

一起分析Redis热点数据问题解决方案

本篇文章给大家带来了关于Redis的相关知识,其中主要介绍了关于Redis热点key大Value解决方案的相关问题,下面一起来看一下,希望对大家有帮助。

推荐学习:Redis视频教程
关于 Redis 热点数据 & 大 key 大 value 问题也是容易被问的高阶问题,不如一次痛快点学完,让面试官无话可说,个人工作经验中,热点数据问题在工作中相比雪崩更容易遇到,只是大部分时候热点不够热,都会被提前告警解决,但这个问题一旦控制不了造成的线上问题也是足够让你今年绩效垫底了,废话不说进入正题。
正常情况下,Redis 集群中数据都是均匀分配到每个节点,请求也会均匀的分布到每个分片上,但在一些特殊场景中,比如外部爬虫、攻击、热点商品等,最典型的就是明星在微博上宣布离婚,吃瓜群众纷纷涌入留言,导致微博评论功能崩溃,这种短时间内某些 key 访问量过于大,对于这种相同的 key 会请求到同一台数据分片上,导致该分片负载较高成为瓶颈问题,导致雪崩等一系列问题。
1、面试官:你在项目中有没有遇到 Redis 热点数据问题,一般都是什么原因引起的?
问题分析:上次听群里大佬面试阿里 p7 就被问到这个问题,难度指数五颗星,对我等小白着实是加分项。
答:关于热点数据问题我有话要说,这个问题我早在刚刚学习使用 Redis 时就从已经意识到了,所以在使用时会刻意避免,坚决不会给自己挖坑,热点数据最大的问题会造成 Reids 集群负载不均衡(也就是数据倾斜)导致的故障,这些问题对于 Redis 集群都是致命打击。
先说说造成 Reids 集群负载不均衡故障的主要原因:
- 高访问量的 Key,也就是热 key,根据过去的维护经验一个 key 访问的 QPS 超过 1000 就要高度关注了,比如热门商品,热门话题等。
- 大 Value,有些 key 访问 QPS 虽然不高,但是由于 value 很大,造成网卡负载较大,网卡流量被打满,单台机器可能出现千兆 / 秒,IO 故障。
- 热点 Key + 大 Value 同时存在,服务器杀手。
那么热点 key 或大 Value 会造成哪些故障呢:
- 数据倾斜问题:大 Value 会导致集群不同节点数据分布不均匀,造成数据倾斜问题,大量读写比例非常高的请求都会落到同一个 redis server 上,该 redis 的负载就会严重升高,容易打挂。
- QPS 倾斜:分片上的 QPS 不均。
- 大 Value 会导致 Redis 服务器缓冲区不足,造成 get 超时。
- 由于 Value 过大,导致机房网卡流量不足。
- Redis 缓存失效导致数据库层被击穿的连锁反应。
2、面试官:真实项目中,那热点数据问题你是如何准确定位的呢?
答:这个问题的解决办法比较宽泛,要具体看不同业务场景,比如公司组织促销活动,那参加促销的商品肯定是有办法提前统计的,这种场景就可以通过预估法。对于突发事件,不确定因素,Redis 会自己监控热点数据。大概归纳下:
-
提前获知法:
根据业务,人肉统计 or 系统统计可能会成为热点的数据,如,促销活动商品,热门话题,节假日话题,纪念日活动等。 -
Redis 客户端收集法:
调用端通过计数的方式统计 key 的请求次数,但是无法预知 key 的个数,代码侵入性强。public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //从参数中获取key String key = analysis(args); //计数 counterKey(key); //ignore }登录后复制 -
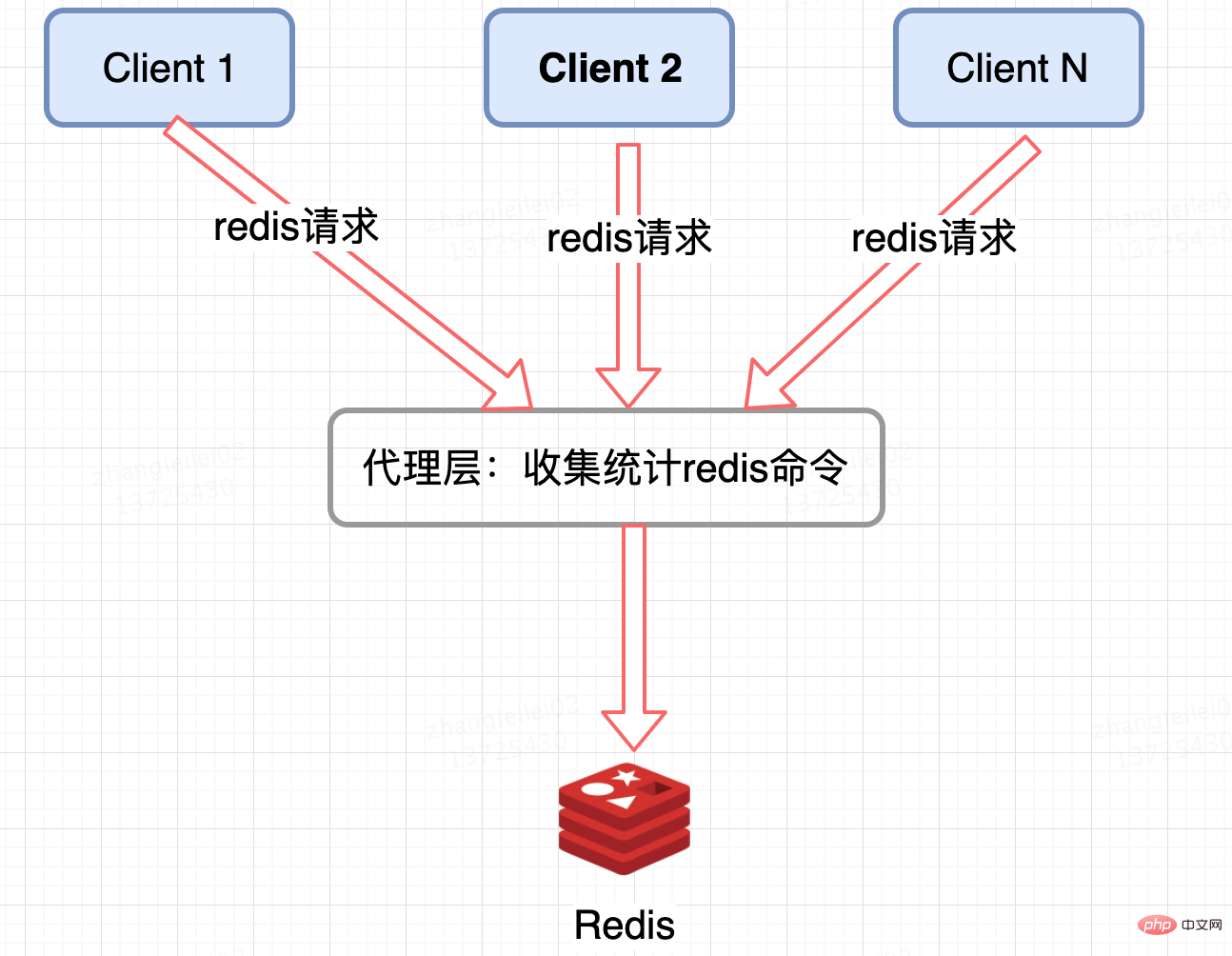
Redis 集群代理层统计:
像 Twemproxy,codis 这些基于代理的 Redis 分布式架构,统一的入口,可以在 Proxy 层做收集上报,但是缺点很明显,并非所有的 Redis 集群架构都有 proxy。
-
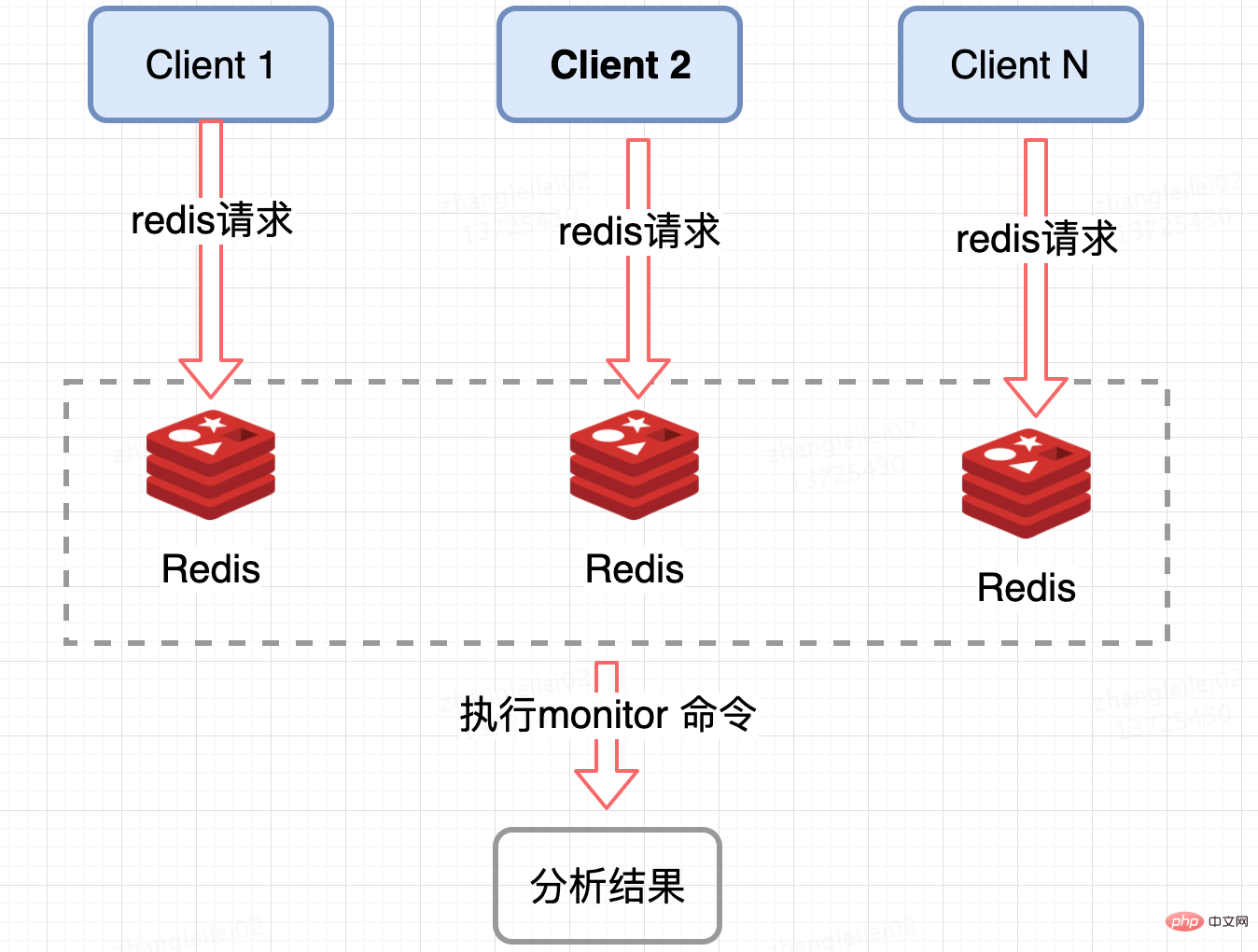
Redis 服务端收集:
监控 Redis 单个分片的 QPS,发现 QPS 倾斜到一定程度的节点进行 monitor,获取热点 key, Redis 提供了 monitor 命令,可以统计出一段时间内的某 Redis 节点上的所有命令,分析热点 key,在高并发条件下,会存在内存暴涨和 Redis 性能的隐患,所以此种方法适合在短时间内使用;同样只能统计一个 Redis 节点的热点 key,对于集群需要汇总统计,业务角度讲稍微麻烦一点。
