

详解node如何实现多进程?如何部署node项目?

node如何实现多进程?如何部署node项目?下面本篇文章带大家掌握Node.js 多进程模型和项目部署的相关知识,希望对大家有所帮助!

昨天有小伙伴问 express 项目该如何部署。于是整理了这篇文章,主要讲述如何部署一个基于 nodejs 开发的服务端程序,供有需要的朋友们参考。
文章包含几个部分:
- 线程和进程
- node.js 实现多进程
- 服务器安装 Node.js 环境
- 使用 PM2 管理 Node.js 项目
- 使用 Nginx 实现接口服务的代理转发
进程 VS 线程
进程
进程(process)是计算机操作系统分配和调度任务的基本单位。打开任务管理器,可以看到其实在计算机的后台运行着非常多的程序,每个程序都是一个进程。

现代浏览器基本都是多进程架构的,以 Chrome 浏览器为例,打开“更多工具” - “任务管理器”,就能看到当前浏览器的进程信息,其中一个页面就是一个进程,除此之外,还有网路进程,GPU 进程等。

多进程的架构,得以保证应用更稳定的运行。还是以浏览器为例,假如所有的程序都运行在一个进程中,如果网络出现故障,或者页面渲染出错问题,都会导致整个浏览器的崩溃。通过多进程的架构,哪怕网络进程崩溃了,它不会影响到已有页面的展示,最坏也就是暂时不能接入网络。
线程
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。举一个例子,一个程序好比是一家公司,下设多个部门,就是若干个进程;每个部门的通力合作使得公司正常运行,而线程就是员工,是具体干活的人。
我们都知道 JavaScript 是一门单线程语言。这么设计是因为早期 JS 主要用来编写脚本程序,负责实现页面的交互效果。如果设计成多线程语言,一是没有必要,二是多个线程共同操作一个 dom 节点,那么浏览器该听谁的?当然随着技术的发展,现在的 JS 也支持了多线程,不过仅用来处理一些和 dom 操作无关的逻辑。
单进程存在的问题
单线程单进程带来一个严重的问题,一个运行中的 node.js 程序,一旦主线程挂掉,那么这个进程也就挂掉了,整个应用也就随之挂掉。再者,现代计算机大都是多核 CPU,四核八线程,八核十六线程,都是很常见的设备了。而 node.js 作为一个单进程的程序,白白浪费掉了多核 CPU 的性能。
针对这种情况,我们需要一个合适的多进程模型,将一个单进程的 node.js 程序变为多进程的架构。
Node.js 的多进程实现
Node.js 实现多进程架构有两种常用方案,都是使用原生模块,分别是 child_process 模块和 cluster 模块。
child_process
child_process 是 node.js 的内置模块,看名字也能猜到它负责的是和子进程有关的事。
我们不再细说该模块的具体用法,实际上它大概只有六七个方法,还是非常容易理解的。我们使用其中的一个 fork 方法来演示如何实现多进程以及多进程之间的通信。
先看下准备好的演示案例的目录结构:

我们使用 http 模块创建了一个 http server,当有 /sum 请求进来时,会通过 child_process 模块创建一个子进程,并通知子进程执行计算的逻辑,同时父进程也要监听子进程发来的消息:
// child_process.js
const http = require('http')
const { fork } = require('child_process')
const server = http.createServer((req, res) => {
if (req.url == '/sum') {
// fork 方法接收一个模块路径,然后开启一个子进程,将模块在子进程中运行
// childProcess 表示创建的子进程
let childProcess = fork('./sum.js')
// 发消息给子进程
childProcess.send('子进程开始计算')
// 父进程中监听子进程的消息
childProcess.on('message', (data) => {
res.end(data + '')
})
// 监听子进程的关闭事件
childProcess.on('close', () => {
// 子进程正常退出和报错挂掉,都会走到这里
console.log('子进程关闭')
childProcess.kill()
})
// 监听子进程的错误事件
childProcess.on('error', () => {
console.log('子进程报错')
childProcess.kill()
})
}
if (req.url == '/hello') {
res.end('hello')
}
// 模拟父进程报错
if (req.url == '/error') {
throw new Error('父进程出错')
res.end('hello')
}
})
server.listen(3000, () => {
console.log('Server is running on 3000')
})sum.js 用来模拟子进程要执行的任务。子进程监听父进程发来的消息,处理计算任务,然后将结果发送给父进程:
// sum.js
function getSum() {
let sum = 0
for (let i = 0; i < 10000 * 1000 * 100; i++) {
sum += 1
}
return sum
}
// process 是 node.js 中一个全局对象,表示当前进程。在这里也就是子进程。
// 监听主进程发来的消息
process.on('message', (data) => {
console.log('主进程的消息:', data)
const result = getSum()
// 将计算结果发送给父进程
process.send(result)
})打开终端,运行命令 node 1.child_process:

