

Redis实现分布式锁需要注意什么?【注意事项总结】

Redis实现分布式锁需要注意什么?下面本篇文章就来给大家总结分享一些使用Redis作为分布式锁的注意点,希望对大家有所帮助!

Redis实现分布式锁
最近看分布式锁的过程中看到一篇不错的文章,特地的加工一番自己的理解:
Redis分布式锁实现的三个核心要素:
1.加锁
最简单的方法是使用setnx命令。key是锁的唯一标识,按业务来决定命名,value为当前线程的线程ID。【相关推荐:Redis视频教程】
比如想要给一种商品的秒杀活动加锁,可以给key命名为 “lock_sale_ID” 。而value设置成什么呢?我们可以姑且设置成1。加锁的伪代码如下:
setnx(key,1)当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁,当其他线程执行setnx返回0,说明key已经存在,该线程抢锁失败。
2.解锁
有加锁就得有解锁。当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式是执行del指令,伪代码如下:
del(key)释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3.锁超时
锁超时是什么意思呢?如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程再也别想进来。
所以,setnx的key必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放。setnx不支持超时参数,所以需要额外的指令,伪代码如下:
expire(key, 30)综合起来,我们分布式锁实现的第一版伪代码如下:
if(setnx(key,1) == 1){
expire(key,30)
try {
do something ......
}catch() { } finally {
del(key)
}
}因为上面的伪代码中,存在着三个致命问题:
1. setnx和expire的非原子性
设想一个极端场景,当某线程执行setnx,成功得到了锁:
setnx刚执行成功,还未来得及执行expire指令,节点1 Duang的一声挂掉了。
if(setnx(key,1) == 1){ //此处挂掉了.....
expire(key,30)
try {
do something ......
}catch()
{
}
finally {
del(key)
}
}这样一来,这把锁就没有设置过期时间,变得“长生不老”,别的线程再也无法获得锁了。
怎么解决呢?setnx指令本身是不支持传入超时时间的,Redis 2.6.12以上版本为set指令增加了可选参数,伪代码如下:set(key,1,30,NX),这样就可以取代setnx指令。
2. 超时后使用del 导致误删其他线程的锁
又是一个极端场景,假如某线程成功得到了锁,并且设置的超时时间是30秒。
如果某些原因导致线程A执行的很慢很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁。
随后,线程A执行完了任务,线程A接着执行del指令来释放锁。但这时候线程B还没执行完,线程A实际上删除的是线程B加的锁。
怎么避免这种情况呢?可以在del释放锁之前做一个判断,验证当前的锁是不是自己加的锁。
至于具体的实现,可以在加锁的时候把当前的线程ID当做value,并在删除之前验证key对应的value是不是自己线程的ID。
加锁:
String threadId = Thread.currentThread().getId()
set(key,threadId ,30,NX)
doSomething.....
解锁:
if(threadId .equals(redisClient.get(key))){
del(key)
}但是,这样做又隐含了一个新的问题,if判断和释放锁是两个独立操作,不是原子性。
我们都是追求极致的程序员,所以这一块要用Lua脚本来实现:
String luaScript = 'if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end';
redisClient.eval(luaScript , Collections.singletonList(key), Collections.singletonList(threadId));
这样一来,验证和删除过程就是原子操作了。
3. 出现并发的可能性
还是刚才第二点所描述的场景,虽然我们避免了线程A误删掉key的情况,但是同一时间有A,B两个线程在访问代码块,仍然是不完美的。
怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续航”。
当过去了29秒,线程A还没执行完,这时候守护线程会执行expire指令,为这把锁“续命”20秒。守护线程从第29秒开始执行,每20秒执行一次。
当线程A执行完任务,会显式关掉守护线程。
另一种情况,如果节点1 忽然断电,由于线程A和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。
memcache实现分布式锁
首页top 10, 由数据库加载到memcache缓存n分钟
微博中名人的content cache, 一旦不存在会大量请求不能命中并加载数据库
需要执行多个IO操作生成的数据存在cache中, 比如查询db多次
问题
在大并发的场合,当cache失效时,大量并发同时取不到cache,会同一瞬间去访问db并回设cache,可能会给系统带来潜在的超负荷风险。我们曾经在线上系统出现过类似故障。
解决方法
if (memcache.get(key) == null) {
// 3 min timeout to avoid mutex holder crash
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}在load db之前先add一个mutex key, mutex key add成功之后再去做加载db, 如果add失败则sleep之后重试读取原cache数据。为了防止死锁,mutex key也需要设置过期时间。伪代码如下
Zookeeper实现分布式缓存
Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。
Znode分为四种类型:
- 1.
持久节点(PERSISTENT)
默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在 。
- 2.
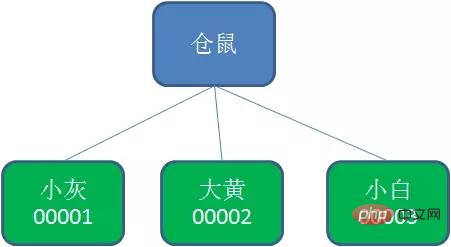
持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号:
- 3.
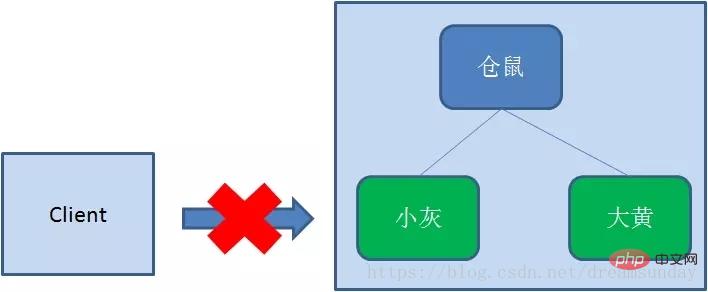
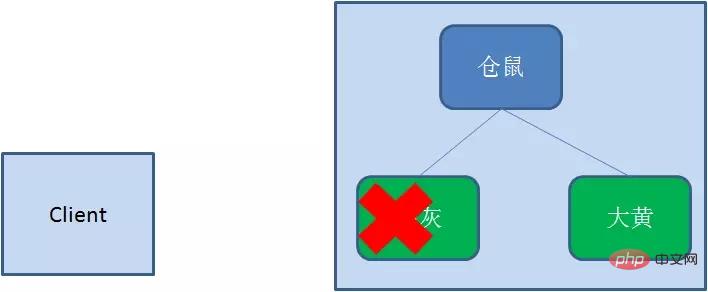
临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除:

- 4.
临时顺序节点(EPHEMERAL_SEQUENTIAL)
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
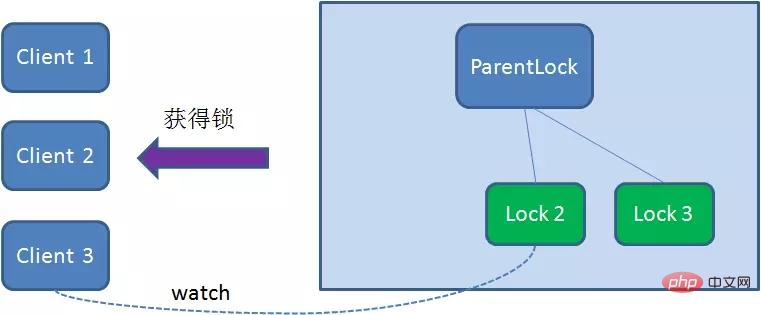
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤:
- 获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
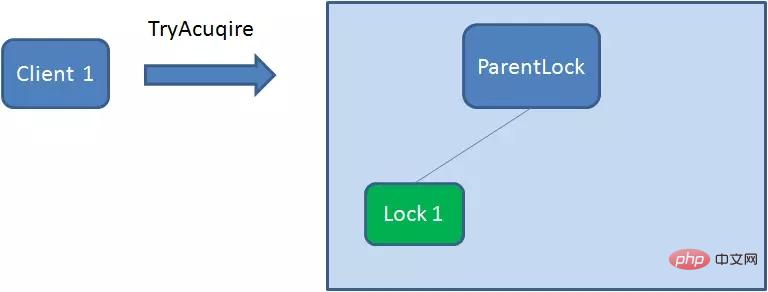
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
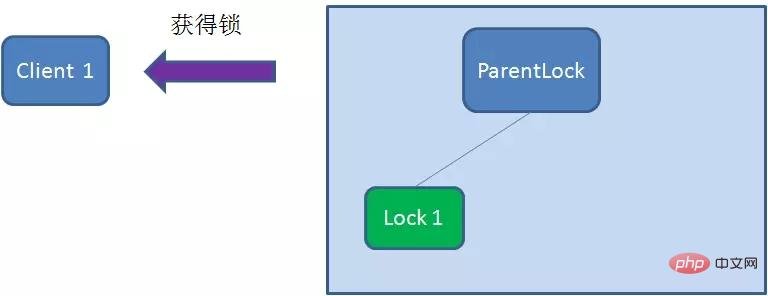
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
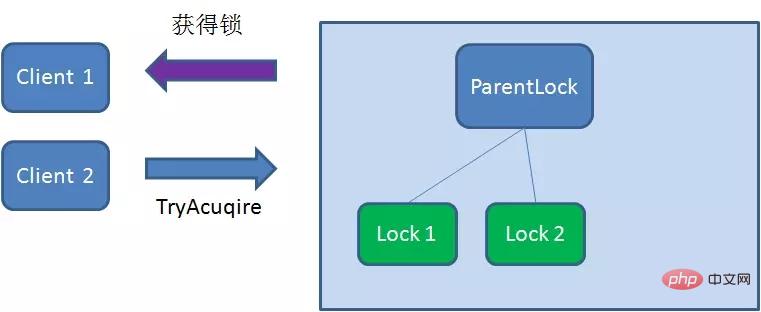
Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。