以上为说的这 4 个方法都是现在业界比较常用的,方法,我通过学习 Redis 源码还有一个新的想法。第 5 种:修改 Redis 源码。
-
修改 Redis 源代码:(从读源码中想到的思路)
我发现 Redis4.0 为我们带来了许多新特性,其中便包括基于 LFU 的热点 key 发现机制,有了这个新特性,我们就可以在此基础上实现热点 key 的统计,这个只是我的个人思路。
面试官心理:小伙子还挺有想法,思路挺开阔,还打起了修改源码的注意,我都没这个野心。团队里就需要这样的人。
(发现问题,分析问题,解决问题,不等面试官发问,直接讲述如何解决热点数据问题,这才是核心内容)
3、如何解决热点数据问题
答:关于如何治理热点数据问题,解决这个问题主要从两个方面考虑,第一是数据分片,让压力均摊到集群的多个分片上,防止单个机器打挂,第二是迁移隔离。
概括总结:
-
key 拆分:
如果当前 key 的类型是一个二级数据结构,例如哈希类型。如果该哈希元素个数较多,可以考虑将当前 hash 进行拆分,这样该热点 key 可以拆分为若干个新的 key 分布到不同 Redis 节点上,从而减轻压力 -
迁移热点 key:
以 Redis Cluster 为例,可以将热点 key 所在的 slot 单独迁移到一个新的 Redis 节点上,这样这个热点 key 即使 QPS 很高,也不会影响到整个集群的其他业务,还可以定制化开发,热点 key 自动迁移到独立节点上,这种方案也较多副本。 -
热点 key 限流:
对于读命令我们可以通过迁移热点 key 然后添加从节点来解决,对于写命令我们可以通过单独针对这个热点 key 来限流。 -
增加本地缓存:
对于数据一致性不是那么高的业务,可以将热点 key 缓存到业务机器的本地缓存中,因为是业务端的本地内存中,省去了一次远程的 IO 调用。但是当数据更新时,可能会造成业务和 Redis 数据不一致。
面试官:你回答得很好,考虑得很全面。
4、面试官:关于 Redis 最后一个问题,Redis 支持丰富的数据类型,那么这些数据类型存储的大 Value 如何解决,线上有遇到这种情况吗?