访问浏览器:

接着来模拟子进程报错的情况:
// sum.js
function getSum() {
// ....
}
// 子进程运行5s后,模拟进程挂掉
setTimeout(() => {
throw new Error('报错')
}, 1000 * 5)
process.on('message', (data) => {
// ...
})再次访问浏览器,5秒之后观察控制台:

子进程已经挂掉了,然后再访问另一个 url :/hello,

可见,父进程依然能正确处理请求,说明子进程报错,并不会影响父进程的运行。
接着我们来模拟父进程报错的场景,注释掉 sum.js 模块的模拟报错,然后重启服务,浏览器访问 /error:

发现父进程挂掉后,整个 node.js 程序自动退出了,服务完全崩溃,没有挽回的余地。
可见,通过 child_process 的 fork 方法实现 node.js 的多进程架构并不复杂。进程间的通信主要通过 send 和 on 方法,从这个命名上也能知道,其底层应该是一个发布订阅模式。
但是它存在一个严重的问题,虽然子进程不影响父进程,但是一旦父进程出错挂掉,所有的子进程会被”一锅端掉“ 。所以,这种方案适用于将一些复杂耗时的运算,fork 出一个单独的子进程去做。更准确的来说,这种用法是用来代替多线程的实现,而非多进程。
cluster
使用 child_process 模块实现多进程,貌似不堪大用。所以一般更推荐使用 cluster 模块来实现 node.js 的多进程模型。
cluster,集群的意思,这个名词相信大家都不陌生。打个比方,以前公司只有一个前台,有时候太忙就没办法及时接待访客。现在公司分配了4个前台,即使有三个都在忙,也还有一个能接待新来的访客。集群大致也就是这个意思,对于同一件事,合理的分配给不同的人去干,以此来保证这件事能做到最好。
cluster 模块的使用也比较简单。如果当前进程是主进程,则根据 CPU 的核数创建合适数量的子进程,同时监听子进程的 exit 事件,有子进程退出,就重新 fork 新的子进程。如果不是子进程,则进行实际业务的处理。
const http = require('http')
const cluster = require('cluster')
const cpus = require('os').cpus()
if (cluster.isMaster) {
// 程序启动时首先走到这里,根据 CPU 的核数,创建出多个子进程
for (let i = 0; i < cpus.length; i++) {
// 创建出一个子进程
cluster.fork()
}
// 当任何一个子进程挂掉后,cluster 模块会发出'exit'事件。此时通过再次调用 fork 来来重启进程。
cluster.on('exit', () => {
cluster.fork()
})
} else {
// fork 方法执行创建子进程,同时会再次执行该模块,此时逻辑就会走到这里
const server = http.createServer((req, res) => {
console.log(process.pid)
res.end('ok')
})
server.listen(3000, () => {
console.log('Server is running on 3000', 'pid: ' + process.pid)
})
}启动服务:

可以看到,cluster 模块创建出了非常多的子进程,好像是每个子进程都运行着同一个web服务。
需要注意的是,此时并非是这些子进程共同监听同一个端口。端口的监听依然是由 createServer 方法创建的 server 去负责,将请求转发给各个子进程。
我们编写一个请求脚本,来请求上面的服务,看下效果。
// request.js
const http = require('http')
for (let i = 0; i < 1000; i++) {
http.get('http://localhost:3000')
}http 模块不仅可以创建 http server,还能用来发送 http 请求。Axios支持浏览器和服务器环境,在服务器端就是使用 http 模块发送 http 请求。
使用 node 命令执行该文件,再看下原来的控制台:

打印出了具体处理请求的不同子进程的进程ID。
这就是通过 cluster 模块实现的 nodd.js 的多进程架构。
当然,我们在部署 node.js 项目时不会这么干巴巴的写和使用 cluster 模块。有一个非常好用的工具,叫做 PM2,它是一个基于 cluster 模块实现的进程管理工具。在后面的章节中会介绍它的基本用法。
小结
到此为止,我们花了一部分篇幅介绍 node.js 中多进程的知识,其实仅是想要交代下为什么需要使用 pm2 来管理 node.js 应用。本文由于篇幅有限,再加上描述不够准确/详尽,仅做简单介绍。如果是第一次接触这一块内容的朋友,可能没有太明白,也不打紧,后面会再出一篇更细节的文章。
部署实践
准备一个 express 项目
本文已经准备了一个使用 express 开发的示例程序,点此访问。
它主要实现了一个接口服务,当访问 /api/users 时,使用 mockjs 模拟了10条用户数据,返回一个用户列表。同时会开启一个定时器,来模拟报错的情况:
const express = require('express')
const Mock = require('mockjs')
const app = express()
app.get("/api/users", (req, res) => {
const userList = Mock.mock({
'userList|10': [{
'id|+1': 1,
'name': '@cname',
'email': '@email'
}]
})
setTimeout(()=> {
throw new Error('服务器故障')
}, 5000)
res.status(200)
res.json(userList)
})
app.listen(3000, () => {
console.log("服务启动: 3000")
})本地测试一下,在终端中执行命令:
node server.js
打开浏览器,访问用户列表接口:

五秒钟后,服务器会挂掉:
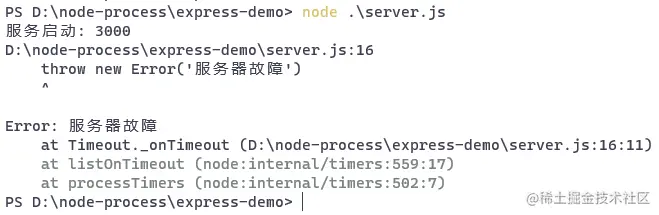
后面我们使用 pm2 来管理应用后,就可以解决这个问题。
讨论:express 项目是否需要打包
通常完成一个 vue/react 项目后,我们都会先执行打包,再进行发布。其实前端项目要进行打包,主要是因为程序最终的运行环境是浏览器,而浏览器存在各种兼容性问题和性能问题,比如:
- 高级语法的不支持,需要将 ES6+ 编译为 ES5 语法
- 不能识别
.vue,.jsx,.ts文件,需要编译 - 减少代码体积,节省带宽资源,提高资源加载速度
- ......
而使用 express.js 或者 koa.js 开发的项目,并不存在这些问题。并且,Node.js 采用 CommonJS 模块化规范,有缓存的机制;同时,只有当模块在被用到时,才会被导入。如果进行打包,打包成一个文件,其实就浪费了这个优势。所以针对 node.js 项目,并不需要打包。
服务器安装 Node.js
本文以 CentOS 系统为例进行演示。
NVM
为了方便切换 node 的版本,我们使用 nvm 来管理 node。
Nvm(Node Version Manager) ,就是 Node.js 的版本管理工具。通过它,可以让 node 在多个版本之间进行任意切换,避免了需要切换版本时反复的下载和安装的操作。
Nvm的官方仓库是 github.com/nvm-sh/nvm。因为它的安装脚本存放在 githubusercontent 站点上,经常访问不了。所以我在 gitee 上新建了它的镜像仓库,这样就能从 gitee 上访问到它的安装脚本了。
通过 curl 命令下载安装脚本,并使用 bash 执行脚本,会自动完成 nvm 的安装工作:
# curl -o- https://gitee.com/hsyq/nvm/raw/master/install.sh | bash
当安装完成之后,我们再打开一个新的窗口,来使用 nvm :
[root@ecs-221238 ~]# nvm -v0.39.1
可以正常打印版本号,说明 nvm 已经安装成功了。
安装 Node.js
现在就可以使用 nvm 来安装和管理 node 了。
查看可用的 node 版本:
# nvm ls-remote
安装 node:
# nvm install 18.0.0
查看已经安装的 node 版本:
[root@ecs-221238 ~]# nvm list -> v18.0.0 default -> 18.0.0 (-> v18.0.0) iojs -> N/A (default) unstable -> N/A (default) node -> stable (-> v18.0.0) (default) stable -> 18.0 (-> v18.0.0) (default)
选择一个版本进行使用:
# nvm use 18.0.0
需要注意的一点,在 Windows 上使用 nvm 时,需要使用管理员权限执行 nvm 命令。在 CentOS 上,我默认使用 root 用户登录的,因而没有出现问题。大家在使用时遇到了未知错误,可以搜索一下解决方案,或者尝试下是否是权限导致的问题。
在安装 node 的时候,会自动安装 npm。查看 node 和 npm 的版本号:
[root@ecs-221238 ~]# node -v v18.0.0 [root@ecs-221238 ~]# npm -v 8.6.0
默认的 npm 镜像源是官方地址:
[root@ecs-221238 ~]# npm config get registry https://registry.npmjs.org/
切换为国内淘宝的镜像源:
[root@ecs-221238 ~]# npm config set registry https://registry.npmmirror.com
到此为止,服务器就已经安装好 node 环境和配置好 npm 了。
项目上传到服务器
方法有很多,或者从 Github / GitLab / Gitee 仓库中下载到服务器中,或者本地通过 ftp 工具上传。步骤很简单,不再演示。
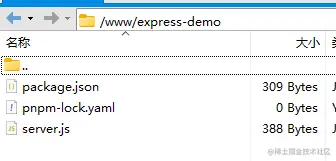
演示项目放到了 /www 目录 下:
服务器开放端口
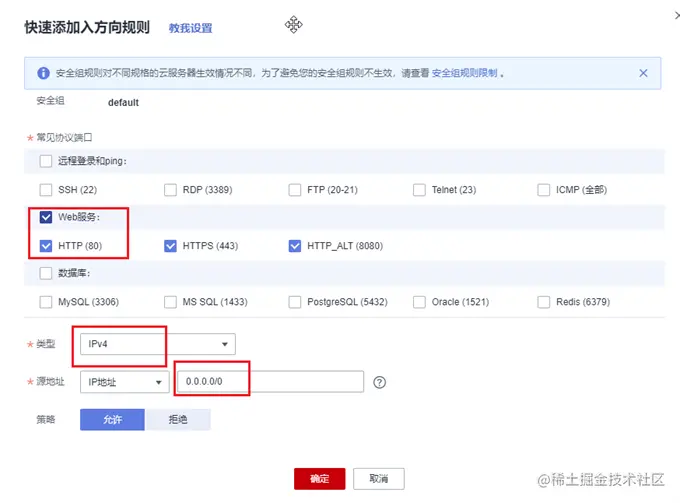
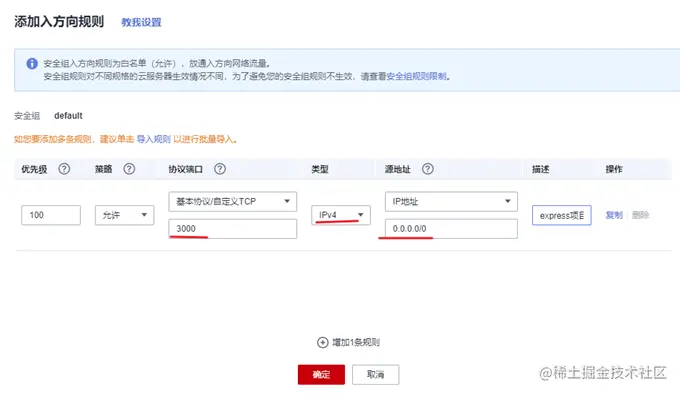
一般云服务器仅开放了 22 端口用于远程登录。而常用的80,443等端口并未开放。另外,我们准备好的 express 项目运行在3000端口上。所以需要先到云服务器的控制台中,找到安全组,添加几条规则,开放80和3000端口。
使用 PM2 管理应用
在开发阶段,我们可以使用 nodemon 来做实时监听和自动重启,提高开发效率。在生产环境,就需要祭出大杀器—PM2了。
基本使用
首先全局安装 pm2:
# npm i -g pm2
执行 pm2 -v 命令查看是否安装成功:
[root@ecs-221238 ~]# pm2 -v5.2.0
切换到项目目录,先把依赖装上:
cd /www/express-demo npm install
然后使用 pm2 命令来启动应用。
pm2 start app.js -i max // 或者 pm2 start server.js -i 2
PM2 管理应用有 fork 和 cluster 两种模式。在启动应用时,通过使用 -i 参数来指定实例的个数,会自动开启 cluster 模式。此时就具备了负载均衡的能力。
-i :instance,实例的个数。可以写具体的数字,也可以配置成 max,
PM2会自动检查可用的CPU的数量,然后尽可能多地启动进程。
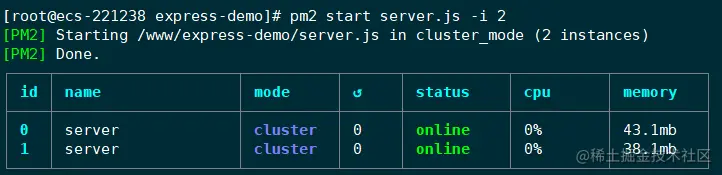
此时应用就启动好了。PM2 会以守护进程的形式管理应用,这个表格展示了应用运行的一些信息,比如运行状态,CPU使用率,内存使用率等。
在本地的浏览器中访问接口:

Cluster 模式是一个多进程多实例的模型,请求进来后会分配给其中一个进程处理。正如前面我们看过的 cluster 模块的用法一样,由于 pm2 的守护,即使某个进程挂掉了,也会立刻重启该进程。
回到服务器终端,执行 pm2 logs 命令,查看下 pm2 的日志:
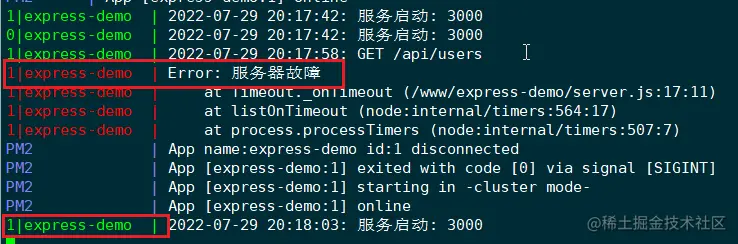
可见,id 为1的应用实例挂掉了,pm2 会立刻重启该实例。注意,这里的 id 是应用实例的 id,并非进程 id。
到这里,一个 express 项目的简单部署就完成了。通过使用 pm2 工具,基本能保证我们的项目可以稳定可靠的运行。
PM2 常用命令小结
这里整理了一些 pm2 工具常用的命令,可供查询参考。
# Fork模式 pm2 start app.js --name app # 设定应用的名字为 app # Cluster模式 # 使用负载均衡启动4个进程 pm2 start app.js -i 4 # 将使用负载均衡启动4个进程,具体取决于可用的 CPU pm2 start app.js -i 0 # 等同于上面命令的作用 pm2 start app.js -i max # 给 app 扩展额外的3个进程 pm2 scale app +3 # 将 app 扩展或者收缩到2个进程 pm2 scale app 2 # 查看应用状态 # 展示所有进程的状态 pm2 list # 用原始 JSON 格式打印所有进程列表 pm2 jlist # 用美化的 JSON 打印所有进程列表 pm2 prettylist # 展示特定进程的所有信息 pm2 describe 0 # 使用仪表盘监控所有进程 pm2 monit # 日志管理 # 实时展示所有应用的日志 pm2 logs # 实时展示 app 应用的日志 pm2 logs app # 使用json格式实时展示日志,不输出旧日志,只输出新产生的日志 pm2 logs --json # 应用管理 # 停止所有进程 pm2 stop all # 重启所有进程 pm2 restart all # 停止指定id的进程 pm2 stop 0 # 重启指定id的进程 pm2 restart 0 # 删除id为0进程 pm2 delete 0 # 删除所有的进程 pm2 delete all
每一条命令都可以亲自尝试一下,看看效果。
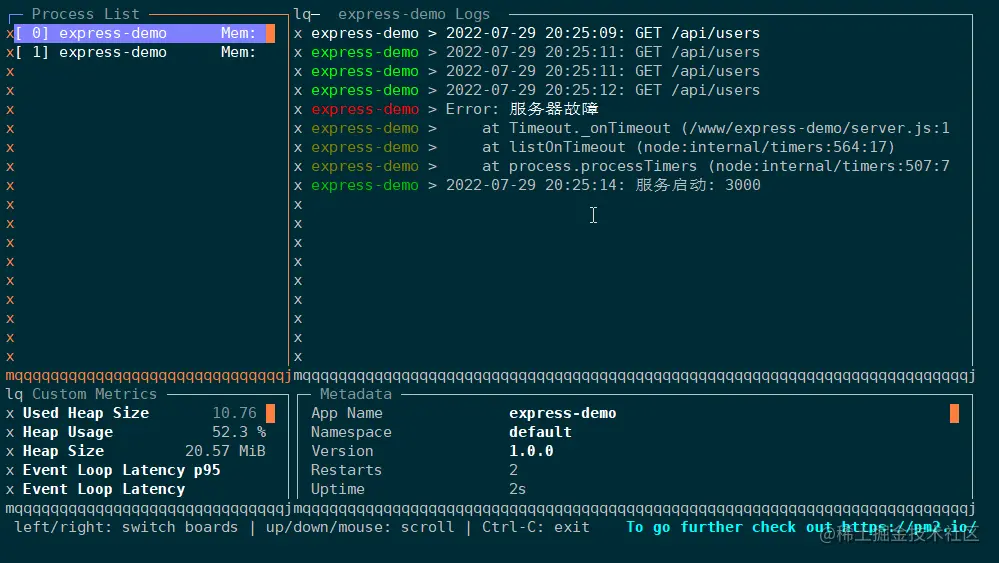
这里特别展示下 monit 命令,它可以在终端中启动一个面板,实时展示应用的运行状态,通过上下箭头可以切换 pm2 管理的所有应用:
进阶:使用 pm2 配置文件
PM2 的功能十分强大,远不止上面的这几个命令。在真实的项目部署中,可能还需要配置日志文件,watch 模式,环境变量等等。如果每次都手敲命令是十分繁琐的,所以 pm2 提供了配置文件来管理和部署应用。
可以通过以下命令来生成一份配置文件:
[root@ecs-221238 express-demo]# pm2 init simple File /www/express-demo/ecosystem.config.js generated
会生成一个ecosystem.config.js 文件:
module.exports = {
apps : [{
name : "app1",
script : "./app.js"
}]
}也可以自己创建一个配置文件,比如 app.config.js:
const path = require('path')
module.exports = {
// 一份配置文件可以同时管理多个 node.js 应用
// apps 是一个数组,每一项都是一个应用的配置
apps: [{
// 应用名称
name: "express-demo",
// 应用入口文件
script: "./server.js",
// 启动应用的模式, 有两种:cluster和fork,默认是fork
exec_mode: 'cluster',
// 创建应用实例的数量
instances: 'max',
// 开启监听,当文件变化后自动重启应用
watch: true,
// 忽略掉一些目录文件的变化。
