

一起来聊聊Redis有什么优势和特点

本篇文章给大家带来了关于Redis的相关知识,其中主要介绍了关于redis的一些优势和特点,Redis 是一个开源的使用ANSI C语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式存储数据库,下面一起来看一下,希望对大家有帮助。

推荐学习:Redis视频教程
什么是redis
Remote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
Redis的特点:
- 内存数据库,速度快,也支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
- 支持事务
Redis的优势:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。(事务)
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
Memcache与Redis的区别都有哪些
- 存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,redis可以持久化其数据
- 数据支持类型 memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型 ,提供list,set,zset,hash等数据结构的存储
- 使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
- value 值大小不同:Redis 最大可以达到 512M;memcache 只有 1mb。
- redis的速度比memcached快很多
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
6.多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
**这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。**采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
那么为什么Redis是单线程的
我们首先要明白,上边的种种分析,都是为了营造一个Redis很快的氛围!官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。
Redis 数据类型及命令

1.字符串(String)
redis 127.0.0.1:6379> SET rediskey redis OK redis 127.0.0.1:6379> GET rediskey "redis"
2. 哈希(Hash)
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)
3. 列表(List)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
redis 127.0.0.1:6379> LPUSH rediskey redis (integer) 1 redis 127.0.0.1:6379> LPUSH rediskey mongodb (integer) 2 redis 127.0.0.1:6379> LPUSH rediskey mysql (integer) 3 redis 127.0.0.1:6379> LRANGE rediskey 0 10 1) "mysql" 2) "mongodb" 3) "redis"
4. 集合(Set)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
redis 127.0.0.1:6379> SADD rediskey redis (integer) 1 redis 127.0.0.1:6379> SADD rediskey mongodb (integer) 1 redis 127.0.0.1:6379> SADD rediskey mysql (integer) 1 redis 127.0.0.1:6379> SADD rediskey mysql (integer) 0 redis 127.0.0.1:6379> SMEMBERS rediskey 1) "mysql" 2) "mongodb" 3) "redis"
5. 有序集合(sorted set)
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
6. HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
实例
以下实例演示了 HyperLogLog 的工作过程:
//添加指定元素到 HyperLogLog 中。 redis 127.0.0.1:6379> PFADD rediskey "redis" 1) (integer) 1 redis 127.0.0.1:6379> PFADD rediskey "mongodb" 1) (integer) 1 redis 127.0.0.1:6379> PFADD rediskey "mysql" 1) (integer) 1 //添加指定元素到 HyperLogLog 中。 redis 127.0.0.1:6379> PFCOUNT rediskey (integer) 3
7. 发布订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
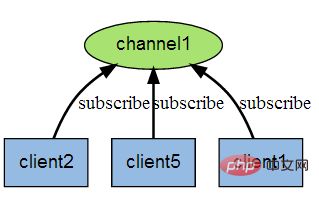
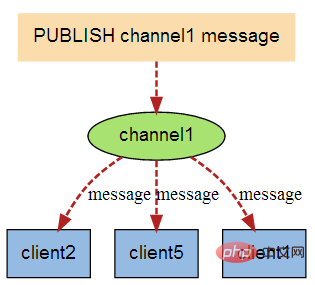
实例
以下实例演示了发布订阅是如何工作的,需要开启两个 redis-cli 客户端。
在我们实例中我们创建了订阅频道名为 runoobChat:
第一个 redis-cli 客户端
redis 127.0.0.1:6379> SUBSCRIBE runoobChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "runoobChat" 3) (integer) 1
现在,我们先重新开启个 redis 客户端,然后在同一个频道 runoobChat 发布两次消息,订阅者就能接收到消息。
第二个 redis-cli 客户端
redis 127.0.0.1:6379> PUBLISH runoobChat "Redis PUBLISH test" (integer) 1 redis 127.0.0.1:6379> PUBLISH runoobChat "Learn redis by runoob.com" (integer) 1 # 订阅者的客户端会显示如下消息 1) "message" 2) "runoobChat" 3) "Redis PUBLISH test" 1) "message" 2) "runoobChat" 3) "Learn redis by runoob.com"
gif 演示如下:
- 开启本地 Redis 服务,开启两个 redis-cli 客户端。
- 在第一个 redis-cli 客户端输入 SUBSCRIBE runoobChat,意思是订阅
runoobChat频道。 - 在第二个 redis-cli 客户端输入 PUBLISH runoobChat “Redis PUBLISH test” 往 runoobChat 频道发送消息,这个时候在第一个 redis-cli 客户端就会看到由第二个 redis-cli 客户端发送的测试消息。