这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。
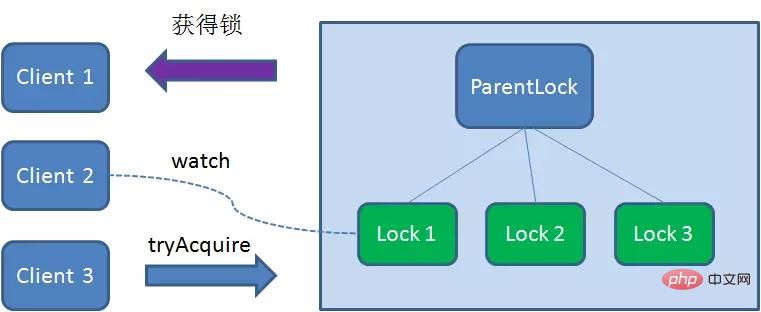
Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。
于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
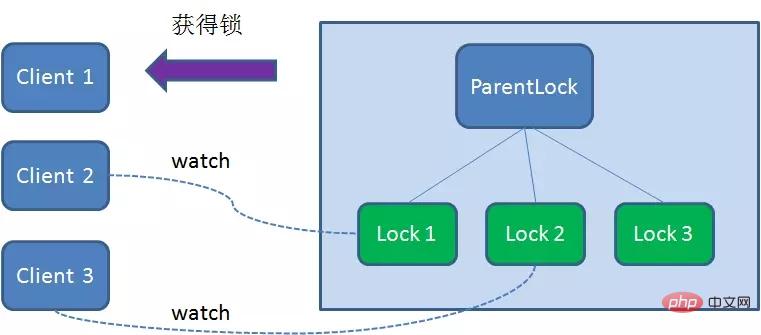
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列,很像是Java当中ReentrantLock所依赖的AQS(AbstractQueuedSynchronizer)。


- 释放锁
释放锁分为两种情况:
1.任务完成,客户端显示释放
当任务完成时,Client1会显示调用删除节点Lock1的指令。

2.任务执行过程中,客户端崩溃
获得锁的Client1在任务执行过程中,如果Duang的一声崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,相关联的节点Lock1会随之自动删除。

由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁。
同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Cient3就会接到通知。