// 由于把日志目录放到了项目路径下,一定要将其忽略,否则应用启动产生日志,pm2 监听到变化就会重启,重启又产生日志,就会进入死循环
ignore_watch: [
"node_modules",
"logs"
],
// 错误日志存放路径
err_file: path.resolve(__dirname, 'logs/error.log'),
// 打印日志存放路径
out_file: path.resolve(__dirname, 'logs/out.log'),
// 设置日志文件中每条日志前面的日期格式
log_date_format: "YYYY-MM-DD HH:mm:ss",
}]
}让 pm2 使用配置文件来管理 node 应用:
pm2 start app.config.js
现在 pm2 管理的应用,会将日志放到项目目录下(默认是放到 pm2 的安装目录下),并且能监听文件的变化,自动重启服务。
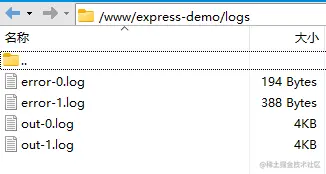
更多有用的配置可以参考 PM2 官方文档,点此访问。
Nginx 代理转发接口
上面我们直接将 nodejs 项目的3000端口暴露了出去。一般我们都会使用 nginx 做一个代理转发,只对外暴露 80 端口。
安装 Nginx
首先服务器中需要安装 nginx ,有三种方式:
- 下载源码编译安装
- 使用 docker 安装
- 使用包管理工具安装
我这里的系统是 CentOS 8,已经更换了可用的 yum 源,可以直接安装 nginx。如果你的操作系统为 CentOS 7 或者其他发行版,可以搜索适合的安装方法。
使用 yum 安装:
# yum install -y nginx
然后启动 nginx:
# systemctl start nginx
打开浏览器访问服务器地址,可以看到 nginx 默认的主页:
配置接口转发
为项目新建一个配置文件:
# vim /etc/nginx/conf.d/express.conf
监听80端口,将所有请求转发给服务器本地的3000端口的程序处理:
server {
listen 80;
server_name ironfan.site;
location / {
proxy_pass http://localhost:3000;
}
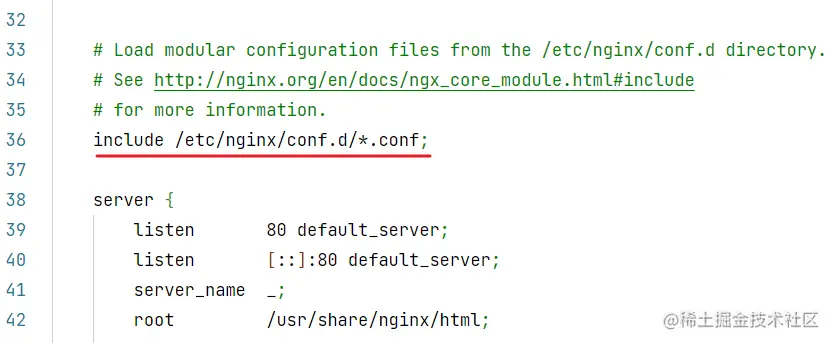
}conf 目录下的配置文件,会被主配置文件 /etc/nginx/nginx.conf 加载:
修改完配置文件,一定要重启服务:
# systemctl restart nginx
然后本地打开浏览器,去掉原来的3000端口号,直接访问完整的 url:
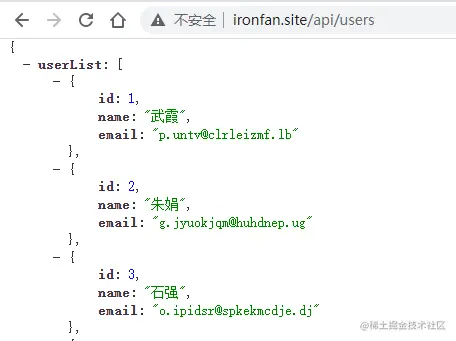
到这里,就完成了接口转发的配置。从用户的角度出发,这个也叫反向代理。
总结
首先我们比较系统的讲解了为何需要在 node.js 项目中开启多进程,以及两种实现方式:
-
child_process模块的fork方法 -
cluster 模块的fork方法
之后,又讲解了如何在 Linux 服务器中安装 node 环境,以及部署一个 node.js 项目的大致流程,并着重介绍了 pm2 的使用:
上传项目到服务器中
安装项目依赖
使用 pm2 管理应用
最后,讲解了使用 nginx 实现接口的代理转发,将用户请求转发到本地的3000端口的服务。
至此,我们完成了本文的目标,将一个 express 项目部署到服务器,并能稳定可靠的运行。
下篇文章,我们会使用 Github Actions 实现 CI/CD,让项目的部署更加便捷高效。
本文演示代码,已上传至 Github,点击访问。
更多node相关知识,请访问:nodejs 教程!
以上是详解node如何实现多进程?如何部署node项目?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 nvm 怎么删除node
Dec 29, 2022 am 10:07 AM
nvm 怎么删除node
Dec 29, 2022 am 10:07 AM