8. 事务
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It’s important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
9. 脚本
Redis 脚本使用 Lua 解释器来执行脚本。 Redis 2.6 版本通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。
redis 127.0.0.1:6379> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"10 GEO
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
Redis GEO 操作方法有:
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania" (integer) 2 redis> GEODIST Sicily Palermo Catania "166274.1516" redis> GEORADIUS Sicily 15 37 100 km 1) "Catania" redis> GEORADIUS Sicily 15 37 200 km 1) "Palermo" 2) "Catania" redis>
11 Redis Stream
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
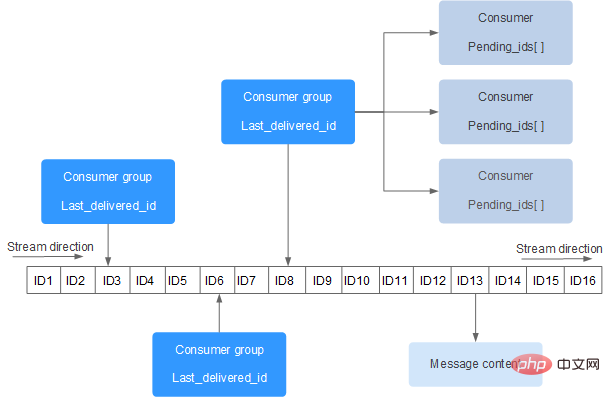
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
上图解析:
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
Redis 管道技术
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 管道技术
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
推荐学习:Redis视频教程
以上是一起来聊聊Redis有什么优势和特点的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Windows11安装10.0.22000.100跳出0x80242008错误解决办法
May 08, 2024 pm 03:50 PM
Windows11安装10.0.22000.100跳出0x80242008错误解决办法
May 08, 2024 pm 03:50 PM
1、启动【开始】菜单,输入【cmd】,右键点击【命令提示符】,选择以【管理员身份】运行。2、依次输入下面命令(可小心复制贴上):SCconfigwuauservstart=auto,按回车SCconfigbitsstart=auto,按回车SCconfigcryptsvcstart=auto,按回车SCconfigtrustedinstallerstart=auto,按回车SCconfigwuauservtype=share,按回车netstopwuauserv,按回车netstopcryptS
 剖析 PHP 函数瓶颈,提升执行效率
Apr 23, 2024 pm 03:42 PM
剖析 PHP 函数瓶颈,提升执行效率
Apr 23, 2024 pm 03:42 PM
PHP函数瓶颈导致性能低下,通过以下步骤解决:定位瓶颈函数,使用性能分析工具。缓存结果以减少重新计算。并行处理任务,提高执行效率。优化字符串连接,使用内建函数替代。利用内建函数代替自定义函数。
 Golang API缓存策略与优化
May 07, 2024 pm 02:12 PM
Golang API缓存策略与优化
May 07, 2024 pm 02:12 PM
GolangAPI中的缓存策略可提升性能和减轻服务器负载,常用策略有:LRU、LFU、FIFO和TTL。优化技巧包括:选择合适的缓存存储、分级缓存、失效管理以及进行监控和调整。实操案例中,使用LRU缓存优化从数据库获取用户信息的API,可从缓存中快速检索数据,否则从数据库中获取后再更新缓存。
 PHP开发中的缓存机制与应用实战
May 09, 2024 pm 01:30 PM
PHP开发中的缓存机制与应用实战
May 09, 2024 pm 01:30 PM
在PHP开发中,缓存机制通过将经常访问的数据临时存储在内存或磁盘中来提升性能,从而减少数据库访问次数。缓存类型主要包括内存、文件和数据库缓存。PHP中可以使用内置函数或第三方库实现缓存,如cache_get()和Memcache。常见的实战应用包括缓存数据库查询结果以优化查询性能,以及缓存页面输出以加快渲染速度。缓存机制有效改善网站响应速度,提升用户体验并降低服务器负载。
 PHP数组分页中如何使用Redis缓存?
May 01, 2024 am 10:48 AM
PHP数组分页中如何使用Redis缓存?
May 01, 2024 am 10:48 AM
使用Redis缓存可以大幅优化PHP数组分页的性能。可通过以下步骤实现:安装Redis客户端。连接到Redis服务器。创建缓存数据,将每页数据存储到Redis哈希中,密钥为"page:{page_number}"。从缓存中获取数据,避免对大型数组进行昂贵的操作。
 Win11英文21996怎么升级到简体中文22000_Win11英文21996升级到简体中文22000的方法
May 08, 2024 pm 05:10 PM
Win11英文21996怎么升级到简体中文22000_Win11英文21996升级到简体中文22000的方法
May 08, 2024 pm 05:10 PM
首先你需要将系统语言设置为简体中文显示并重启。当然,之前已经改为简体中文显示语言的直接跳过这一步即可。下面开始操作注册表,regedit.exe,左侧导航栏或上方地址栏直接定位到HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage,然后将其中的InstallLanguage键值、Default键值全部修改为0804(如果想改为英文的en-us,需要先将系统显示语言设置为en-us,重启系统再全部修改为0409)进行到这里必须重启系
 navicat能连接redis吗
Apr 23, 2024 pm 05:12 PM
navicat能连接redis吗
Apr 23, 2024 pm 05:12 PM
是的,Navicat 可以连接 Redis,它允许用户管理键、查看值、执行命令、监视活动和诊断问题。要连接 Redis,请在 Navicat 中选择“Redis”连接类型,并输入服务器详细信息。
 Win11下载的更新文件怎么找_Win11下载的更新文件位置分享
May 08, 2024 am 10:34 AM
Win11下载的更新文件怎么找_Win11下载的更新文件位置分享
May 08, 2024 am 10:34 AM
1、首先双击打开桌面上的【此电脑】图标。2、接着双击鼠标左键进入【c盘】,系统文件一般都会自动存放在c盘。3、然后再c盘中找到【windows】文件夹,同样双击进入。4、进入【windows】文件夹后,找到其中的【SoftwareDistribution】文件夹。5、进入之后再找到【download】文件夹,里面存放的就是所有的win11下载更新文件了。6、如果我们想要删除这些文件的话,直接在这个文件夹中将他们删除就可以了。
