级体系,所属的父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。但是子节点确看不到父节点PID namespace中的任何内容。
mount namespace
mount namespace通过隔离文件系统挂载点对隔离文件系统提供支持。
隔离后,不同的mount namespace中的文件结构发生变化也互不影响。
network namespace
network namespace主要提供了关于网络资源的隔离,包括网络设备,IPv4,IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、套接字等。
user namespace
user namespace隔离了安装相关的标识符和属性
namespace的操作
namespace的API包括clone() setns() unshare() 还有/proc下的部分文件
为了确定隔离的是那些namespace,需要指定以下6个参数的一个或多个 | 进行分隔。6个参数就是上面表中提到的CLONE_NEWUTS、CLONE_NEWIPC、CLONE_NEWPID、CLONE_NEWNET、CLONE_NEWUSER
clone()
使用clone() 来创建一个独立namespace的进程,是最常见的做法,也是Docker使用namespace最基本的方法。
int clone(int(*child_func)(void *),void *child_stack,int flags, void *arg);
clone() 是 Linux 系统调用fork() 的一种更通用的实现方式,可以通过flags来控制使用多少功能。
共有20多种CLONE_*的flag,控制clone进程的方方面面。
/proc/[pid]/ns
用户可以在/proc/[pid]/ns文件下看到指向不同namespace好的文件。
ls -l /proc/10/ns
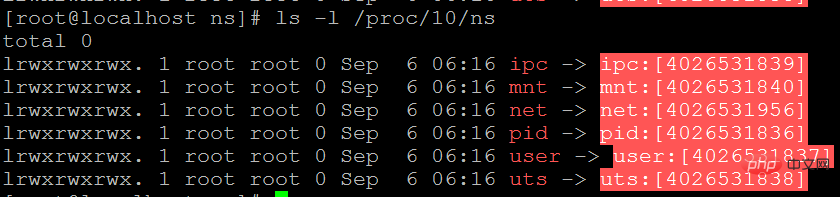
中括号内的为namespace号
如果两个进程指向的namespace号相同,那么说明他们在同一个namespace
设置link的作用是,即便该namespace下的所有进程都已经结束,这个namespace也会一直存在,后续的进程可以加入进来。
把/proc/[pid]/ns目录文件使用 --bind方式挂载也可以达到link的作用
touch ~/utsmount --bind /proc/10/ns/uts ~/uts
setns()
Docker中 使用 docker exec命令在已经运行着的命令执行一个新的命令就需要使用setns() 。
通过setns()系统调用,进程从原来的的namespace加入某个已经存在的namespace
通常为了不影响进程的调用者,也为了使新加入的pid namespace生效,会在setns()函数执行后使用clone() 创建子进程继续执行命令,让原先的进程结束运行。
int setns(int fd, in nstype); #fd 表示要加入namespace的文件描述符。是一个指向/proc/[pid]/ns目录的文件描述符,打开目录链接可以获得 #nstype 调用者可以检查fd指向的namespace类型是否符合实际要求,该参数为0则不检查
为了把新加入的namespace利用起来,需要引入execve()系列函数,该函数可以执行用户命令,常用的就是调用/bin/bash并接受参数
unshare()
通过unshare() 在原先的进程上namespace隔离
unshare与clone很像,unshare不需要新启动一个进程,在原有的进程上就可以进行使用。
docker并没有使用
fork() 系统调用
fork并不属于namespace的API
cgroups是Linux内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源分等级的不同组内,从而为系统资源管理提供一个统一的框架。
cgroups是Linux的另外一个强大的内核工具,有了cgroups,不仅可以限制被namespace隔离起来的资源,还可以为资源设置权重、计算使用量、操控任务(进程或县城)启停等。说白了就是:cgroups可以限制、记录任务组所使用的物理资源(包括CPU,Memory,IO等),是构建Docker等一系列虚拟化管理工具的基石。
cgroups 的作用
cgroups 为不同用户层面的资源管理提供了一个统一接口,从单个的资源控制到操作系统层面的虚拟化,cgroups提供了4大功能。
推荐学习:《docker视频教程》
以上是docker对哪些资源进行隔离的详细内容。更多信息请关注PHP中文网其他相关文章!