nvm删除node的方法:1、下载“nvm-setup.zip”并将其安装在C盘;2、配置环境变量,并通过“nvm -v”命令查看版本号;3、使用“nvm install”命令安装node;4、通过“nvm uninstall”命令删除已安装的node即可。
 node项目中如何使用express来处理文件的上传
Mar 28, 2023 pm 07:28 PM
node项目中如何使用express来处理文件的上传
Mar 28, 2023 pm 07:28 PM
怎么处理文件上传?下面本篇文章给大家介绍一下node项目中如何使用express来处理文件的上传,希望对大家有所帮助!
 Golang函数的多进程之间共享内存的应用方法
May 17, 2023 pm 12:52 PM
Golang函数的多进程之间共享内存的应用方法
May 17, 2023 pm 12:52 PM
Golang作为一门高并发编程语言,其内置的协程机制和多线程操作实现了轻量级的多任务处理。然而,在多进程处理的场景下,不同进程之间的通信和共享内存成为了程序开发的关键问题。本文将介绍在Golang中实现多进程之间共享内存的应用方法。一、Golang中多进程的实现方式在Golang中,可以通过多种方式实现多进程并发处理,其中包括fork、os.Process、
 深入浅析Node的进程管理工具“pm2”
Apr 03, 2023 pm 06:02 PM
深入浅析Node的进程管理工具“pm2”
Apr 03, 2023 pm 06:02 PM
本篇文章给大家分享Node的进程管理工具“pm2”,聊聊为什么需要pm2、安装和使用pm2的方法,希望对大家有所帮助!
 Pi Node教学:什么是Pi节点?如何安装和设定Pi Node?
Mar 05, 2025 pm 05:57 PM
Pi Node教学:什么是Pi节点?如何安装和设定Pi Node?
Mar 05, 2025 pm 05:57 PM
PiNetwork节点详解及安装指南本文将详细介绍PiNetwork生态系统中的关键角色——Pi节点,并提供安装和配置的完整步骤。Pi节点在PiNetwork区块链测试网推出后,成为众多先锋积极参与测试的重要环节,为即将到来的主网发布做准备。如果您还不了解PiNetwork,请参考Pi币是什么?上市价格多少?Pi用途、挖矿及安全性分析。什么是PiNetwork?PiNetwork项目始于2019年,拥有其专属加密货币Pi币。该项目旨在创建一个人人可参与
 使用Angular和Node进行基于令牌的身份验证
Sep 01, 2023 pm 02:01 PM
使用Angular和Node进行基于令牌的身份验证
Sep 01, 2023 pm 02:01 PM
身份验证是任何Web应用程序中最重要的部分之一。本教程讨论基于令牌的身份验证系统以及它们与传统登录系统的区别。在本教程结束时,您将看到一个用Angular和Node.js编写的完整工作演示。传统身份验证系统在继续基于令牌的身份验证系统之前,让我们先看一下传统的身份验证系统。用户在登录表单中提供用户名和密码,然后点击登录。发出请求后,通过查询数据库在后端验证用户。如果请求有效,则使用从数据库中获取的用户信息创建会话,然后在响应头中返回会话信息,以便将会话ID存储在浏览器中。提供用于访问应用程序中受
 npm node gyp失败怎么办
Dec 29, 2022 pm 02:42 PM
npm node gyp失败怎么办
Dec 29, 2022 pm 02:42 PM
npm node gyp失败是因为“node-gyp.js”跟“Node.js”版本不匹配,其解决办法:1、通过“npm cache clean -f”清除node缓存;2、通过“npm install -g n”安装n模块;3、通过“n v12.21.0”命令安装“node v12.21.0”版本即可。
 什么是单点登录系统?用nodejs怎么实现?
Feb 24, 2023 pm 07:33 PM
什么是单点登录系统?用nodejs怎么实现?
Feb 24, 2023 pm 07:33 PM
什么是单点登录系统?用nodejs怎么实现?下面本篇文章给大家介绍一下使用node实现单点登录系统的方法,希望对大家有所帮助!