问题分析:相比热点 key 大概念,大 Value 的概念比好好理解,由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,因为 Redis 是 Key - Value 结构数据库,大 value 就是单个 value 占用内存较大,对 Redis 集群造成最直接的影响就是数据倾斜。
答:(想难倒我?我可是有备而来。)
我先说说多大的 Value 算大,根据公司基础架构给出的经验值可做以下划分:
注:(经验值不是标准,都是根据集群运维人员长期观察线上 case 总结出来的)
- 大:string 类型 value > 10K,set、list、hash、zset 等集合数据类型中的元素个数 > 1000。
- 超大: string 类型 value > 100K,set、list、hash、zset 等集合数据类型中的元素个数 > 10000。
由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案:
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
以上是一起分析Redis热点数据问题解决方案的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使
 redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 数据:使用 FLUSHALL 命令清除所有键值。使用 FLUSHDB 命令清除当前选定数据库的键值。使用 SELECT 切换数据库,再使用 FLUSHDB 清除多个数据库。使用 DEL 命令删除特定键。使用 redis-cli 工具清空数据。
 redis指令怎么用
Apr 10, 2025 pm 08:45 PM
redis指令怎么用
Apr 10, 2025 pm 08:45 PM
使用 Redis 指令需要以下步骤:打开 Redis 客户端。输入指令(动词 键 值)。提供所需参数(因指令而异)。按 Enter 执行指令。Redis 返回响应,指示操作结果(通常为 OK 或 -ERR)。
 redis怎么使用锁
Apr 10, 2025 pm 08:39 PM
redis怎么使用锁
Apr 10, 2025 pm 08:39 PM
使用Redis进行锁操作需要通过SETNX命令获取锁,然后使用EXPIRE命令设置过期时间。具体步骤为:(1) 使用SETNX命令尝试设置一个键值对;(2) 使用EXPIRE命令为锁设置过期时间;(3) 当不再需要锁时,使用DEL命令删除该锁。
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 redis底层怎么实现
Apr 10, 2025 pm 07:21 PM
redis底层怎么实现
Apr 10, 2025 pm 07:21 PM
Redis 使用哈希表存储数据,支持字符串、列表、哈希表、集合和有序集合等数据结构。Redis 通过快照 (RDB) 和追加只写 (AOF) 机制持久化数据。Redis 使用主从复制来提高数据可用性。Redis 使用单线程事件循环处理连接和命令,保证数据原子性和一致性。Redis 为键设置过期时间,并使用 lazy 删除机制删除过期键。
 redis怎么读源码
Apr 10, 2025 pm 08:27 PM
redis怎么读源码
Apr 10, 2025 pm 08:27 PM
理解 Redis 源码的最佳方法是逐步进行:熟悉 Redis 基础知识。选择一个特定的模块或功能作为起点。从模块或功能的入口点开始,逐行查看代码。通过函数调用链查看代码。熟悉 Redis 使用的底层数据结构。识别 Redis 使用的算法。
 redis怎么做消息中间件
Apr 10, 2025 pm 07:51 PM
redis怎么做消息中间件
Apr 10, 2025 pm 07:51 PM
Redis 作为消息中间件,支持生产-消费模型,可持久化消息并保证可靠交付。使用 Redis 作为消息中间件可实现低延迟、可靠和可扩展的消息传递。