最终,Client3成功得到了锁。


Zookeeper和Redis分布式锁的比较
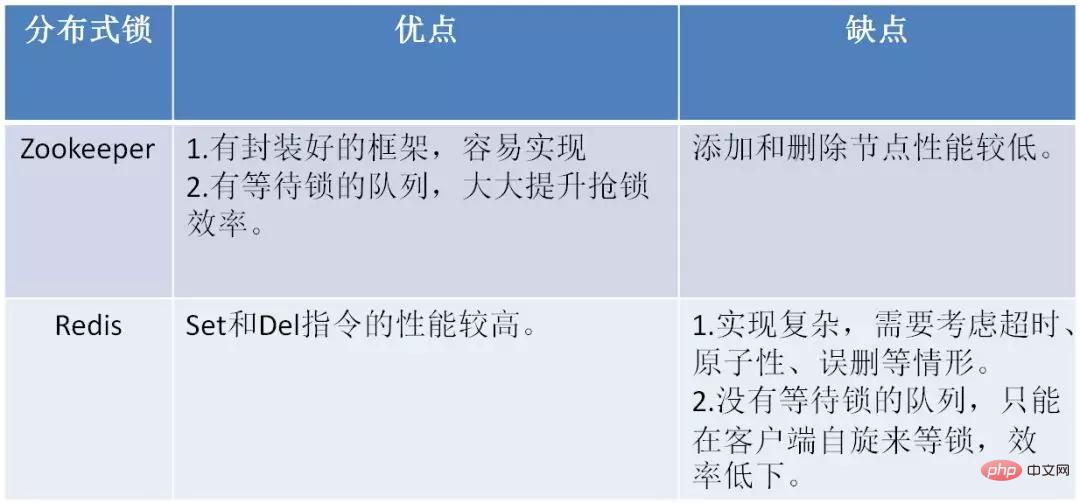
下面的表格总结了Zookeeper和Redis分布式锁的优缺点:

更多编程相关知识,请访问:编程入门!!
以上是Redis实现分布式锁需要注意什么?【注意事项总结】的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使
 redis指令怎么用
Apr 10, 2025 pm 08:45 PM
redis指令怎么用
Apr 10, 2025 pm 08:45 PM
使用 Redis 指令需要以下步骤:打开 Redis 客户端。输入指令(动词 键 值)。提供所需参数(因指令而异)。按 Enter 执行指令。Redis 返回响应,指示操作结果(通常为 OK 或 -ERR)。
 redis怎么使用单线程
Apr 10, 2025 pm 07:12 PM
redis怎么使用单线程
Apr 10, 2025 pm 07:12 PM
Redis 使用单线程架构,以提供高性能、简单性和一致性。它利用 I/O 多路复用、事件循环、非阻塞 I/O 和共享内存来提高并发性,但同时存在并发性受限、单点故障和不适合写密集型工作负载的局限性。
 redis怎么读源码
Apr 10, 2025 pm 08:27 PM
redis怎么读源码
Apr 10, 2025 pm 08:27 PM
理解 Redis 源码的最佳方法是逐步进行:熟悉 Redis 基础知识。选择一个特定的模块或功能作为起点。从模块或功能的入口点开始,逐行查看代码。通过函数调用链查看代码。熟悉 Redis 使用的底层数据结构。识别 Redis 使用的算法。
 redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 数据:使用 FLUSHALL 命令清除所有键值。使用 FLUSHDB 命令清除当前选定数据库的键值。使用 SELECT 切换数据库,再使用 FLUSHDB 清除多个数据库。使用 DEL 命令删除特定键。使用 redis-cli 工具清空数据。
 redis怎么查看所有的key
Apr 10, 2025 pm 07:15 PM
redis怎么查看所有的key
Apr 10, 2025 pm 07:15 PM
要查看 Redis 中的所有键,共有三种方法:使用 KEYS 命令返回所有匹配指定模式的键;使用 SCAN 命令迭代键并返回一组键;使用 INFO 命令获取键的总数。
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 redis怎么启动服务器
Apr 10, 2025 pm 08:12 PM
redis怎么启动服务器
Apr 10, 2025 pm 08:12 PM
启动 Redis 服务器的步骤包括:根据操作系统安装 Redis。通过 redis-server(Linux/macOS)或 redis-server.exe(Windows)启动 Redis 服务。使用 redis-cli ping(Linux/macOS)或 redis-cli.exe ping(Windows)命令检查服务状态。使用 Redis 客户端,如 redis-cli、Python 或 Node.js,访问服务器。
